 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
Jan 26, 2026Large language model (LLM)-based agents are increasingly deployed in e-commerce shopping. To perform thorough, user-tailored product searches, agents should interpret personal preferences, engage in multi-turn dialogues, and ultimately retrieve and discriminate among highly similar products. However, existing research has yet to provide a unified simulation environment that consistently captures all of these aspects, and always focuses solely on evaluation benchmarks without training support. In this paper, we introduce ShopSimulator, a large-scale and challenging Chinese shopping environment. Leveraging ShopSimulator, we evaluate LLMs across diverse scenarios, finding that even the best-performing models achieve less than 40% full-success rate. Error analysis reveals that agents struggle with deep search and product selection in long trajectories, fail to balance the use of personalization cues, and to effectively engage with users. Further training exploration provides practical guidance for overcoming these weaknesses, with the combination of supervised fine-tuning (SFT) and reinforcement learning (RL) yielding significant performance improvements. Code and data will be released at https://github.com/ShopAgent-Team/ShopSimulator.
One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling
Jan 06, 2026The reasoning ability of large language models (LLMs) can be unleashed with reinforcement learning (RL) (OpenAI, 2024; DeepSeek-AI et al., 2025a; Zeng et al., 2025). The success of existing RL attempts in LLMs usually relies on high-quality samples of thousands or beyond. In this paper, we challenge fundamental assumptions about data requirements in RL for LLMs by demonstrating the remarkable effectiveness of one-shot learning. Specifically, we introduce polymath learning, a framework for designing one training sample that elicits multidisciplinary impact. We present three key findings: (1) A single, strategically selected math reasoning sample can produce significant performance improvements across multiple domains, including physics, chemistry, and biology with RL; (2) The math skills salient to reasoning suggest the characteristics of the optimal polymath sample; and (3) An engineered synthetic sample that integrates multidiscipline elements outperforms training with individual samples that naturally occur. Our approach achieves superior performance to training with larger datasets across various reasoning benchmarks, demonstrating that sample quality and design, rather than quantity, may be the key to unlock enhanced reasoning capabilities in language models. Our results suggest a shift, dubbed as sample engineering, toward precision engineering of training samples rather than simply increasing data volume.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
$μ$NeuFMT: Optical-Property-Adaptive Fluorescence Molecular Tomography via Implicit Neural Representation
Nov 06, 2025Fluorescence Molecular Tomography (FMT) is a promising technique for non-invasive 3D visualization of fluorescent probes, but its reconstruction remains challenging due to the inherent ill-posedness and reliance on inaccurate or often-unknown tissue optical properties. While deep learning methods have shown promise, their supervised nature limits generalization beyond training data. To address these problems, we propose $\mu$NeuFMT, a self-supervised FMT reconstruction framework that integrates implicit neural-based scene representation with explicit physical modeling of photon propagation. Its key innovation lies in jointly optimize both the fluorescence distribution and the optical properties ($\mu$) during reconstruction, eliminating the need for precise prior knowledge of tissue optics or pre-conditioned training data. We demonstrate that $\mu$NeuFMT robustly recovers accurate fluorophore distributions and optical coefficients even with severely erroneous initial values (0.5$\times$ to 2$\times$ of ground truth). Extensive numerical, phantom, and in vivo validations show that $\mu$NeuFMT outperforms conventional and supervised deep learning approaches across diverse heterogeneous scenarios. Our work establishes a new paradigm for robust and accurate FMT reconstruction, paving the way for more reliable molecular imaging in complex clinically related scenarios, such as fluorescence guided surgery.
A Multimodal Data Fusion Generative Adversarial Network for Real Time Underwater Sound Speed Field Construction
Jul 16, 2025



Sound speed profiles (SSPs) are essential parameters underwater that affects the propagation mode of underwater signals and has a critical impact on the energy efficiency of underwater acoustic communication and accuracy of underwater acoustic positioning. Traditionally, SSPs can be obtained by matching field processing (MFP), compressive sensing (CS), and deep learning (DL) methods. However, existing methods mainly rely on on-site underwater sonar observation data, which put forward strict requirements on the deployment of sonar observation systems. To achieve high-precision estimation of sound velocity distribution in a given sea area without on-site underwater data measurement, we propose a multi-modal data-fusion generative adversarial network model with residual attention block (MDF-RAGAN) for SSP construction. To improve the model's ability for capturing global spatial feature correlations, we embedded the attention mechanisms, and use residual modules for deeply capturing small disturbances in the deep ocean sound velocity distribution caused by changes of SST. Experimental results on real open dataset show that the proposed model outperforms other state-of-the-art methods, which achieves an accuracy with an error of less than 0.3m/s. Specifically, MDF-RAGAN not only outperforms convolutional neural network (CNN) and spatial interpolation (SITP) by nearly a factor of two, but also achieves about 65.8\% root mean square error (RMSE) reduction compared to mean profile, which fully reflects the enhancement of overall profile matching by multi-source fusion and cross-modal attention.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
DREAM: Disentangling Risks to Enhance Safety Alignment in Multimodal Large Language Models
Apr 25, 2025



Multimodal Large Language Models (MLLMs) pose unique safety challenges due to their integration of visual and textual data, thereby introducing new dimensions of potential attacks and complex risk combinations. In this paper, we begin with a detailed analysis aimed at disentangling risks through step-by-step reasoning within multimodal inputs. We find that systematic multimodal risk disentanglement substantially enhances the risk awareness of MLLMs. Via leveraging the strong discriminative abilities of multimodal risk disentanglement, we further introduce \textbf{DREAM} (\textit{\textbf{D}isentangling \textbf{R}isks to \textbf{E}nhance Safety \textbf{A}lignment in \textbf{M}LLMs}), a novel approach that enhances safety alignment in MLLMs through supervised fine-tuning and iterative Reinforcement Learning from AI Feedback (RLAIF). Experimental results show that DREAM significantly boosts safety during both inference and training phases without compromising performance on normal tasks (namely oversafety), achieving a 16.17\% improvement in the SIUO safe\&effective score compared to GPT-4V. The data and code are available at https://github.com/Kizna1ver/DREAM.
