 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Generative Model for Scarce Time Series with Domain Experts
Jun 13, 2026Synthesizing realistic time series with generative models has wide-ranging applications in real-world scenarios. Despite recent progress, most existing methods are trained under the assumption of abundant training data, which substantially limits their effectiveness in data-scarce settings. In this paper, we propose TimeMoDE, a novel framework that integrates Diffusion Transformers with Mixture-of-Experts to exploit both domain adaptability and diffusion-stage awareness for time series generation under data scarcity. It is pre-trained on a large-scale collection of multi-domain datasets to extract domain-agnostic temporal representations and domain-specific information benefiting generalization during fine-tuning. We propose Domain Prompts to condition expert assignment for indistinguishable noised tokens, mitigating the limitations of capturing inter-dataset relationships. Moreover, we incorporate diffusion timestep signals to equip the experts with awareness of time series degradation variations, facilitating adaptive calibrate to stage-dependent denoising requirements. Extensive experiments demonstrate that TimeMoDE outperforms existing methods under diverse low-data settings. It establishes an innovative paradigm for advanced time series few-shot generation.
MPDocBench-Parse: Benchmarking Practical Multi-page Document Parsing
May 21, 2026Document parsing converts visually rich documents into machine-readable structured representations, forming a crucial foundation for information systems. Although many benchmarks have been proposed for document parsing, they remain inadequate for realistic scenarios. Existing benchmarks either focus on specific tasks or assess only single-page, text-centric settings, making them insufficient for practical multi-page parsing. Moreover, they lack fine-grained evaluation of semantic continuity, hierarchical structure recovery, and visual content preservation. To address these gaps, we propose MPDocBench-Parse, a benchmark for multi-page document parsing in real-world applications. It contains 433 manually annotated documents with 3,246 pages, covering 15 document types in English and Chinese, with diverse layout styles, and supports document-level end-to-end evaluation. We further design a comprehensive protocol for content fidelity and logical structure, covering text, table, and formula recognition, truncated text and table merging, figure extraction, reading order, and heading hierarchy recovery. Experiments show that, while existing models perform well on basic text extraction, they still suffer clear limitations in semantic continuity integration, visual content parsing, and hierarchical structure recovery. MPDocBench-Parse provides a unified foundation for advancing document parsing toward more realistic scenarios.
Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Feb 15, 2026The paper introduces GUI-Owl-1.5, the latest native GUI agent model that features instruct/thinking variants in multiple sizes (2B/4B/8B/32B/235B) and supports a range of platforms (desktop, mobile, browser, and more) to enable cloud-edge collaboration and real-time interaction. GUI-Owl-1.5 achieves state-of-the-art results on more than 20+ GUI benchmarks on open-source models: (1) on GUI automation tasks, it obtains 56.5 on OSWorld, 71.6 on AndroidWorld, and 48.4 on WebArena; (2) on grounding tasks, it obtains 80.3 on ScreenSpotPro; (3) on tool-calling tasks, it obtains 47.6 on OSWorld-MCP, and 46.8 on MobileWorld; (4) on memory and knowledge tasks, it obtains 75.5 on GUI-Knowledge Bench. GUI-Owl-1.5 incorporates several key innovations: (1) Hybird Data Flywheel: we construct the data pipeline for UI understanding and trajectory generation based on a combination of simulated environments and cloud-based sandbox environments, in order to improve the efficiency and quality of data collection. (2) Unified Enhancement of Agent Capabilities: we use a unified thought-synthesis pipeline to enhance the model's reasoning capabilities, while placing particular emphasis on improving key agent abilities, including Tool/MCP use, memory and multi-agent adaptation; (3) Multi-platform Environment RL Scaling: We propose a new environment RL algorithm, MRPO, to address the challenges of multi-platform conflicts and the low training efficiency of long-horizon tasks. The GUI-Owl-1.5 models are open-sourced, and an online cloud-sandbox demo is available at https://github.com/X-PLUG/MobileAgent.
