 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoGE: Sim-to-Real Online Geometric Estimation for Monocular Colonoscopy
May 13, 2026Geometric estimation including depth estimation and scene reconstruction is a crucial technique for colonoscopy which can provide surgeons with 3D spatial perception and navigation. However, geometric ground truth in colonoscopy is difficult to obtain due to narrow and enclosed space of the colon, while there is a large feature gap between simulated data and realistic data caused by artifacts and illumination. In this paper, we present CoGE, a novel framework for online monocular geometric estimation during colonoscopy. Firstly, we propose an illumination-aware supervision module based on the Retinex theory to address illumination diversity in different colonoscopy scenes. Moreover, a structure-aware perception module is proposed based on wavelet decomposition to extract common structural and local features of the colon. Both quantitative and qualitative results demonstrate that the proposed model solely trained on simulated data achieves state-of-the-art performance in geometric estimation for both simulated and realistic scenes.
Leveling3D: Leveling Up 3D Reconstruction with Feed-Forward 3D Gaussian Splatting and Geometry-Aware Generation
Mar 17, 2026Feed-forward 3D reconstruction has revolutionized 3D vision, providing a powerful baseline for downstream tasks such as novel-view synthesis with 3D Gaussian Splatting. Previous works explore fixing the corrupted rendering results with a diffusion model. However, they lack geometric concern and fail at filling the missing area on the extrapolated view. In this work, we introduce Leveling3D, a novel pipeline that integrates feed-forward 3D reconstruction with geometrical-consistent generation to enable holistic simultaneous reconstruction and generation. We propose a geometry-aware leveling adapter, a lightweight technique that aligns internal knowledge in the diffusion model with the geometry prior from the feed-forward model. The leveling adapter enables generation on the artifact area of the extrapolated novel views caused by underconstrained regions of the 3D representation. Specifically, to learn a more diverse distributed generation, we introduce the palette filtering strategy for training, and a test-time masking refinement to prevent messy boundaries along the fixing regions. More importantly, the enhanced extrapolated novel views from Leveling3D could be used as the inputs for feed-forward 3DGS, leveling up the 3D reconstruction. We achieve SOTA performance on public datasets, including tasks such as novel-view synthesis and depth estimation.
EndoDDC: Learning Sparse to Dense Reconstruction for Endoscopic Robotic Navigation via Diffusion Depth Completion
Feb 26, 2026Accurate depth estimation plays a critical role in the navigation of endoscopic surgical robots, forming the foundation for 3D reconstruction and safe instrument guidance. Fine-tuning pretrained models heavily relies on endoscopic surgical datasets with precise depth annotations. While existing self-supervised depth estimation techniques eliminate the need for accurate depth annotations, their performance degrades in environments with weak textures and variable lighting, leading to sparse reconstruction with invalid depth estimation. Depth completion using sparse depth maps can mitigate these issues and improve accuracy. Despite the advances in depth completion techniques in general fields, their application in endoscopy remains limited. To overcome these limitations, we propose EndoDDC, an endoscopy depth completion method that integrates images, sparse depth information with depth gradient features, and optimizes depth maps through a diffusion model, addressing the issues of weak texture and light reflection in endoscopic environments. Extensive experiments on two publicly available endoscopy datasets show that our approach outperforms state-of-the-art models in both depth accuracy and robustness. This demonstrates the potential of our method to reduce visual errors in complex endoscopic environments. Our code will be released at https://github.com/yinheng-lin/EndoDDC.
