 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π$-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
May 14, 2026The rise of personal assistant agents, e.g., OpenClaw, highlights the growing potential of large language models to support users across everyday life and work. A core challenge in these settings is proactive assistance, since users often begin with underspecified requests and leave important needs, constraints, or preferences unstated. However, existing benchmarks rarely evaluate whether agents can identify and act on such hidden intents before they are explicitly stated, especially in sustained multi-turn interactions where user needs emerge gradually. To address this gap, we introduce $π$-Bench, a benchmark for proactive assistance comprising 100 multi-turn tasks across 5 domain-specific user personas. By incorporating hidden user intents, inter-task dependencies, and cross-session continuity, $π$-Bench evaluates agents' ability to anticipate and address user needs over extended interactions, jointly measuring proactivity and task completion in long-horizon trajectories that better reflect real-world use. Experiments show (1) proactive assistance remains challenging, (2) a clear distinction between task completion and proactivity, and (3) the value of prior interaction for proactive intent resolution in later tasks.
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
May 13, 2026Recent progress in reasoning models has substantially advanced long-horizon mathematical and scientific problem solving, with several systems now reaching gold-medal-level performance on International Mathematical Olympiad (IMO) and International Physics Olympiad (IPhO) problems. In this paper, we introduce a simple and unified recipe for converting a post-trained reasoning backbone into a rigorous olympiad-level solver. The recipe first uses a reverse-perplexity curriculum for SFT to instill rigorous proof-search and self-checking behaviors, then scales these behaviors through a two-stage RL pipeline that progresses from RL with verifiable rewards to more delicate proof-level RL, and finally boosts solving performance with test-time scaling. Applying this recipe, we train a 30B-A3B backbone with SFT on around 340K sub-8K-token trajectories followed by 200 RL steps. The resulting model, SU-01, supports stable reasoning on difficult problems with trajectories exceeding 100K tokens, while achieving gold-medal-level performance on mathematical and physical olympiad competitions, including IMO 2025/USAMO 2026 and IPhO 2024/2025. It also demonstrates strong generalization of scientific reasoning to domains beyond mathematics and physics.
Teaching Thinking Models to Reason with Tools: A Full-Pipeline Recipe for Tool-Integrated Reasoning
May 07, 2026Tool-integrated reasoning (TIR) offers a direct way to extend thinking models beyond the limits of text-only reasoning. Paradoxically, we observe that tool-enabled evaluation can degrade reasoning performance even when the strong thinking models make almost no actual tool calls. In this paper, we investigate how to inject natural tool-use behavior into a strong thinking model without sacrificing its no-tool reasoning ability, and present a comprehensive TIR recipe. We highlight that (i) the effectiveness of TIR supervised fine-tuning (SFT) hinges on the learnability of teacher trajectories, which should prioritize problems inherently suited for tool-augmented solutions; (ii) controlling the proportion of tool-use trajectories could mitigate the catastrophic forgetting of text-only reasoning capacity; (iii) optimizing for pass@k and response length instead of training loss could maximize TIR SFT gains while preserving headroom for reinforcement learning (RL) exploration; (iv) a stable RL with verifiable rewards (RLVR) stage, built upon suitable SFT initialization and explicit safeguards against mode collapse, provides a simple yet remarkably effective solution. When applied to Qwen3 thinking models at 4B and 30B scales, our recipe yields models that achieve state-of-the-art performance in a wide range of benchmarks among open-source models, such as 96.7% and 99.2% on AIME 2025 for 4B and 30B, respectively.
SymphonyGen: 3D Hierarchical Orchestral Generation with Controllable Harmony Skeleton
Apr 28, 2026Generating symphonic music requires simultaneously managing high-level structural form and dense, multi-track orchestration. Existing symbolic models often struggle with a "complexity-control imbalance", in which scaling bottlenecks limit long-term granular steerability. We present SymphonyGen, a 3D hierarchical framework for contemporary cinematic orchestration. SymphonyGen employs a cascading decoder architecture that decomposes the Bar, Track, and Event axes, improving computational efficiency and scalability over conventional 1D or 2D models. We introduce "short-score" conditioning via a beat-quantized multi-voice harmony skeleton, enabling outline control while preserving textural diversity. The model is further refined using Group Relative Policy Optimization (GRPO) with a cross-modal audio-perceptual reward, aligning symbolic output with modern acoustic expectations. Additionally, we implement a dissonance-averse sampling algorithm to suppress unintended tonal clashes during inference. Objective evaluations show that both reinforcement learning and dissonance-averse sampling effectively enhance harmonic cleanliness while maintaining melodic expression. Subjective evaluations demonstrate that SymphonyGen outperforms baselines in musicality and preference for orchestral music generation. Demo page: https://symphonygen.github.io/