Vector-Valued Distributional Reinforcement Learning Policy Evaluation: A Hilbert Space Embedding Approach
Jan 26, 2026We propose an (offline) multi-dimensional distributional reinforcement learning framework (KE-DRL) that leverages Hilbert space mappings to estimate the kernel mean embedding of the multi-dimensional value distribution under a proposed target policy. In our setting, the state-action variables are multi-dimensional and continuous. By mapping probability measures into a reproducing kernel Hilbert space via kernel mean embeddings, our method replaces Wasserstein metrics with an integral probability metric. This enables efficient estimation in multi-dimensional state-action spaces and reward settings, where direct computation of Wasserstein distances is computationally challenging. Theoretically, we establish contraction properties of the distributional Bellman operator under our proposed metric involving the Matern family of kernels and provide uniform convergence guarantees. Simulations and empirical results demonstrate robust off-policy evaluation and recovery of the kernel mean embedding under mild assumptions, namely, Lipschitz continuity and boundedness of the kernels, highlighting the potential of embedding-based approaches in complex real-world decision-making scenarios and risk evaluation.
A Visual Semantic Adaptive Watermark grounded by Prefix-Tuning for Large Vision-Language Model
Jan 12, 2026Watermarking has emerged as a pivotal solution for content traceability and intellectual property protection in Large Vision-Language Models (LVLMs). However, vision-agnostic watermarks introduce visually irrelevant tokens and disrupt visual grounding by enforcing indiscriminate pseudo-random biases, while some semantic-aware methods incur prohibitive inference latency due to rejection sampling. In this paper, we propose the VIsual Semantic Adaptive Watermark (VISA-Mark), a novel framework that embeds detectable signals while strictly preserving visual fidelity. Our approach employs a lightweight, efficiently trained prefix-tuner to extract dynamic Visual-Evidence Weights, which quantify the evidentiary support for candidate tokens based on the visual input. These weights guide an adaptive vocabulary partitioning and logits perturbation mechanism, concentrating watermark strength specifically on visually-supported tokens. By actively aligning the watermark with visual evidence, VISA-Mark effectively maintains visual fidelity. Empirical results confirm that VISA-Mark outperforms conventional methods with a 7.8% improvement in visual consistency (Chair-I) and superior semantic fidelity. The framework maintains highly competitive detection accuracy (96.88% AUC) and robust attack resilience (99.3%) without sacrificing inference efficiency, effectively establishing a new standard for reliability-preserving multimodal watermarking.
Distilling the Thought, Watermarking the Answer: A Principle Semantic Guided Watermark for Large Reasoning Models
Jan 08, 2026Reasoning Large Language Models (RLLMs) excelling in complex tasks present unique challenges for digital watermarking, as existing methods often disrupt logical coherence or incur high computational costs. Token-based watermarking techniques can corrupt the reasoning flow by applying pseudo-random biases, while semantic-aware approaches improve quality but introduce significant latency or require auxiliary models. This paper introduces ReasonMark, a novel watermarking framework specifically designed for reasoning-intensive LLMs. Our approach decouples generation into an undisturbed Thinking Phase and a watermarked Answering Phase. We propose a Criticality Score to identify semantically pivotal tokens from the reasoning trace, which are distilled into a Principal Semantic Vector (PSV). The PSV then guides a semantically-adaptive mechanism that modulates watermark strength based on token-PSV alignment, ensuring robustness without compromising logical integrity. Extensive experiments show ReasonMark surpasses state-of-the-art methods by reducing text Perplexity by 0.35, increasing translation BLEU score by 0.164, and raising mathematical accuracy by 0.67 points. These advancements are achieved alongside a 0.34% higher watermark detection AUC and stronger robustness to attacks, all with a negligible increase in latency. This work enables the traceable and trustworthy deployment of reasoning LLMs in real-world applications.
