 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025



Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
DTRec: Learning Dynamic Reasoning Trajectories for Sequential Recommendation
Dec 16, 2025



Inspired by advances in LLMs, reasoning-enhanced sequential recommendation performs multi-step deliberation before making final predictions, unlocking greater potential for capturing user preferences. However, current methods are constrained by static reasoning trajectories that are ill-suited for the diverse complexity of user behaviors. They suffer from two key limitations: (1) a static reasoning direction, which uses flat supervision signals misaligned with human-like hierarchical reasoning, and (2) a fixed reasoning depth, which inefficiently applies the same computational effort to all users, regardless of pattern complexity. These rigidity lead to suboptimal performance and significant computational waste. To overcome these challenges, we propose DTRec, a novel and effective framework that explores the Dynamic reasoning Trajectory for Sequential Recommendation along both direction and depth. To guide the direction, we develop Hierarchical Process Supervision (HPS), which provides coarse-to-fine supervisory signals to emulate the natural, progressive refinement of human cognitive processes. To optimize the depth, we introduce the Adaptive Reasoning Halting (ARH) mechanism that dynamically adjusts the number of reasoning steps by jointly monitoring three indicators. Extensive experiments on three real-world datasets demonstrate the superiority of our approach, achieving up to a 24.5% performance improvement over strong baselines while simultaneously reducing computational cost by up to 41.6%.
Intent-Guided Reasoning for Sequential Recommendation
Dec 16, 2025Sequential recommendation systems aim to capture users' evolving preferences from their interaction histories. Recent reasoningenhanced methods have shown promise by introducing deliberate, chain-of-thought-like processes with intermediate reasoning steps. However, these methods rely solely on the next target item as supervision, leading to two critical issues: (1) reasoning instability--the process becomes overly sensitive to recent behaviors and spurious interactions like accidental clicks, and (2) surface-level reasoning--the model memorizes item-to-item transitions rather than understanding intrinsic behavior patterns. To address these challenges, we propose IGR-SR, an Intent-Guided Reasoning framework for Sequential Recommendation that anchors the reasoning process to explicitly extracted high-level intents. Our framework comprises three key components: (1) a Latent Intent Distiller (LID) that efficiently extracts multi-faceted intents using a frozen encoder with learnable tokens, (2) an Intent-aware Deliberative Reasoner (IDR) that decouples reasoning into intent deliberation and decision-making via a dual-attention architecture, and (3) an Intent Consistency Regularization (ICR) that ensures robustness by enforcing consistent representations across different intent views. Extensive experiments on three public datasets demonstrate that IGR-SR achieves an average 7.13% improvement over state-of-the-art baselines. Critically, under 20% behavioral noise, IGR-SR degrades only 10.4% compared to 16.2% and 18.6% for competing methods, validating the effectiveness and robustness of intent-guided reasoning.
What Matters in LLM-Based Feature Extractor for Recommender? A Systematic Analysis of Prompts, Models, and Adaptation
Sep 18, 2025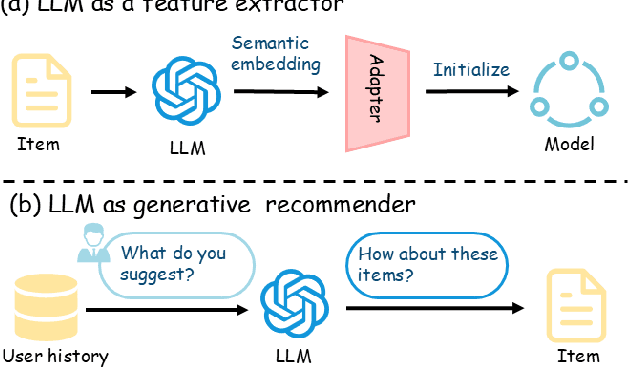

