 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the PsyDefDetect Shared Task at BioNLP 2026: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
May 24, 2026We present an overview of PsyDefDetect, the shared task on detecting levels of psychological defense mechanisms in emotional support dialogues, co-located with BioNLP@ACL 2026. Grounded in the clinically validated Defense Mechanism Rating Scales (DMRS) framework, the task asks systems to classify a target seeker utterance, given its preceding dialogue context, into one of nine categories: seven hierarchical DMRS levels plus two auxiliary labels. Participants worked on PsyDefConv, a newly released corpus of 200 dialogues and 2336 help-seeker utterances annotated under DMRS with substantial inter-annotator agreement. The task attracted 172 participants on CodaBench who produced 563 submissions, with 21 teams officially registering their results for the final ranking. The best system achieved a macro F1-score of 0.420, surpassing the strongest fine-tuned baseline reported in the dataset paper by a notable margin, yet leaving clear headroom. Our analysis highlights (i) a persistent tendency to over-predict the majority High-Adaptive class, (ii) a widening gap between accuracy and macro-F1 that reveals class-imbalance sensitivity, and (iii) the value of theory-aware and LLM-based approaches for fine-grained defensive-function classification. We release all task materials and invite the community to continue work on this novel intersection of clinical psychology and NLP.
Design and Report Benchmarks for Knowledge Work
May 22, 2026The development of LLM agents has led to a growing body of work on knowledge-work AI, including coding, research, and healthcare. However, current knowledge-work evaluation and benchmark design still largely follow the logic of traditional NLP tasks. As a result, higher benchmark performance does not reliably show that a system can carry out knowledge work in real-world deployment settings. This paper contributes a three-step approach for making explicit how benchmarked tasks represent the work claims attached to their scores: defining the work activity under evaluation, specifying the tested setting, and scoring the appropriate work product. We review work studies showing that knowledge work is organized through roles and responsibilities, local materials and tools, and artifacts that must remain usable in downstream workflows. We then translate these concerns into benchmark design and reporting guidance, covering how tasks should be mapped to work activities, how tested settings should specify materials, tools, roles, and constraints, and how scoring should focus on the work product left by the system. To name the work activity being evaluated and distinguish it from common benchmark tasks, we derive an inventory of 18 work activities from the O{*}NET occupational task database. We demonstrate the approach through three benchmark case analyses: GDPval, a non-code occupational deliverable benchmark; OfficeQA Pro, a grounded document-analysis benchmark scored by final answers; and APEX-SWE, a software-engineering benchmark with executable scored products. These cases show how benchmark design choices shape the strongest work claim a score can support, and where gaps arise between the benchmarked task, tested setting, scored product, and broader work claim.
You Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025



Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
DeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
Sep 18, 2025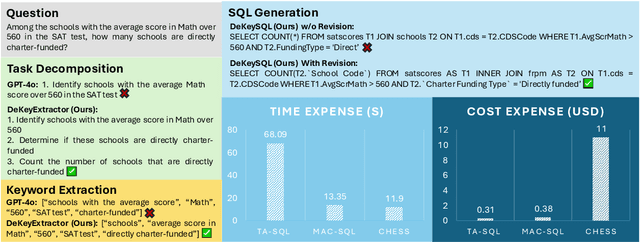
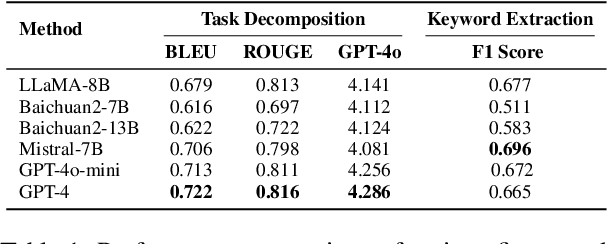


Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
May 01, 2025



As large language models (LLMs) evolve into tool-using agents, the ability to browse the web in real-time has become a critical yardstick for measuring their reasoning and retrieval competence. Existing benchmarks such as BrowseComp concentrate on English and overlook the linguistic, infrastructural, and censorship-related complexities of other major information ecosystems -- most notably Chinese. To address this gap, we introduce BrowseComp-ZH, a high-difficulty benchmark purpose-built to comprehensively evaluate LLM agents on the Chinese web. BrowseComp-ZH consists of 289 multi-hop questions spanning 11 diverse domains. Each question is reverse-engineered from a short, objective, and easily verifiable answer (e.g., a date, number, or proper noun). A two-stage quality control protocol is applied to strive for high question difficulty and answer uniqueness. We benchmark over 20 state-of-the-art language models and agentic search systems on our proposed BrowseComp-ZH. Despite their strong conversational and retrieval capabilities, most models struggle severely: a large number achieve accuracy rates below 10%, and only a handful exceed 20%. Even the best-performing system, OpenAI's DeepResearch, reaches just 42.9%. These results demonstrate the considerable difficulty of BrowseComp-ZH, where success demands not only effective retrieval strategies, but also sophisticated reasoning and information reconciliation -- capabilities that current models still struggle to master. Our dataset, construction guidelines, and benchmark results have been publicly released at https://github.com/PALIN2018/BrowseComp-ZH.
Riemannian Geometry for the classification of brain states with intracortical brain-computer interfaces
Apr 07, 2025This study investigates the application of Riemannian geometry-based methods for brain decoding using invasive electrophysiological recordings. Although previously employed in non-invasive, the utility of Riemannian geometry for invasive datasets, which are typically smaller and scarcer, remains less explored. Here, we propose a Minimum Distance to Mean (MDM) classifier using a Riemannian geometry approach based on covariance matrices extracted from intracortical Local Field Potential (LFP) recordings across various regions during different brain state dynamics. For benchmarking, we evaluated the performance of our approach against Convolutional Neural Networks (CNNs) and Euclidean MDM classifiers. Our results indicate that the Riemannian geometry-based classification not only achieves a superior mean F1 macro-averaged score across different channel configurations but also requires up to two orders of magnitude less computational training time. Additionally, the geometric framework reveals distinct spatial contributions of brain regions across varying brain states, suggesting a state-dependent organization that traditional time series-based methods often fail to capture. Our findings align with previous studies supporting the efficacy of geometry-based methods and extending their application to invasive brain recordings, highlighting their potential for broader clinical use, such as brain computer interface applications.
Detecting Conversational Mental Manipulation with Intent-Aware Prompting
Dec 11, 2024