TR2M: Transferring Monocular Relative Depth to Metric Depth with Language Descriptions and Scale-Oriented Contrast
Jun 16, 2025This work presents a generalizable framework to transfer relative depth to metric depth. Current monocular depth estimation methods are mainly divided into metric depth estimation (MMDE) and relative depth estimation (MRDE). MMDEs estimate depth in metric scale but are often limited to a specific domain. MRDEs generalize well across different domains, but with uncertain scales which hinders downstream applications. To this end, we aim to build up a framework to solve scale uncertainty and transfer relative depth to metric depth. Previous methods used language as input and estimated two factors for conducting rescaling. Our approach, TR2M, utilizes both text description and image as inputs and estimates two rescale maps to transfer relative depth to metric depth at pixel level. Features from two modalities are fused with a cross-modality attention module to better capture scale information. A strategy is designed to construct and filter confident pseudo metric depth for more comprehensive supervision. We also develop scale-oriented contrastive learning to utilize depth distribution as guidance to enforce the model learning about intrinsic knowledge aligning with the scale distribution. TR2M only exploits a small number of trainable parameters to train on datasets in various domains and experiments not only demonstrate TR2M's great performance in seen datasets but also reveal superior zero-shot capabilities on five unseen datasets. We show the huge potential in pixel-wise transferring relative depth to metric depth with language assistance. (Code is available at: https://github.com/BeileiCui/TR2M)
Learning to Efficiently Adapt Foundation Models for Self-Supervised Endoscopic 3D Scene Reconstruction from Any Cameras
Mar 20, 2025



Accurate 3D scene reconstruction is essential for numerous medical tasks. Given the challenges in obtaining ground truth data, there has been an increasing focus on self-supervised learning (SSL) for endoscopic depth estimation as a basis for scene reconstruction. While foundation models have shown remarkable progress in visual tasks, their direct application to the medical domain often leads to suboptimal results. However, the visual features from these models can still enhance endoscopic tasks, emphasizing the need for efficient adaptation strategies, which still lack exploration currently. In this paper, we introduce Endo3DAC, a unified framework for endoscopic scene reconstruction that efficiently adapts foundation models. We design an integrated network capable of simultaneously estimating depth maps, relative poses, and camera intrinsic parameters. By freezing the backbone foundation model and training only the specially designed Gated Dynamic Vector-Based Low-Rank Adaptation (GDV-LoRA) with separate decoder heads, Endo3DAC achieves superior depth and pose estimation while maintaining training efficiency. Additionally, we propose a 3D scene reconstruction pipeline that optimizes depth maps' scales, shifts, and a few parameters based on our integrated network. Extensive experiments across four endoscopic datasets demonstrate that Endo3DAC significantly outperforms other state-of-the-art methods while requiring fewer trainable parameters. To our knowledge, we are the first to utilize a single network that only requires surgical videos to perform both SSL depth estimation and scene reconstruction tasks. The code will be released upon acceptance.
Advancing Dense Endoscopic Reconstruction with Gaussian Splatting-driven Surface Normal-aware Tracking and Mapping
Jan 31, 2025



Simultaneous Localization and Mapping (SLAM) is essential for precise surgical interventions and robotic tasks in minimally invasive procedures. While recent advancements in 3D Gaussian Splatting (3DGS) have improved SLAM with high-quality novel view synthesis and fast rendering, these systems struggle with accurate depth and surface reconstruction due to multi-view inconsistencies. Simply incorporating SLAM and 3DGS leads to mismatches between the reconstructed frames. In this work, we present Endo-2DTAM, a real-time endoscopic SLAM system with 2D Gaussian Splatting (2DGS) to address these challenges. Endo-2DTAM incorporates a surface normal-aware pipeline, which consists of tracking, mapping, and bundle adjustment modules for geometrically accurate reconstruction. Our robust tracking module combines point-to-point and point-to-plane distance metrics, while the mapping module utilizes normal consistency and depth distortion to enhance surface reconstruction quality. We also introduce a pose-consistent strategy for efficient and geometrically coherent keyframe sampling. Extensive experiments on public endoscopic datasets demonstrate that Endo-2DTAM achieves an RMSE of $1.87\pm 0.63$ mm for depth reconstruction of surgical scenes while maintaining computationally efficient tracking, high-quality visual appearance, and real-time rendering. Our code will be released at github.com/lastbasket/Endo-2DTAM.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024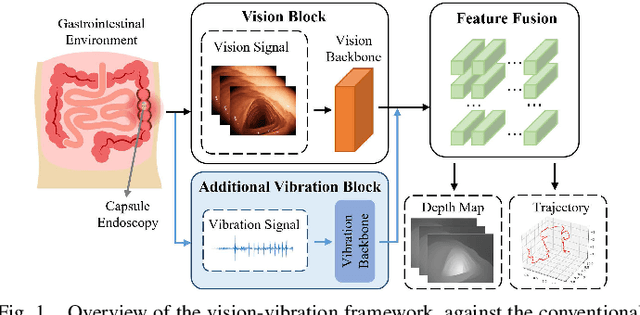