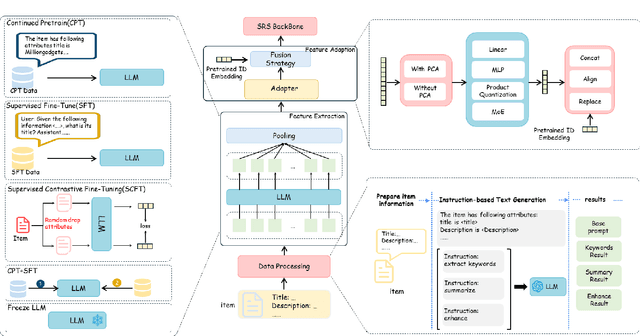

Using Large Language Models (LLMs) to generate semantic features has been demonstrated as a powerful paradigm for enhancing Sequential Recommender Systems (SRS). This typically involves three stages: processing item text, extracting features with LLMs, and adapting them for downstream models. However, existing methods vary widely in prompting, architecture, and adaptation strategies, making it difficult to fairly compare design choices and identify what truly drives performance. In this work, we propose RecXplore, a modular analytical framework that decomposes the LLM-as-feature-extractor pipeline into four modules: data processing, semantic feature extraction, feature adaptation, and sequential modeling. Instead of proposing new techniques, RecXplore revisits and organizes established methods, enabling systematic exploration of each module in isolation. Experiments on four public datasets show that simply combining the best designs from existing techniques without exhaustive search yields up to 18.7% relative improvement in NDCG@5 and 12.7% in HR@5 over strong baselines. These results underscore the utility of modular benchmarking for identifying effective design patterns and promoting standardized research in LLM-enhanced recommendation.
DeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
Sep 18, 2025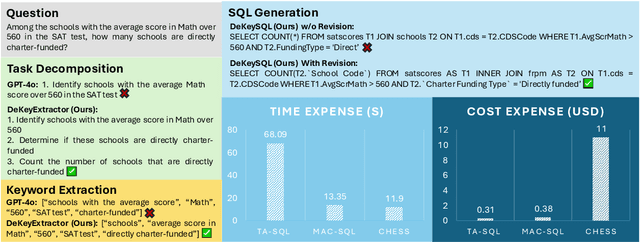
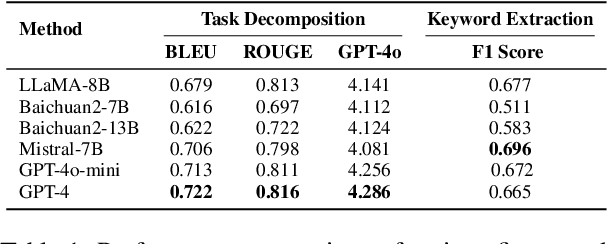


Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
Compliance-to-Code: Enhancing Financial Compliance Checking via Code Generation
May 26, 2025



Nowadays, regulatory compliance has become a cornerstone of corporate governance, ensuring adherence to systematic legal frameworks. At its core, financial regulations often comprise highly intricate provisions, layered logical structures, and numerous exceptions, which inevitably result in labor-intensive or comprehension challenges. To mitigate this, recent Regulatory Technology (RegTech) and Large Language Models (LLMs) have gained significant attention in automating the conversion of regulatory text into executable compliance logic. However, their performance remains suboptimal particularly when applied to Chinese-language financial regulations, due to three key limitations: (1) incomplete domain-specific knowledge representation, (2) insufficient hierarchical reasoning capabilities, and (3) failure to maintain temporal and logical coherence. One promising solution is to develop a domain specific and code-oriented datasets for model training. Existing datasets such as LexGLUE, LegalBench, and CODE-ACCORD are often English-focused, domain-mismatched, or lack fine-grained granularity for compliance code generation. To fill these gaps, we present Compliance-to-Code, the first large-scale Chinese dataset dedicated to financial regulatory compliance. Covering 1,159 annotated clauses from 361 regulations across ten categories, each clause is modularly structured with four logical elements-subject, condition, constraint, and contextual information-along with regulation relations. We provide deterministic Python code mappings, detailed code reasoning, and code explanations to facilitate automated auditing. To demonstrate utility, we present FinCheck: a pipeline for regulation structuring, code generation, and report generation.
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
May 01, 2025



