 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Mixed Training: Scaling Parametric Knowledge Acquisition Beyond RAG
Mar 24, 2026Synthetic data augmentation helps language models learn new knowledge in data-constrained domains. However, naively scaling existing synthetic data methods by training on more synthetic tokens or using stronger generators yields diminishing returns below the performance of RAG. To break the RAG ceiling, we introduce Synthetic Mixed Training, which combines synthetic QAs and synthetic documents. This leverages their complementary training signals, and enables log-linear improvements as both synthetic data volume and generator strength increase. This allows the model to outperform RAG by a 2.6\% relative gain on QuaLITY, a long-document reading comprehension benchmark. In addition, we introduce Focal Rewriting, a simple technique for synthetic document generation that explicitly conditions document generation on specific questions, improving the diversity of synthetic documents and yielding a steeper log-linear scaling curve. On QuaLITY, our final recipe trains a Llama 8B model that outperforms RAG by 4.4\% relatively. Across models and benchmarks (QuaLITY, LongHealth, FinanceBench), our training enables models to beat RAG in five of six settings, outperforms by 2.6\%, and achieves a 9.1\% gain when combined with RAG.
iGRPO: Self-Feedback-Driven LLM Reasoning
Feb 09, 2026Large Language Models (LLMs) have shown promise in solving complex mathematical problems, yet they still fall short of producing accurate and consistent solutions. Reinforcement Learning (RL) is a framework for aligning these models with task-specific rewards, improving overall quality and reliability. Group Relative Policy Optimization (GRPO) is an efficient, value-function-free alternative to Proximal Policy Optimization (PPO) that leverages group-relative reward normalization. We introduce Iterative Group Relative Policy Optimization (iGRPO), a two-stage extension of GRPO that adds dynamic self-conditioning through model-generated drafts. In Stage 1, iGRPO samples multiple exploratory drafts and selects the highest-reward draft using the same scalar reward signal used for optimization. In Stage 2, it appends this best draft to the original prompt and applies a GRPO-style update on draft-conditioned refinements, training the policy to improve beyond its strongest prior attempt. Under matched rollout budgets, iGRPO consistently outperforms GRPO across base models (e.g., Nemotron-H-8B-Base-8K and DeepSeek-R1 Distilled), validating its effectiveness on diverse reasoning benchmarks. Moreover, applying iGRPO to OpenReasoning-Nemotron-7B trained on AceReason-Math achieves new state-of-the-art results of 85.62\% and 79.64\% on AIME24 and AIME25, respectively. Ablations further show that the refinement wrapper generalizes beyond GRPO variants, benefits from a generative judge, and alters learning dynamics by delaying entropy collapse. These results underscore the potential of iterative, self-feedback-based RL for advancing verifiable mathematical reasoning.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact Verifiers
Jun 16, 2025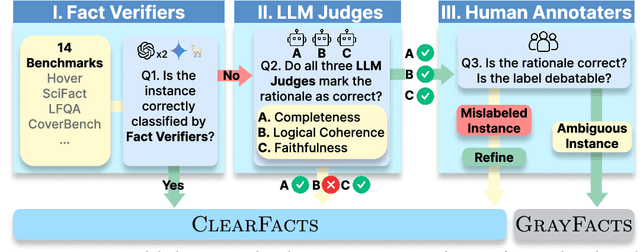

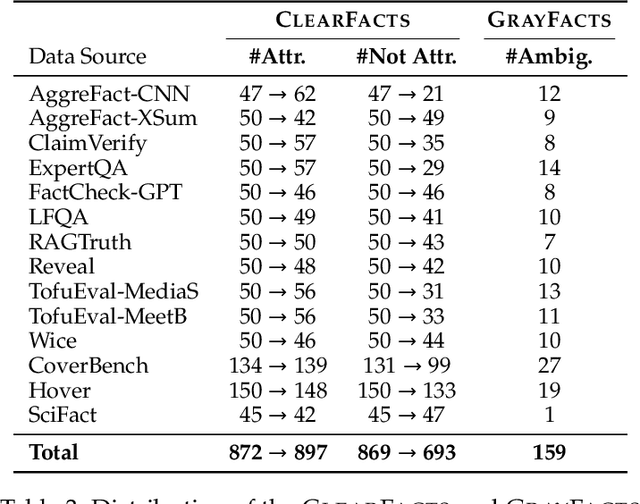
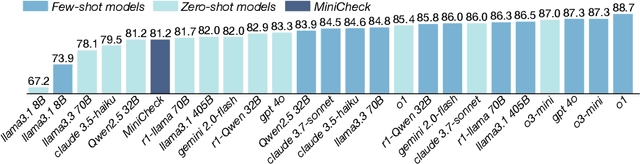
Fact verification is essential for ensuring the reliability of LLM applications. In this study, we evaluate 12 pre-trained LLMs and one specialized fact-verifier, including frontier LLMs and open-weight reasoning LLMs, using a collection of examples from 14 fact-checking benchmarks. We share three findings intended to guide future development of more robust fact verifiers. First, we highlight the importance of addressing annotation errors and ambiguity in datasets, demonstrating that approximately 16\% of ambiguous or incorrectly labeled data substantially influences model rankings. Neglecting this issue may result in misleading conclusions during comparative evaluations, and we suggest using a systematic pipeline utilizing LLM-as-a-judge to help identify these issues at scale. Second, we discover