Mental manipulation severely undermines mental wellness by covertly and negatively distorting decision-making. While there is an increasing interest in mental health care within the natural language processing community, progress in tackling manipulation remains limited due to the complexity of detecting subtle, covert tactics in conversations. In this paper, we propose Intent-Aware Prompting (IAP), a novel approach for detecting mental manipulations using large language models (LLMs), providing a deeper understanding of manipulative tactics by capturing the underlying intents of participants. Experimental results on the MentalManip dataset demonstrate superior effectiveness of IAP against other advanced prompting strategies. Notably, our approach substantially reduces false negatives, helping detect more instances of mental manipulation with minimal misjudgment of positive cases. The code of this paper is available at https://github.com/Anton-Jiayuan-MA/Manip-IAP.
Applying and Evaluating Large Language Models in Mental Health Care: A Scoping Review of Human-Assessed Generative Tasks
Aug 21, 2024



Large language models (LLMs) are emerging as promising tools for mental health care, offering scalable support through their ability to generate human-like responses. However, the effectiveness of these models in clinical settings remains unclear. This scoping review aimed to assess the current generative applications of LLMs in mental health care, focusing on studies where these models were tested with human participants in real-world scenarios. A systematic search across APA PsycNet, Scopus, PubMed, and Web of Science identified 726 unique articles, of which 17 met the inclusion criteria. These studies encompassed applications such as clinical assistance, counseling, therapy, and emotional support. However, the evaluation methods were often non-standardized, with most studies relying on ad hoc scales that limit comparability and robustness. Privacy, safety, and fairness were also frequently underexplored. Moreover, reliance on proprietary models, such as OpenAI's GPT series, raises concerns about transparency and reproducibility. While LLMs show potential in expanding mental health care access, especially in underserved areas, the current evidence does not fully support their use as standalone interventions. More rigorous, standardized evaluations and ethical oversight are needed to ensure these tools can be safely and effectively integrated into clinical practice.
Vision-Language Models Meet Meteorology: Developing Models for Extreme Weather Events Detection with Heatmaps
Jun 14, 2024



Real-time detection and prediction of extreme weather protect human lives and infrastructure. Traditional methods rely on numerical threshold setting and manual interpretation of weather heatmaps with Geographic Information Systems (GIS), which can be slow and error-prone. Our research redefines Extreme Weather Events Detection (EWED) by framing it as a Visual Question Answering (VQA) problem, thereby introducing a more precise and automated solution. Leveraging Vision-Language Models (VLM) to simultaneously process visual and textual data, we offer an effective aid to enhance the analysis process of weather heatmaps. Our initial assessment of general-purpose VLMs (e.g., GPT-4-Vision) on EWED revealed poor performance, characterized by low accuracy and frequent hallucinations due to inadequate color differentiation and insufficient meteorological knowledge. To address these challenges, we introduce ClimateIQA, the first meteorological VQA dataset, which includes 8,760 wind gust heatmaps and 254,040 question-answer pairs covering four question types, both generated from the latest climate reanalysis data. We also propose Sparse Position and Outline Tracking (SPOT), an innovative technique that leverages OpenCV and K-Means clustering to capture and depict color contours in heatmaps, providing ClimateIQA with more accurate color spatial location information. Finally, we present Climate-Zoo, the first meteorological VLM collection, which adapts VLMs to meteorological applications using the ClimateIQA dataset. Experiment results demonstrate that models from Climate-Zoo substantially outperform state-of-the-art general VLMs, achieving an accuracy increase from 0% to over 90% in EWED verification. The datasets and models in this study are publicly available for future climate science research: https://github.com/AlexJJJChen/Climate-Zoo.
FinTextQA: A Dataset for Long-form Financial Question Answering
May 16, 2024



Accurate evaluation of financial question answering (QA) systems necessitates a comprehensive dataset encompassing diverse question types and contexts. However, current financial QA datasets lack scope diversity and question complexity. This work introduces FinTextQA, a novel dataset for long-form question answering (LFQA) in finance. FinTextQA comprises 1,262 high-quality, source-attributed QA pairs extracted and selected from finance textbooks and government agency websites.Moreover, we developed a Retrieval-Augmented Generation (RAG)-based LFQA system, comprising an embedder, retriever, reranker, and generator. A multi-faceted evaluation approach, including human ranking, automatic metrics, and GPT-4 scoring, was employed to benchmark the performance of different LFQA system configurations under heightened noisy conditions. The results indicate that: (1) Among all compared generators, Baichuan2-7B competes closely with GPT-3.5-turbo in accuracy score; (2) The most effective system configuration on our dataset involved setting the embedder, retriever, reranker, and generator as Ada2, Automated Merged Retrieval, Bge-Reranker-Base, and Baichuan2-7B, respectively; (3) models are less susceptible to noise after the length of contexts reaching a specific threshold.