As large language models (LLMs) evolve into tool-using agents, the ability to browse the web in real-time has become a critical yardstick for measuring their reasoning and retrieval competence. Existing benchmarks such as BrowseComp concentrate on English and overlook the linguistic, infrastructural, and censorship-related complexities of other major information ecosystems -- most notably Chinese. To address this gap, we introduce BrowseComp-ZH, a high-difficulty benchmark purpose-built to comprehensively evaluate LLM agents on the Chinese web. BrowseComp-ZH consists of 289 multi-hop questions spanning 11 diverse domains. Each question is reverse-engineered from a short, objective, and easily verifiable answer (e.g., a date, number, or proper noun). A two-stage quality control protocol is applied to strive for high question difficulty and answer uniqueness. We benchmark over 20 state-of-the-art language models and agentic search systems on our proposed BrowseComp-ZH. Despite their strong conversational and retrieval capabilities, most models struggle severely: a large number achieve accuracy rates below 10%, and only a handful exceed 20%. Even the best-performing system, OpenAI's DeepResearch, reaches just 42.9%. These results demonstrate the considerable difficulty of BrowseComp-ZH, where success demands not only effective retrieval strategies, but also sophisticated reasoning and information reconciliation -- capabilities that current models still struggle to master. Our dataset, construction guidelines, and benchmark results have been publicly released at https://github.com/PALIN2018/BrowseComp-ZH.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025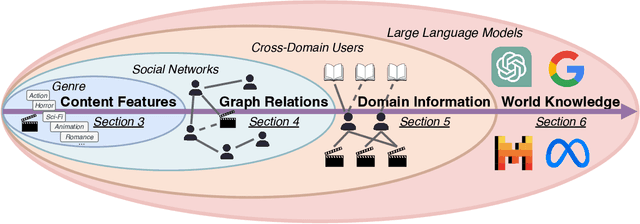
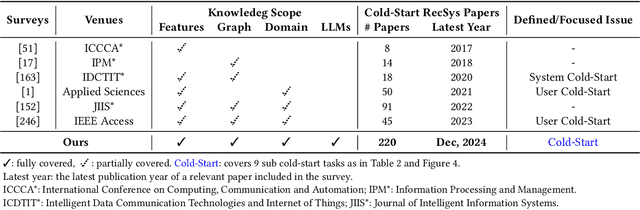
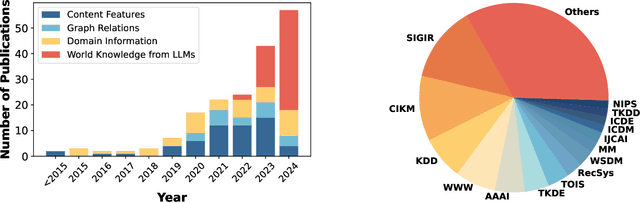
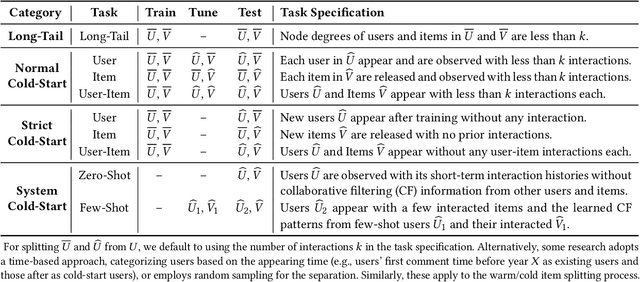
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
CellSeg1: Robust Cell Segmentation with One Training Image
Dec 02, 2024



Recent trends in cell segmentation have shifted towards universal models to handle diverse cell morphologies and imaging modalities. However, for continuously emerging cell types and imaging techniques, these models still require hundreds or thousands of annotated cells for fine-tuning. We introduce CellSeg1, a practical solution for segmenting cells of arbitrary morphology and modality with a few dozen cell annotations in 1 image. By adopting Low-Rank Adaptation of the Segment Anything Model (SAM), we achieve robust cell segmentation. Tested on 19 diverse cell datasets, CellSeg1 trained on 1 image achieved 0.81 average mAP at 0.5 IoU, performing comparably to existing models trained on over 500 images. It also demonstrated superior generalization in cross-dataset tests on TissueNet. We found that high-quality annotation of a few dozen densely packed cells of varied sizes is key to effective segmentation. CellSeg1 provides an efficient solution for cell segmentation with minimal annotation effort.