that frontier LLMs with few-shot in-context examples, often overlooked in previous works, achieve top-tier performance. We therefore recommend future studies include comparisons with these simple yet highly effective baselines. Lastly, despite their effectiveness, frontier LLMs incur substantial costs, motivating the development of small, fine-tuned fact verifiers. We show that these small models still have room for improvement, particularly on instances that require complex reasoning. Encouragingly, we demonstrate that augmenting training with synthetic multi-hop reasoning data significantly enhances their capabilities in such instances. We release our code, model, and dataset at https://github.com/just1nseo/verifying-the-verifiers
Subtle Risks, Critical Failures: A Framework for Diagnosing Physical Safety of LLMs for Embodied Decision Making
May 26, 2025



Large Language Models (LLMs) are increasingly used for decision making in embodied agents, yet existing safety evaluations often rely on coarse success rates and domain-specific setups, making it difficult to diagnose why and where these models fail. This obscures our understanding of embodied safety and limits the selective deployment of LLMs in high-risk physical environments. We introduce SAFEL, the framework for systematically evaluating the physical safety of LLMs in embodied decision making. SAFEL assesses two key competencies: (1) rejecting unsafe commands via the Command Refusal Test, and (2) generating safe and executable plans via the Plan Safety Test. Critically, the latter is decomposed into functional modules, goal interpretation, transition modeling, action sequencing, enabling fine-grained diagnosis of safety failures. To support this framework, we introduce EMBODYGUARD, a PDDL-grounded benchmark containing 942 LLM-generated scenarios covering both overtly malicious and contextually hazardous instructions. Evaluation across 13 state-of-the-art LLMs reveals that while models often reject clearly unsafe commands, they struggle to anticipate and mitigate subtle, situational risks. Our results highlight critical limitations in current LLMs and provide a foundation for more targeted, modular improvements in safe embodied reasoning.
Prismatic Synthesis: Gradient-based Data Diversification Boosts Generalization in LLM Reasoning
May 26, 2025Effective generalization in language models depends critically on the diversity of their training data. Yet existing diversity metrics often fall short of this goal, relying on surface-level heuristics that are decoupled from model behavior. This motivates us to ask: What kind of diversity in training data actually drives generalization in language models -- and how can we measure and amplify it? Through large-scale empirical analyses spanning over 300 training runs, carefully controlled for data scale and quality, we show that data diversity can be a strong predictor of generalization in LLM reasoning -- as measured by average model performance on unseen out-of-distribution benchmarks. We introduce G-Vendi, a metric that quantifies diversity via the entropy of model-induced gradients. Despite using a small off-the-shelf proxy model for gradients, G-Vendi consistently outperforms alternative measures, achieving strong correlation (Spearman's $\rho \approx 0.9$) with out-of-distribution (OOD) performance on both natural language inference (NLI) and math reasoning tasks. Building on this insight, we present Prismatic Synthesis, a framework for generating diverse synthetic data by targeting underrepresented regions in gradient space. Experimental results show that Prismatic Synthesis consistently improves model performance as we scale synthetic data -- not just on in-distribution test but across unseen, out-of-distribution benchmarks -- significantly outperforming state-of-the-art models that rely on 20 times larger data generator than ours. For example, PrismMath-7B, our model distilled from a 32B LLM, outperforms R1-Distill-Qwen-7B -- the same base model trained on proprietary data generated by 671B R1 -- on 6 out of 7 challenging benchmarks.
