 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Suffix Jailbreak attacks with Prefix-Shared KV-cache
Mar 12, 2026Suffix jailbreak attacks serve as a systematic method for red-teaming Large Language Models (LLMs) but suffer from prohibitive computational costs, as a large number of candidate suffixes need to be evaluated before identifying a jailbreak suffix. This paper presents Prefix-Shared KV Cache (PSKV), a plug-and-play inference optimization technique tailored for jailbreak suffix generation. Our method is motivated by a key observation that when performing suffix jailbreaking, while a large number of candidate prompts need to be evaluated, they share the same targeted harmful instruction as the prefix. Therefore, instead of performing redundant inference on the duplicated prefix, PSKV maintains a single KV cache for this prefix and shares it with every candidate prompt, enabling the parallel inference of diverse suffixes with minimal memory overhead. This design enables more aggressive batching strategies that would otherwise be limited by memory constraints. Extensive experiments on six widely used suffix attacks across five widely deployed LLMs demonstrate that PSKV reduces inference time by 40\% and peak memory usage by 50\%, while maintaining the original Attack Success Rate (ASR). The code has been submitted and will be released publicly.
Predicting LLM Output Length via Entropy-Guided Representations
Feb 12, 2026The long-tailed distribution of sequence lengths in LLM serving and reinforcement learning (RL) sampling causes significant computational waste due to excessive padding in batched inference. Existing methods rely on auxiliary models for static length prediction, but they incur high overhead, generalize poorly, and fail in stochastic "one-to-many" sampling scenarios. We introduce a lightweight framework that reuses the main model's internal hidden states for efficient length prediction. Our framework features two core components: 1) Entropy-Guided Token Pooling (EGTP), which uses on-the-fly activations and token entropy for highly accurate static prediction with negligible cost, and 2) Progressive Length Prediction (PLP), which dynamically estimates the remaining length at each decoding step to handle stochastic generation. To validate our approach, we build and release ForeLen, a comprehensive benchmark with long-sequence, Chain-of-Thought, and RL data. On ForeLen, EGTP achieves state-of-the-art accuracy, reducing MAE by 29.16\% over the best baseline. Integrating our methods with a length-aware scheduler yields significant end-to-end throughput gains. Our work provides a new technical and evaluation baseline for efficient LLM inference.
Canzona: A Unified, Asynchronous, and Load-Balanced Framework for Distributed Matrix-based Optimizers
Feb 04, 2026The scaling of Large Language Models (LLMs) drives interest in matrix-based optimizers (e.g., Shampoo, Muon, SOAP) for their convergence efficiency; yet their requirement for holistic updates conflicts with the tensor fragmentation in distributed frameworks like Megatron. Existing solutions are suboptimal: synchronous approaches suffer from computational redundancy, while layer-wise partitioning fails to reconcile this conflict without violating the geometric constraints of efficient communication primitives. To bridge this gap, we propose Canzona, a Unified, Asynchronous, and Load-Balanced framework that decouples logical optimizer assignment from physical parameter distribution. For Data Parallelism, we introduce an alpha-Balanced Static Partitioning strategy that respects atomicity while neutralizing the load imbalance. For Tensor Parallelism, we design an Asynchronous Compute pipeline utilizing Micro-Group Scheduling to batch fragmented updates and hide reconstruction overhead. Extensive evaluations on the Qwen3 model family (up to 32B parameters) on 256 GPUs demonstrate that our approach preserves the efficiency of established parallel architectures, achieving a 1.57x speedup in end-to-end iteration time and reducing optimizer step latency by 5.8x compared to the baseline.
Free Lunch to Meet the Gap: Intermediate Domain Reconstruction for Cross-Domain Few-Shot Learning
Nov 18, 2025Cross-Domain Few-Shot Learning (CDFSL) endeavors to transfer generalized knowledge from the source domain to target domains using only a minimal amount of training data, which faces a triplet of learning challenges in the meantime, i.e., semantic disjoint, large domain discrepancy, and data scarcity. Different from predominant CDFSL works focused on generalized representations, we make novel attempts to construct Intermediate Domain Proxies (IDP) with source feature embeddings as the codebook and reconstruct the target domain feature with this learned codebook. We then conduct an empirical study to explore the intrinsic attributes from perspectives of visual styles and semantic contents in intermediate domain proxies. Reaping benefits from these attributes of intermediate domains, we develop a fast domain alignment method to use these proxies as learning guidance for target domain feature transformation. With the collaborative learning of intermediate domain reconstruction and target feature transformation, our proposed model is able to surpass the state-of-the-art models by a margin on 8 cross-domain few-shot learning benchmarks.