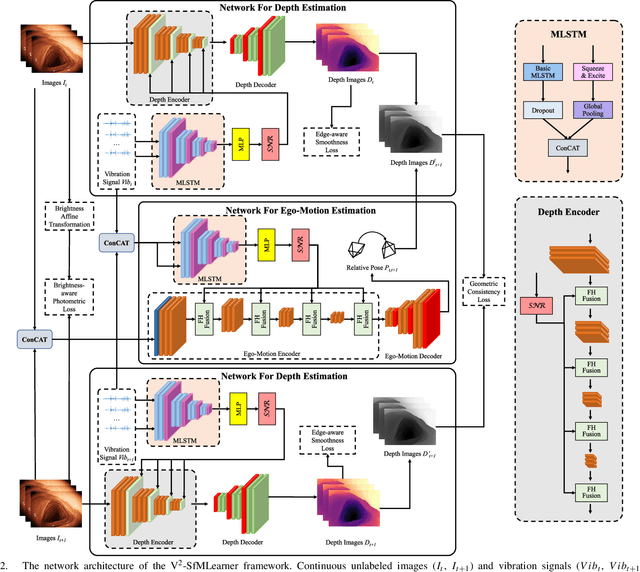
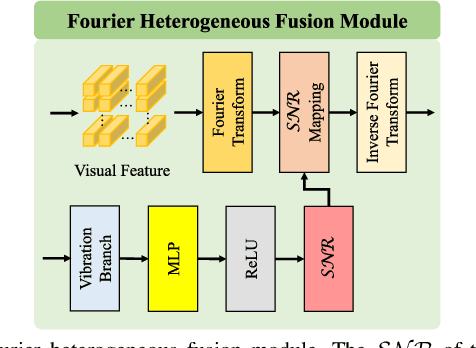
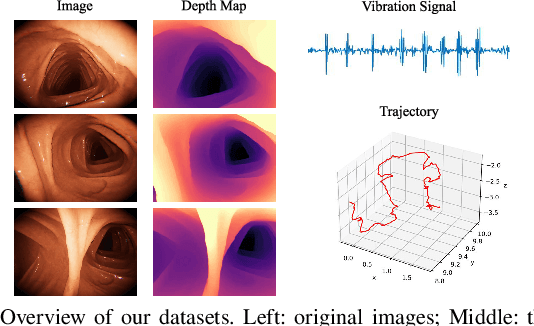
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
Benchmarking Robustness of Endoscopic Depth Estimation with Synthetically Corrupted Data
Sep 24, 2024Accurate depth perception is crucial for patient outcomes in endoscopic surgery, yet it is compromised by image distortions common in surgical settings. To tackle this issue, our study presents a benchmark for assessing the robustness of endoscopic depth estimation models. We have compiled a comprehensive dataset that reflects real-world conditions, incorporating a range of synthetically induced corruptions at varying severity levels. To further this effort, we introduce the Depth Estimation Robustness Score (DERS), a novel metric that combines measures of error, accuracy, and robustness to meet the multifaceted requirements of surgical applications. This metric acts as a foundational element for evaluating performance, establishing a new paradigm for the comparative analysis of depth estimation technologies. Additionally, we set forth a benchmark focused on robustness for the evaluation of depth estimation in endoscopic surgery, with the aim of driving progress in model refinement. A thorough analysis of two monocular depth estimation models using our framework reveals crucial information about their reliability under adverse conditions. Our results emphasize the essential need for algorithms that can tolerate data corruption, thereby advancing discussions on improving model robustness. The impact of this research transcends theoretical frameworks, providing concrete gains in surgical precision and patient safety. This study establishes a benchmark for the robustness of depth estimation and serves as a foundation for developing more resilient surgical support technologies. Code is available at https://github.com/lofrienger/EndoDepthBenchmark.
Registering Neural 4D Gaussians for Endoscopic Surgery
Jul 29, 2024



The recent advance in neural rendering has enabled the ability to reconstruct high-quality 4D scenes using neural networks. Although 4D neural reconstruction is popular, registration for such representations remains a challenging task, especially for dynamic scene registration in surgical planning and simulation. In this paper, we propose a novel strategy for dynamic surgical neural scene registration. We first utilize 4D Gaussian Splatting to represent the surgical scene and capture both static and dynamic scenes effectively. Then, a spatial aware feature aggregation method, Spatially Weight Cluttering (SWC) is proposed to accurately align the feature between surgical scenes, enabling precise and realistic surgical simulations. Lastly, we present a novel strategy of deformable scene registration to register two dynamic scenes. By incorporating both spatial and temporal information for correspondence matching, our approach achieves superior performance compared to existing registration methods for implicit neural representation. The proposed method has the potential to improve surgical planning and training, ultimately leading to better patient outcomes.
Head Pose Estimation and 3D Neural Surface Reconstruction via Monocular Camera in situ for Navigation and Safe Insertion into Natural Openings
Jun 18, 2024



As the significance of simulation in medical care and intervention continues to grow, it is anticipated that a simplified and low-cost platform can be set up to execute personalized diagnoses and treatments. 3D Slicer can not only perform medical image analysis and visualization but can also provide surgical navigation and surgical planning functions. In this paper, we have chosen 3D Slicer as our base platform and monocular cameras are used as sensors. Then, We used the neural radiance fields (NeRF) algorithm to complete the 3D model reconstruction of the human head. We compared the accuracy of the NeRF algorithm in generating 3D human head scenes and utilized the MarchingCube algorithm to generate corresponding 3D mesh models. The individual's head pose, obtained through single-camera vision, is transmitted in real-time to the scene created within 3D Slicer. The demonstrations presented in this paper include real-time synchronization of transformations between the human head model in the 3D Slicer scene and the detected head posture. Additionally, we tested a scene where a tool, marked with an ArUco Maker tracked by a single camera, synchronously points to the real-time transformation of the head posture. These demos indicate that our methodology can provide a feasible real-time simulation platform for nasopharyngeal swab collection or intubation.