DUSK: Do Not Unlearn Shared Knowledge
May 21, 2025Large language models (LLMs) are increasingly deployed in real-world applications, raising concerns about the unauthorized use of copyrighted or sensitive data. Machine unlearning aims to remove such 'forget' data while preserving utility and information from the 'retain' set. However, existing evaluations typically assume that forget and retain sets are fully disjoint, overlooking realistic scenarios where they share overlapping content. For instance, a news article may need to be unlearned, even though the same event, such as an earthquake in Japan, is also described factually on Wikipedia. Effective unlearning should remove the specific phrasing of the news article while preserving publicly supported facts. In this paper, we introduce DUSK, a benchmark designed to evaluate unlearning methods under realistic data overlap. DUSK constructs document sets that describe the same factual content in different styles, with some shared information appearing across all sets and other content remaining unique to each. When one set is designated for unlearning, an ideal method should remove its unique content while preserving shared facts. We define seven evaluation metrics to assess whether unlearning methods can achieve this selective removal. Our evaluation of nine recent unlearning methods reveals a key limitation: while most can remove surface-level text, they often fail to erase deeper, context-specific knowledge without damaging shared content. We release DUSK as a public benchmark to support the development of more precise and reliable unlearning techniques for real-world applications.
NEMOTRON-CROSSTHINK: Scaling Self-Learning beyond Math Reasoning
Apr 15, 2025Large Language Models (LLMs) have shown strong reasoning capabilities, particularly when enhanced through Reinforcement Learning (RL). While prior work has successfully applied RL to mathematical reasoning -- where rules and correctness are well-defined -- generalizing these methods to broader reasoning domains remains challenging due to limited data, the lack of verifiable reward structures, and diverse task requirements. In this work, we propose NEMOTRON-CROSSTHINK, a framework that systematically incorporates multi-domain corpora, including both synthetic and real-world question-answer pairs, into RL training to improve generalization across diverse reasoning tasks. NEMOTRON-CROSSTHINK addresses key challenges by (1) incorporating data from varied sources spanning STEM, humanities, social sciences, etc.; (2) applying structured templates (e.g., multiple-choice and open-ended) to control answer-space complexity; (3) filtering for verifiable answers; and (4) optimizing data blending strategies that utilizes data from multiple sources effectively. Our approach enables scalable and verifiable reward modeling beyond mathematics and demonstrates improved accuracies on both math (MATH-500: +30.1%, AMC23:+27.5%) and non-math reasoning benchmarks (MMLU-PRO: +12.8%, GPQA-DIAMOND: +11.3%, AGIEVAL: +15.1%, SUPERGPQA: +3.8%). Moreover, NEMOTRON-CROSSTHINK exhibits significantly improved response efficiency -- using 28% fewer tokens for correct answers -- highlighting more focused and effective reasoning. Through NEMOTRON-CROSSTHINK, we demonstrate that integrating multi-domain, multi-format data in RL leads to more accurate, efficient, and generalizable LLMs.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Retro-Search: Exploring Untaken Paths for Deeper and Efficient Reasoning
Apr 06, 2025



Large reasoning models exhibit remarkable reasoning capabilities via long, elaborate reasoning trajectories. Supervised fine-tuning on such reasoning traces, also known as distillation, can be a cost-effective way to boost reasoning capabilities of student models. However, empirical observations reveal that these reasoning trajectories are often suboptimal, switching excessively between different lines of thought, resulting in under-thinking, over-thinking, and even degenerate responses. We introduce Retro-Search, an MCTS-inspired search algorithm, for distilling higher quality reasoning paths from large reasoning models. Retro-Search retrospectively revises reasoning paths to discover better, yet shorter traces, which can then lead to student models with enhanced reasoning capabilities with shorter, thus faster inference. Our approach can enable two use cases: self-improvement, where models are fine-tuned on their own Retro-Search-ed thought traces, and weak-to-strong improvement, where a weaker model revises stronger model's thought traces via Retro-Search. For self-improving, R1-distill-7B, fine-tuned on its own Retro-Search-ed traces, reduces the average reasoning length by 31.2% while improving performance by 7.7% across seven math benchmarks. For weak-to-strong improvement, we retrospectively revise R1-671B's traces from the OpenThoughts dataset using R1-distill-32B as the Retro-Search-er, a model 20x smaller. Qwen2.5-32B, fine-tuned on this refined data, achieves performance comparable to R1-distill-32B, yielding an 11.3% reduction in reasoning length and a 2.4% performance improvement compared to fine-tuning on the original OpenThoughts data. Our work counters recently emergent viewpoints that question the relevance of search algorithms in the era of large reasoning models, by demonstrating that there are still opportunities for algorithmic advancements, even for frontier models.