FlashDP: Private Training Large Language Models with Efficient DP-SGD
Jul 01, 2025As large language models (LLMs) increasingly underpin technological advancements, the privacy of their training data emerges as a critical concern. Differential Privacy (DP) serves as a rigorous mechanism to protect this data, yet its integration via Differentially Private Stochastic Gradient Descent (DP-SGD) introduces substantial challenges, primarily due to the complexities of per-sample gradient clipping. Current explicit methods, such as Opacus, necessitate extensive storage for per-sample gradients, significantly inflating memory requirements. Conversely, implicit methods like GhostClip reduce storage needs by recalculating gradients multiple times, which leads to inefficiencies due to redundant computations. This paper introduces FlashDP, an innovative cache-friendly per-layer DP-SGD that consolidates necessary operations into a single task, calculating gradients only once in a fused manner. This approach not only diminishes memory movement by up to \textbf{50\%} but also cuts down redundant computations by \textbf{20\%}, compared to previous methods. Consequently, FlashDP does not increase memory demands and achieves a \textbf{90\%} throughput compared to the Non-DP method on a four-A100 system during the pre-training of the Llama-13B model, while maintaining parity with standard per-layer clipped DP-SGD in terms of accuracy. These advancements establish FlashDP as a pivotal development for efficient and privacy-preserving training of LLMs. FlashDP's code has been open-sourced in https://github.com/kaustpradalab/flashdp.
ZO2: Scalable Zeroth-Order Fine-Tuning for Extremely Large Language Models with Limited GPU Memory
Mar 16, 2025Fine-tuning large pre-trained LLMs generally demands extensive GPU memory. Traditional first-order optimizers like SGD encounter substantial difficulties due to increased memory requirements from storing activations and gradients during both the forward and backward phases as the model size expands. Alternatively, zeroth-order (ZO) techniques can compute gradients using just forward operations, eliminating the need to store activations. Furthermore, by leveraging CPU capabilities, it's feasible to enhance both the memory and processing power available to a single GPU. We propose a novel framework, ZO2 (Zeroth-Order Offloading), for efficient zeroth-order fine-tuning of LLMs with only limited GPU memory. Our framework dynamically shifts model parameters between the CPU and GPU as required, optimizing computation flow and maximizing GPU usage by minimizing downtime. This integration of parameter adjustments with ZO's double forward operations reduces unnecessary data movement, enhancing the fine-tuning efficacy. Additionally, our framework supports an innovative low-bit precision approach in AMP mode to streamline data exchanges between the CPU and GPU. Employing this approach allows us to fine-tune extraordinarily large models, such as the OPT-175B with more than 175 billion parameters, on a mere 18GB GPU--achievements beyond the reach of traditional methods. Moreover, our framework achieves these results with almost no additional time overhead and absolutely no accuracy loss compared to standard zeroth-order methods. ZO2's code has been open-sourced in https://github.com/liangyuwang/zo2.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024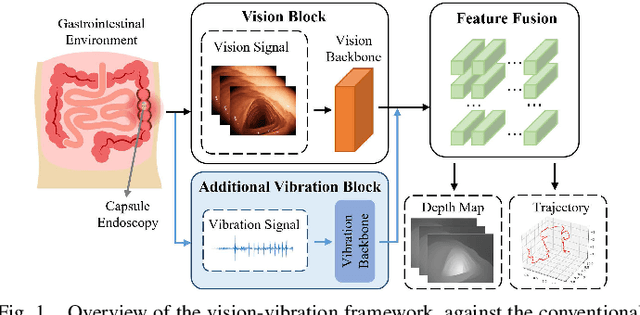
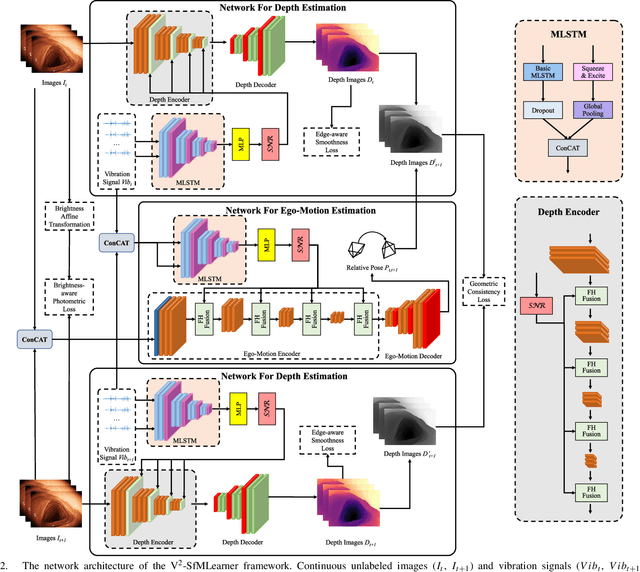
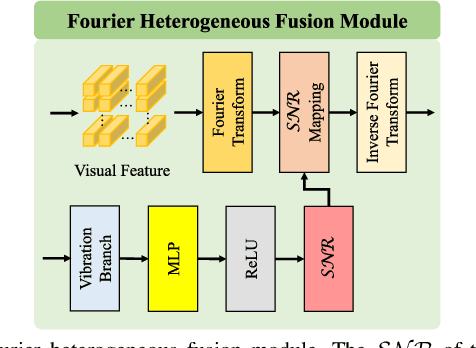
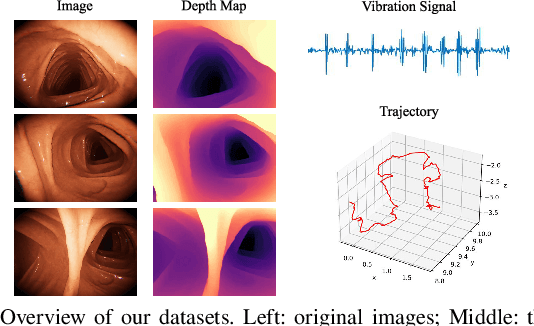
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.