 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIPO: Gaussian Importance Sampling Policy Optimization
Mar 04, 2026Post-training with reinforcement learning (RL) has recently shown strong promise for advancing multimodal agents beyond supervised imitation. However, RL remains limited by poor data efficiency, particularly in settings where interaction data are scarce and quickly become outdated. To address this challenge, GIPO (Gaussian Importance sampling Policy Optimization) is proposed as a policy optimization objective based on truncated importance sampling, replacing hard clipping with a log-ratio-based Gaussian trust weight to softly damp extreme importance ratios while maintaining non-zero gradients. Theoretical analysis shows that GIPO introduces an implicit, tunable constraint on the update magnitude, while concentration bounds guarantee robustness and stability under finite-sample estimation. Experimental results show that GIPO achieves state-of-the-art performance among clipping-based baselines across a wide range of replay buffer sizes, from near on-policy to highly stale data, while exhibiting superior bias--variance trade-off, high training stability and improved sample efficiency.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
Dual Contrastive Attributed Graph Clustering Network
Jun 16, 2022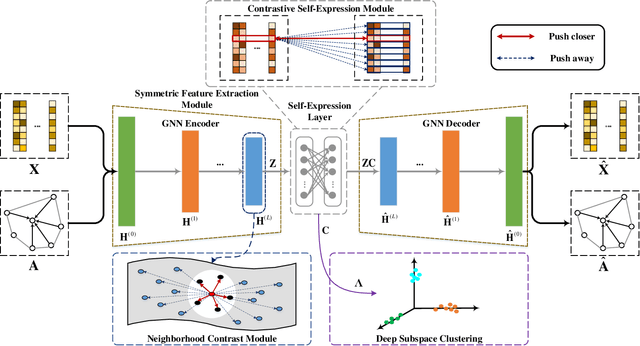
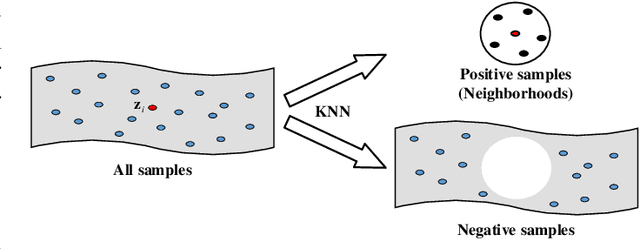

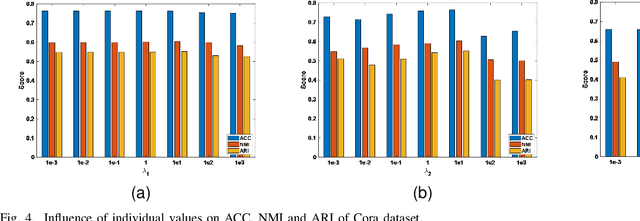
Attributed graph clustering is one of the most important tasks in graph analysis field, the goal of which is to group nodes with similar representations into the same cluster without manual guidance. Recent studies based on graph contrastive learning have achieved impressive results in processing graph-structured data. However, existing graph contrastive learning based methods 1) do not directly address the clustering task, since the representation learning and clustering process are separated; 2) depend too much on graph data augmentation, which greatly limits the capability of contrastive learning; 3) ignore the contrastive message for subspace clustering. To accommodate the aforementioned issues, we propose a generic framework called Dual Contrastive Attributed Graph Clustering Network (DCAGC). In DCAGC, by leveraging Neighborhood Contrast Module, the similarity of the neighbor nodes will be maximized and the quality of the node representation will be improved. Meanwhile, the Contrastive Self-Expression Module is built by minimizing the node representation before and after the reconstruction of the self-expression layer to obtain a discriminative self-expression matrix for spectral clustering. All the modules of DCAGC are trained and optimized in a unified framework, so the learned node representation contains clustering-oriented messages. Extensive experimental results on four attributed graph datasets show the superiority of DCAGC compared with 16 state-of-the-art clustering methods. The code of this paper is available at https://github.com/wangtong627/Dual-Contrastive-Attributed-Graph-Clustering-Network.