GRACE: Designing Generative Face Video Codec via Agile Hardware-Centric Workflow
Nov 12, 2025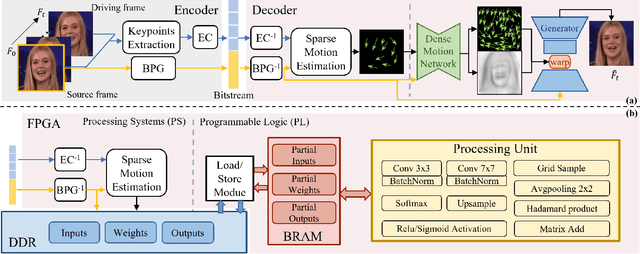



The Animation-based Generative Codec (AGC) is an emerging paradigm for talking-face video compression. However, deploying its intricate decoder on resource and power-constrained edge devices presents challenges due to numerous parameters, the inflexibility to adapt to dynamically evolving algorithms, and the high power consumption induced by extensive computations and data transmission. This paper for the first time proposes a novel field programmable gate arrays (FPGAs)-oriented AGC deployment scheme for edge-computing video services. Initially, we analyze the AGC algorithm and employ network compression methods including post-training static quantization and layer fusion techniques. Subsequently, we design an overlapped accelerator utilizing the co-processor paradigm to perform computations through software-hardware co-design. The hardware processing unit comprises engines such as convolution, grid sampling, upsample, etc. Parallelization optimization strategies like double-buffered pipelines and loop unrolling are employed to fully exploit the resources of FPGA. Ultimately, we establish an AGC FPGA prototype on the PYNQ-Z1 platform using the proposed scheme, achieving \textbf{24.9$\times$} and \textbf{4.1$\times$} higher energy efficiency against commercial Central Processing Unit (CPU) and Graphic Processing Unit (GPU), respectively. Specifically, only \textbf{11.7} microjoules ($\upmu$J) are required for one pixel reconstructed by this FPGA system.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025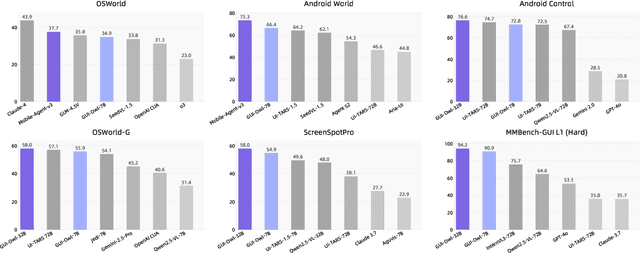
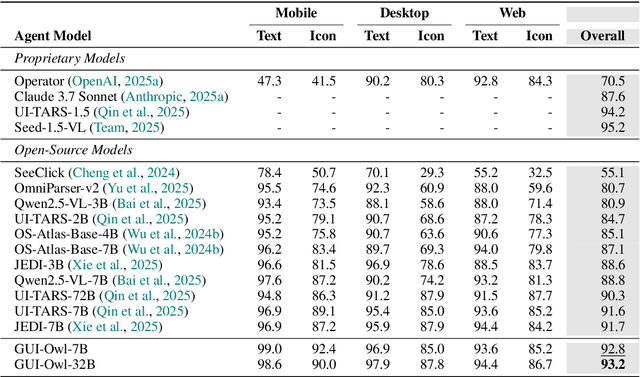
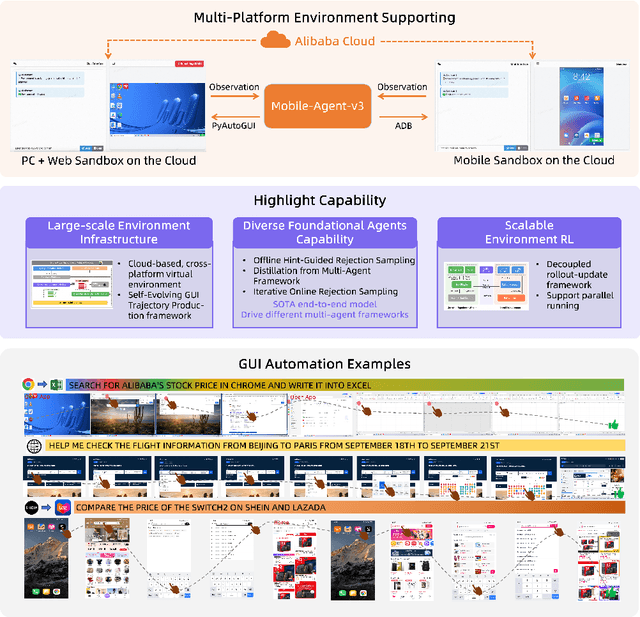
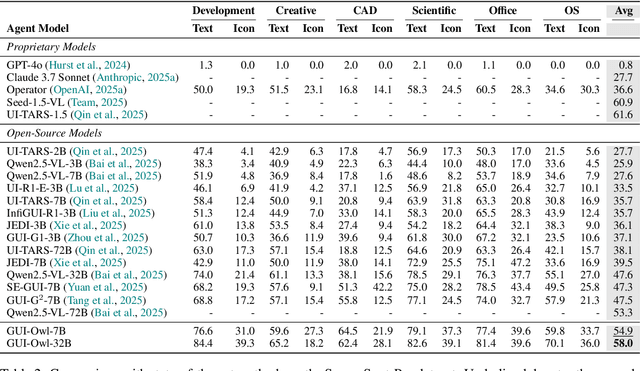
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
VLA-Mark: A cross modal watermark for large vision-language alignment model
Jul 18, 2025



Vision-language models demand watermarking solutions that protect intellectual property without compromising multimodal coherence. Existing text watermarking methods disrupt visual-textual alignment through biased token selection and static strategies, leaving semantic-critical concepts vulnerable. We propose VLA-Mark, a vision-aligned framework that embeds detectable watermarks while preserving semantic fidelity through cross-modal coordination. Our approach integrates multiscale visual-textual alignment metrics, combining