Mira-Embeddings-V1: Domain-Adapted Semantic Reranking for Recruitment via LLM-Synthesized Data
Apr 20, 2026Candidate sourcing for recruiters is best viewed as a two-stage retrieval and reranking pipeline with recall as the primary objective under a limited review budget. An upstream production retriever first returns a candidate shortlist for each job description (JD), and our goal is to rerank that shortlist so that qualified candidates appear as high as possible. We present mira-embeddings-v1, a semantic reranking system for the recruitment domain that reshapes the embedding space with LLM-synthesized training data and corrects boundary confusions with a lightweight reranking head. Starting from real JDs, we build a five-stage prompt pipeline to generate diverse positive and hard negative samples that sculpt the semantic space from multiple angles. We then apply a two-round LoRA adaptation: JD--JD contrastive training followed by JD--CV triplet alignment on a heterogeneous text dataset. Importantly, these gains require no large-scale manually labeled industrial training pairs: a modest set of real JDs is expanded into supervision through LLM synthesis. Finally, a BoundaryHead MLP reranks the Top-K results to distinguish between roles that share the same title but differ in scope. On a local pool of 300 real JDs with candidates from an upstream production retriever, mira-embeddings-v1 improves Recall@50 from 68.89% (baseline) to 77.55% while lifting Precision@10 from 35.77% to 39.62%. On a supportive global pool over 44,138 candidates judged by a Qwen3-32B rubric, it achieves Recall@200 of 0.7047 versus 0.5969 for the baseline. These results show that LLM-synthesized supervision with boundary-aware reranking yields robust gains without a heavy cross-encoder.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
New Skills or Sharper Primitives? A Probabilistic Perspective on the Emergence of Reasoning in RLVR
Feb 09, 2026Whether Reinforcement Learning with Verifiable Rewards (RLVR) endows Large Language Models (LLMs) with new capabilities or merely elicits latent traces remains a central debate. In this work, we align with the former view, proposing a probabilistic framework where capability is defined by instance-level solvability. We hypothesize that the emergence of complex reasoning can be driven by sharpening atomic step probabilities, which enables models to overcome the exponential decay of success rates inherent in multi-step reasoning chains. Utilizing the Algebrarium framework, we train models exclusively on single-step operations and evaluate their performance on unseen multi-step tasks. Our empirical results confirm that: (1) RLVR incentivizes the exploration of previously inaccessible solution paths by amplifying the model's existing skills; (2) composite performance is strictly governed by the joint probability of atomic steps, evidenced by high Pearson correlation coefficients ($ρ\in [0.69, 0.96]$); and (3) RLVR, acting as a global optimizer, can cause specific skills to be sacrificed to maximize aggregate reward. Our work offers a novel explanation for emergent abilities in RLVR, suggesting that the iterative optimization of solvable problems enables models to develop the capabilities to tackle previously unsolvable scenarios.
Characterizing, Evaluating, and Optimizing Complex Reasoning
Feb 09, 2026Large Reasoning Models (LRMs) increasingly rely on reasoning traces with complex internal structures. However, existing work lacks a unified answer to three fundamental questions: (1) what defines high-quality reasoning, (2) how to reliably evaluate long, implicitly structured reasoning traces, and (3) how to use such evaluation signals for reasoning optimization. To address these challenges, we provide a unified perspective. (1) We introduce the ME$^2$ principle to characterize reasoning quality along macro- and micro-level concerning efficiency and effectiveness. (2) Built on this principle, we model reasoning traces as directed acyclic graphs (DAGs) and develop a DAG-based pairwise evaluation method, capturing complex reasoning structures. (3) Based on this method, we construct the TRM-Preference dataset and train a Thinking Reward Model (TRM) to evaluate reasoning quality at scale. Experiments show that thinking rewards serve as an effective optimization signal. At test time, selecting better reasoning leads to better outcomes (up to 19.3% gain), and during RL training, thinking rewards enhance reasoning and performance (up to 3.9% gain) across diverse tasks.
Evaluating Parameter Efficient Methods for RLVR
Dec 30, 2025We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies (\textit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction (\textit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Oct 21, 2025

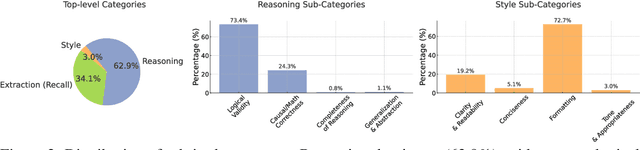
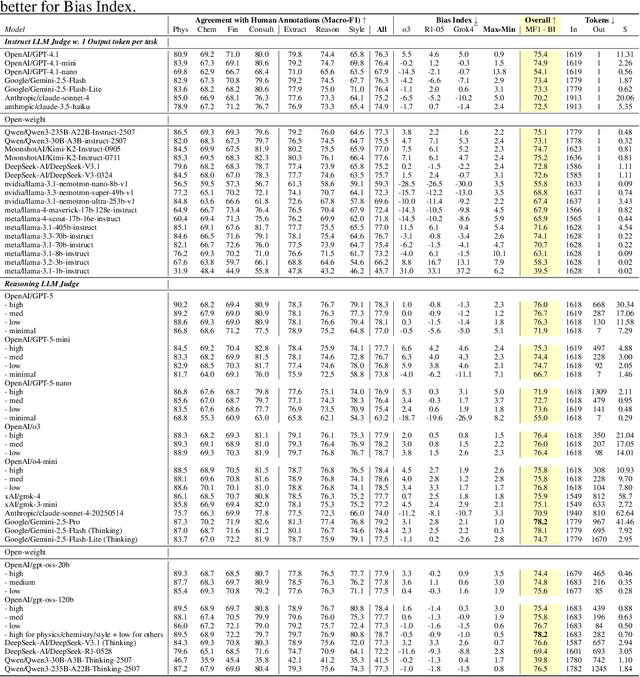
Evaluating progress in large language models (LLMs) is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9\% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench