 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Reasoning through Tool-supervised Reinforcement Learning
Apr 21, 2026In this paper, we investigate the problem of how to effectively master tool-use to solve complex visual reasoning tasks for Multimodal Large Language Models. To achieve that, we propose a novel Tool-supervised Reinforcement Learning (ToolsRL) framework, with direct tool supervision for more effective tool-use learning. We focus on a series of simple, native, and interpretable visual tools, including zoom-in, rotate, flip, and draw point/line, whose tool supervision is easy to collect. A reinforcement learning curriculum is developed, where the first stage is solely optimized by a set of well motivated tool-specific rewards, and the second stage is trained with the accuracy targeted rewards while allowing calling tools. In this way, tool calling capability is mastered before using tools to complete visual reasoning tasks, avoiding the potential optimization conflict among those heterogeneous tasks. Our experiments have shown that the tool-supervised curriculum training is efficient and ToolsRL can achieve strong tool-use capabilities for complex visual reasoning tasks.
From Natural Language to Executable Narsese: A Neuro-Symbolic Benchmark and Pipeline for Reasoning with NARS
Apr 20, 2026Large language models (LLMs) are highly capable at language generation, but they remain unreliable when reasoning requires explicit symbolic structure, multi-step inference, and interpretable uncertainty. This paper presents a neuro-symbolic framework for translating natural-language reasoning problems into executable formal representations using first-order logic (FOL) and Narsese, the language of the Non-Axiomatic Reasoning System (NARS). To support this direction, we introduce NARS-Reasoning-v0.1, a benchmark of natural-language reasoning problems paired with FOL forms, executable Narsese programs, and three gold labels: True, False, and Uncertain. We develop a deterministic compilation pipeline from FOL to executable Narsese and validate retained examples through runtime execution in OpenNARS for Applications (ONA), ensuring that the symbolic targets are not only syntactically well formed but also behaviorally aligned with the intended answer. We further present Language-Structured Perception (LSP), a formulation in which an LLM is trained to produce reasoning-relevant symbolic structure rather than only a final verbal response. As an initial proof of concept, we also train and release a Phi-2 LoRA adapter on NARS-Reasoning-v0.1 for three-label reasoning classification, showing that the benchmark can support supervised adaptation in addition to executable evaluation. Overall, the paper positions executable symbolic generation and execution-based validation as a practical path toward more reliable neuro-symbolic reasoning systems.
FRTSearch: Unified Detection and Parameter Inference of Fast Radio Transients using Instance Segmentation
Apr 14, 2026The exponential growth of data from modern radio telescopes presents a significant challenge to traditional single-pulse search algorithms, which are computationally intensive and prone to high false-positive rates due to Radio Frequency Interference (RFI). In this work, we introduce FRTSearch, an end-to-end framework unifying the detection and physical characterization of Fast Radio Transients (FRTs). Leveraging the morphological universality of dispersive trajectories in time-frequency dynamic spectra, we reframe FRT detection as a pattern recognition problem governed by the cold plasma dispersion relation. To facilitate this, we constructed CRAFTS-FRT, a pixel-level annotated dataset derived from the Commensal Radio Astronomy FAST Survey (CRAFTS), comprising 2{,}392 instances across diverse source classes. This dataset enables the training of a Mask R-CNN model for precise trajectory segmentation. Coupled with our physics-driven IMPIC algorithm, the framework maps the geometric coordinates of segmented trajectories to directly infer the Dispersion Measure (DM) and Time of Arrival (ToA). Benchmarking on the FAST-FREX dataset shows that FRTSearch achieves a 98.0\% recall, competitive with exhaustive search methods, while reducing false positives by over 99.9\% compared to PRESTO and delivering a processing speedup of up to $13.9\times$. Furthermore, the framework demonstrates robust cross-facility generalization, detecting all 19 tested FRBs from the ASKAP survey without retraining. By shifting the paradigm from ``search-then-identify'' to ``detect-and-infer,'' FRTSearch provides a scalable, high-precision solution for real-time discovery in the era of petabyte-scale radio astronomy.
ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
Jan 26, 2026Large language model (LLM)-based agents are increasingly deployed in e-commerce shopping. To perform thorough, user-tailored product searches, agents should interpret personal preferences, engage in multi-turn dialogues, and ultimately retrieve and discriminate among highly similar products. However, existing research has yet to provide a unified simulation environment that consistently captures all of these aspects, and always focuses solely on evaluation benchmarks without training support. In this paper, we introduce ShopSimulator, a large-scale and challenging Chinese shopping environment. Leveraging ShopSimulator, we evaluate LLMs across diverse scenarios, finding that even the best-performing models achieve less than 40% full-success rate. Error analysis reveals that agents struggle with deep search and product selection in long trajectories, fail to balance the use of personalization cues, and to effectively engage with users. Further training exploration provides practical guidance for overcoming these weaknesses, with the combination of supervised fine-tuning (SFT) and reinforcement learning (RL) yielding significant performance improvements. Code and data will be released at https://github.com/ShopAgent-Team/ShopSimulator.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
FID-Net: A Feature-Enhanced Deep Learning Network for Forest Infestation Detection
Dec 15, 2025Forest pests threaten ecosystem stability, requiring efficient monitoring. To overcome the limitations of traditional methods in large-scale, fine-grained detection, this study focuses on accurately identifying infected trees and analyzing infestation patterns. We propose FID-Net, a deep learning model that detects pest-affected trees from UAV visible-light imagery and enables infestation analysis via three spatial metrics. Based on YOLOv8n, FID-Net introduces a lightweight Feature Enhancement Module (FEM) to extract disease-sensitive cues, an Adaptive Multi-scale Feature Fusion Module (AMFM) to align and fuse dual-branch features (RGB and FEM-enhanced), and an Efficient Channel Attention (ECA) mechanism to enhance discriminative information efficiently. From detection results, we construct a pest situation analysis framework using: (1) Kernel Density Estimation to locate infection hotspots; (2) neighborhood evaluation to assess healthy trees' infection risk; (3) DBSCAN clustering to identify high-density healthy clusters as priority protection zones. Experiments on UAV imagery from 32 forest plots in eastern Tianshan, China, show that FID-Net achieves 86.10% precision, 75.44% recall, 82.29% mAP@0.5, and 64.30% mAP@0.5:0.95, outperforming mainstream YOLO models. Analysis confirms infected trees exhibit clear clustering, supporting targeted forest protection. FID-Net enables accurate tree health discrimination and, combined with spatial metrics, provides reliable data for intelligent pest monitoring, early warning, and precise management.
MMDCP: A Distribution-free Approach to Outlier Detection and Classification with Coverage Guarantees and SCW-FDR Control
Nov 15, 2025We propose the Modified Mahalanobis Distance Conformal Prediction (MMDCP), a unified framework for multi-class classification and outlier detection under label shift, where the training and test distributions may differ. In such settings, many existing methods construct nonconformity scores based on empirical cumulative or density functions combined with data-splitting strategies. However, these approaches are often computationally expensive due to their heavy reliance on resampling procedures and tend to produce overly conservative prediction sets with unstable coverage, especially in small samples. To address these challenges, MMDCP combines class-specific distance measures with full conformal prediction to construct a score function, thereby producing adaptive prediction sets that effectively capture both inlier and outlier structures. Under mild regularity conditions, we establish convergence rates for the resulting sets and provide the first theoretical characterization of the gap between oracle and empirical conformal $p$-values, which ensures valid coverage and effective control of the class-wise false discovery rate (CW-FDR). We further introduce the Summarized Class-Wise FDR (SCW-FDR), a novel global error metric aggregating false discoveries across classes, and show that it can be effectively controlled within the MMDCP framework. Extensive simulations and two real-data applications support our theoretical findings and demonstrate the advantages of the proposed method.
PCRLLM: Proof-Carrying Reasoning with Large Language Models under Stepwise Logical Constraints
Nov 11, 2025Large Language Models (LLMs) often exhibit limited logical coherence, mapping premises to conclusions without adherence to explicit inference rules. We propose Proof-Carrying Reasoning with LLMs (PCRLLM), a framework that constrains reasoning to single-step inferences while preserving natural language formulations. Each output explicitly specifies premises, rules, and conclusions, thereby enabling verification against a target logic. This mechanism mitigates trustworthiness concerns by supporting chain-level validation even in black-box settings. Moreover, PCRLLM facilitates systematic multi-LLM collaboration, allowing intermediate steps to be compared and integrated under formal rules. Finally, we introduce a benchmark schema for generating large-scale step-level reasoning data, combining natural language expressiveness with formal rigor.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
SatelliteFormula: Multi-Modal Symbolic Regression from Remote Sensing Imagery for Physics Discovery
Jun 06, 2025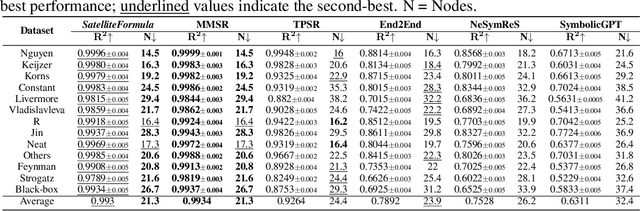



We propose SatelliteFormula, a novel symbolic regression framework that derives physically interpretable expressions directly from multi-spectral remote sensing imagery. Unlike traditional empirical indices or black-box learning models, SatelliteFormula combines a Vision Transformer-based encoder for spatial-spectral feature extraction with physics-guided constraints to ensure consistency and interpretability. Existing symbolic regression methods struggle with the high-dimensional complexity of multi-spectral data; our method addresses this by integrating transformer representations into a symbolic optimizer that balances accuracy and physical plausibility. Extensive experiments on benchmark datasets and remote sensing tasks demonstrate superior performance, stability, and generalization compared to state-of-the-art baselines. SatelliteFormula enables interpretable modeling of complex environmental variables, bridging the gap between data-driven learning and physical understanding.