localized patch affinity, global semantic coherence, and contextual attention patterns, to guide watermark injection without model retraining. An entropy-sensitive mechanism dynamically balances watermark strength and semantic preservation, prioritizing visual grounding during low-uncertainty generation phases. Experiments show 7.4% lower PPL and 26.6% higher BLEU than conventional methods, with near-perfect detection (98.8% AUC). The framework demonstrates 96.1\% attack resilience against attacks such as paraphrasing and synonym substitution, while maintaining text-visual consistency, establishing new standards for quality-preserving multimodal watermarking
4KAgent: Agentic Any Image to 4K Super-Resolution
Jul 09, 2025We present 4KAgent, a unified agentic super-resolution generalist system designed to universally upscale any image to 4K resolution (and even higher, if applied iteratively). Our system can transform images from extremely low resolutions with severe degradations, for example, highly distorted inputs at 256x256, into crystal-clear, photorealistic 4K outputs. 4KAgent comprises three core components: (1) Profiling, a module that customizes the 4KAgent pipeline based on bespoke use cases; (2) A Perception Agent, which leverages vision-language models alongside image quality assessment experts to analyze the input image and make a tailored restoration plan; and (3) A Restoration Agent, which executes the plan, following a recursive execution-reflection paradigm, guided by a quality-driven mixture-of-expert policy to select the optimal output for each step. Additionally, 4KAgent embeds a specialized face restoration pipeline, significantly enhancing facial details in portrait and selfie photos. We rigorously evaluate our 4KAgent across 11 distinct task categories encompassing a total of 26 diverse benchmarks, setting new state-of-the-art on a broad spectrum of imaging domains. Our evaluations cover natural images, portrait photos, AI-generated content, satellite imagery, fluorescence microscopy, and medical imaging like fundoscopy, ultrasound, and X-ray, demonstrating superior performance in terms of both perceptual (e.g., NIQE, MUSIQ) and fidelity (e.g., PSNR) metrics. By establishing a novel agentic paradigm for low-level vision tasks, we aim to catalyze broader interest and innovation within vision-centric autonomous agents across diverse research communities. We will release all the code, models, and results at: https://4kagent.github.io.