ProgCo: Program Helps Self-Correction of Large Language Models
Jan 02, 2025Self-Correction aims to enable large language models (LLMs) to self-verify and self-refine their initial responses without external feedback. However, LLMs often fail to effectively self-verify and generate correct feedback, further misleading refinement and leading to the failure of self-correction, especially in complex reasoning tasks. In this paper, we propose Program-driven Self-Correction (ProgCo). First, program-driven verification (ProgVe) achieves complex verification logic and extensive validation through self-generated, self-executing verification pseudo-programs. Then, program-driven refinement (ProgRe) receives feedback from ProgVe, conducts dual reflection and refinement on both responses and verification programs to mitigate misleading of incorrect feedback in complex reasoning tasks. Experiments on three instruction-following and mathematical benchmarks indicate that ProgCo achieves effective self-correction, and can be further enhance performance when combined with real program tools.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024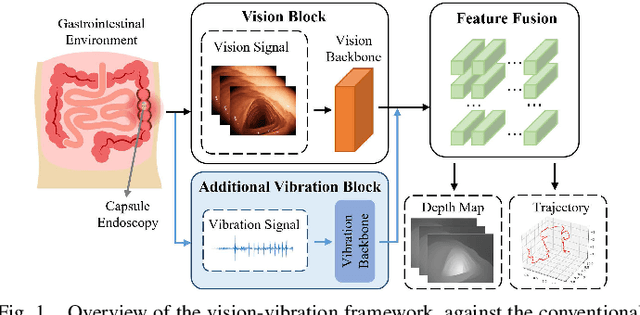
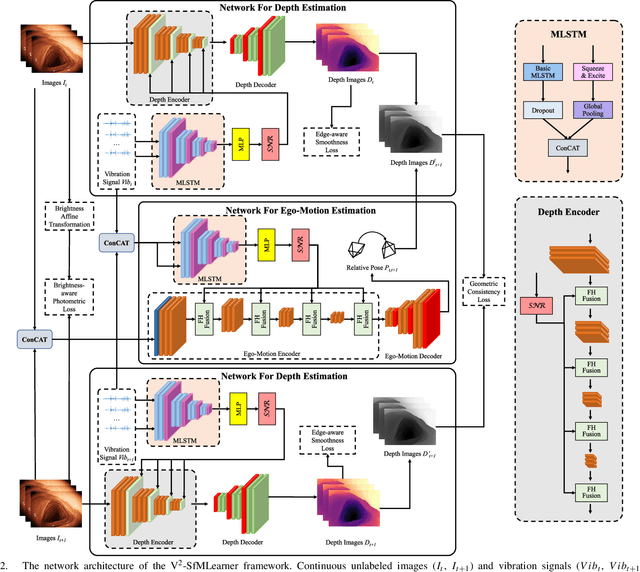
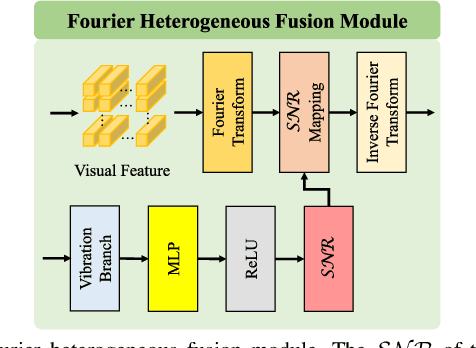
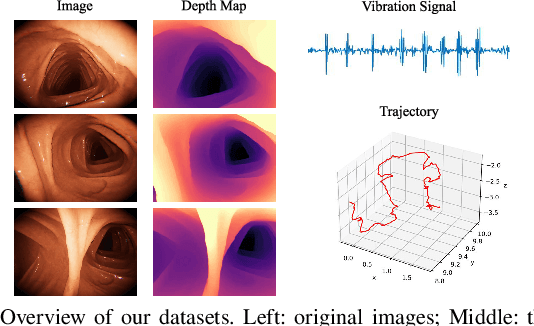
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.