 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Eyes and Memory for VideoLLMs: Information-Aware Visual Token Pruning for Efficient and Reliable VideoLLM Reasoning
Nov 11, 2025Current Video Large Language Models (VideoLLMs) suffer from quadratic computational complexity and key-value cache scaling, due to their reliance on processing excessive redundant visual tokens. To address this problem, we propose SharpV, a minimalist and efficient method for adaptive pruning of visual tokens and KV cache. Different from most uniform compression approaches, SharpV dynamically adjusts pruning ratios based on spatial-temporal information. Remarkably, this adaptive mechanism occasionally achieves performance gains over dense models, offering a novel paradigm for adaptive pruning. During the KV cache pruning stage, based on observations of visual information degradation, SharpV prunes degraded visual features via a self-calibration manner, guided by similarity to original visual features. In this way, SharpV achieves hierarchical cache pruning from the perspective of information bottleneck, offering a new insight into VideoLLMs' information flow. Experiments on multiple public benchmarks demonstrate the superiority of SharpV. Moreover, to the best of our knowledge, SharpV is notably the first two-stage pruning framework that operates without requiring access to exposed attention scores, ensuring full compatibility with hardware acceleration techniques like Flash Attention.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
AI for Service: Proactive Assistance with AI Glasses
Oct 16, 2025In an era where AI is evolving from a passive tool into an active and adaptive companion, we introduce AI for Service (AI4Service), a new paradigm that enables proactive and real-time assistance in daily life. Existing AI services remain largely reactive, responding only to explicit user commands. We argue that a truly intelligent and helpful assistant should be capable of anticipating user needs and taking actions proactively when appropriate. To realize this vision, we propose Alpha-Service, a unified framework that addresses two fundamental challenges: Know When to intervene by detecting service opportunities from egocentric video streams, and Know How to provide both generalized and personalized services. Inspired by the von Neumann computer architecture and based on AI glasses, Alpha-Service consists of five key components: an Input Unit for perception, a Central Processing Unit for task scheduling, an Arithmetic Logic Unit for tool utilization, a Memory Unit for long-term personalization, and an Output Unit for natural human interaction. As an initial exploration, we implement Alpha-Service through a multi-agent system deployed on AI glasses. Case studies, including a real-time Blackjack advisor, a museum tour guide, and a shopping fit assistant, demonstrate its ability to seamlessly perceive the environment, infer user intent, and provide timely and useful assistance without explicit prompts.
SaFeR-VLM: Toward Safety-aware Fine-grained Reasoning in Multimodal Models
Oct 08, 2025Multimodal Large Reasoning Models (MLRMs) demonstrate impressive cross-modal reasoning but often amplify safety risks under adversarial or unsafe prompts, a phenomenon we call the \textit{Reasoning Tax}. Existing defenses mainly act at the output level and do not constrain the reasoning process, leaving models exposed to implicit risks. In this paper, we propose SaFeR-VLM, a safety-aligned reinforcement learning framework that embeds safety directly into multimodal reasoning. The framework integrates four components: (I) QI-Safe-10K, a curated dataset emphasizing safety-critical and reasoning-sensitive cases; (II) safety-aware rollout, where unsafe generations undergo reflection and correction instead of being discarded; (III) structured reward modeling with multi-dimensional weighted criteria and explicit penalties for hallucinations and contradictions; and (IV) GRPO optimization, which reinforces both safe and corrected trajectories. This unified design shifts safety from a passive safeguard to an active driver of reasoning, enabling scalable and generalizable safety-aware reasoning. SaFeR-VLM further demonstrates robustness against both explicit and implicit risks, supporting dynamic and interpretable safety decisions beyond surface-level filtering. SaFeR-VLM-3B achieves average performance $70.13$ and $78.97$ on safety and helpfulness across six benchmarks, surpassing both same-scale and $>10\times$ larger models such as Skywork-R1V3-38B, Qwen2.5VL-72B, and GLM4.5V-106B. Remarkably, SaFeR-VLM-7B benefits from its increased scale to surpass GPT-5-mini and Gemini-2.5-Flash by \num{6.47} and \num{16.76} points respectively on safety metrics, achieving this improvement without any degradation in helpfulness performance. Our codes are available at https://github.com/HarveyYi/SaFeR-VLM.
Are We Using the Right Benchmark: An Evaluation Framework for Visual Token Compression Methods
Oct 08, 2025Recent endeavors to accelerate inference in Multimodal Large Language Models (MLLMs) have primarily focused on visual token compression. The effectiveness of these methods is typically assessed by measuring the accuracy drop on established benchmarks, comparing model performance before and after compression. However, these benchmarks are originally designed to assess the perception and reasoning capabilities of MLLMs, rather than to evaluate compression techniques. As a result, directly applying them to visual token compression introduces a task mismatch. Strikingly, our investigation reveals that simple image downsampling consistently outperforms many advanced compression methods across multiple widely used benchmarks. Through extensive experiments, we make the following observations: (i) Current benchmarks are noisy for the visual token compression task. (ii) Down-sampling is able to serve as a data filter to evaluate the difficulty of samples in the visual token compression task. Motivated by these findings, we introduce VTC-Bench, an evaluation framework that incorporates a data filtering mechanism to denoise existing benchmarks, thereby enabling fairer and more accurate assessment of visual token compression methods. All data and code are available at https://github.com/Chenfei-Liao/VTC-Bench.
DeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
Sep 18, 2025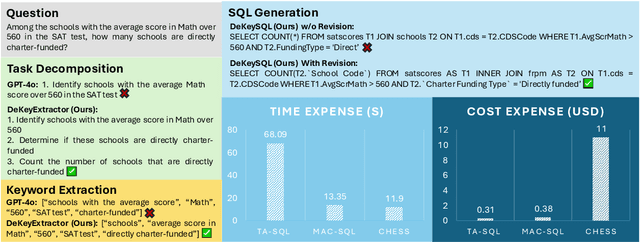
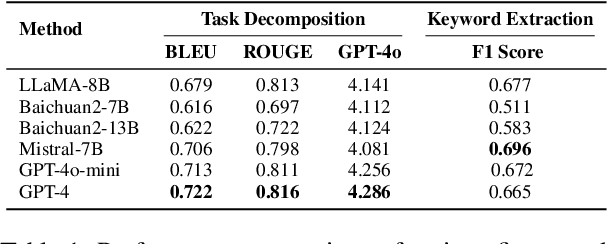


Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.
PANORAMA: The Rise of Omnidirectional Vision in the Embodied AI Era
Sep 16, 2025Omnidirectional vision, using 360-degree vision to understand the environment, has become increasingly critical across domains like robotics, industrial inspection, and environmental monitoring. Compared to traditional pinhole vision, omnidirectional vision provides holistic environmental awareness, significantly enhancing the completeness of scene perception and the reliability of decision-making. However, foundational research in this area has historically lagged behind traditional pinhole vision. This talk presents an emerging trend in the embodied AI era: the rapid development of omnidirectional vision, driven by growing industrial demand and academic interest. We highlight recent breakthroughs in omnidirectional generation, omnidirectional perception, omnidirectional understanding, and related datasets. Drawing on insights from both academia and industry, we propose an ideal panoramic system architecture in the embodied AI era, PANORAMA, which consists of four key subsystems. Moreover, we offer in-depth opinions related to emerging trends and cross-community impacts at the intersection of panoramic vision and embodied AI, along with the future roadmap and open challenges. This overview synthesizes state-of-the-art advancements and outlines challenges and opportunities for future research in building robust, general-purpose omnidirectional AI systems in the embodied AI era.
A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Aug 12, 2025



As text generation has become a core capability of modern Large Language Models (LLMs), it underpins a wide range of downstream applications. However, most existing LLMs rely on autoregressive (AR) generation, producing one token at a time based on previously generated context-resulting in limited generation speed due to the inherently sequential nature of the process. To address this challenge, an increasing number of researchers have begun exploring parallel text generation-a broad class of techniques aimed at breaking the token-by-token generation bottleneck and improving inference efficiency. Despite growing interest, there remains a lack of comprehensive analysis on what specific techniques constitute parallel text generation and how they improve inference performance. To bridge this gap, we present a systematic survey of parallel text generation methods. We categorize existing approaches into AR-based and Non-AR-based paradigms, and provide a detailed examination of the core techniques within each category. Following this taxonomy, we assess their theoretical trade-offs in terms of speed, quality, and efficiency, and examine their potential for combination and comparison with alternative acceleration strategies. Finally, based on our findings, we highlight recent advancements, identify open challenges, and outline promising directions for future research in parallel text generation.
GM-PRM: A Generative Multimodal Process Reward Model for Multimodal Mathematical Reasoning
Aug 06, 2025Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities but often struggle with complex, multi-step mathematical reasoning, where minor errors in visual perception or logical deduction can lead to complete failure. While Process Reward Models (PRMs) offer step-by-step supervision, existing multimodal PRMs are limited to being binary verifiers that can identify but not correct errors, offering little explanatory power. To address these deficiencies, we introduce the Generative Multimodal Process Reward Model (GM-PRM), a novel paradigm that transforms the PRM from a passive judge into an active reasoning collaborator. Instead of a simple scalar score, GM-PRM provides a fine-grained, interpretable analysis of each reasoning step, evaluating its step intent, visual alignment, and logical soundness. More critically, GM-PRM is trained to generate a corrected version of the first erroneous step it identifies. This unique corrective capability enables our new test-time inference strategy, Refined Best-of-N (Refined-BoN). This framework actively enhances solution quality by using the PRM's generated correction to guide the policy model toward a more promising reasoning trajectory, thereby improving the diversity and correctness of the solution pool. We demonstrate that GM-PRM achieves state-of-the-art results on multiple multimodal math benchmarks, significantly boosting policy model performance with remarkable data efficiency, requiring only a 20K-sample training dataset. Our code will be released upon acceptance.
VLA-Mark: A cross modal watermark for large vision-language alignment model
Jul 18, 2025



Vision-language models demand watermarking solutions that protect intellectual property without compromising multimodal coherence. Existing text watermarking methods disrupt visual-textual alignment through biased token selection and static strategies, leaving semantic-critical concepts vulnerable. We propose VLA-Mark, a vision-aligned framework that embeds detectable watermarks while preserving semantic fidelity through cross-modal coordination. Our approach integrates multiscale visual-textual alignment metrics, combining localized patch affinity, global semantic coherence, and contextual attention patterns, to guide watermark injection without model retraining. An entropy-sensitive mechanism dynamically balances watermark strength and semantic preservation, prioritizing visual grounding during low-uncertainty generation phases. Experiments show 7.4% lower PPL and 26.6% higher BLEU than conventional methods, with near-perfect detection (98.8% AUC). The framework demonstrates 96.1\% attack resilience against attacks such as paraphrasing and synonym substitution, while maintaining text-visual consistency, establishing new standards for quality-preserving multimodal watermarking