 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
Sep 18, 2025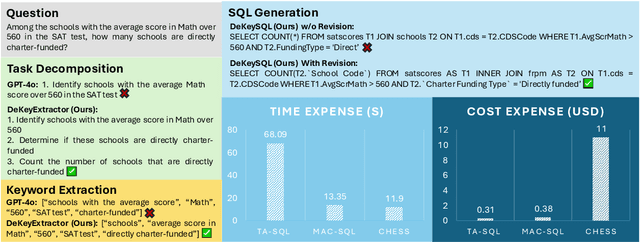
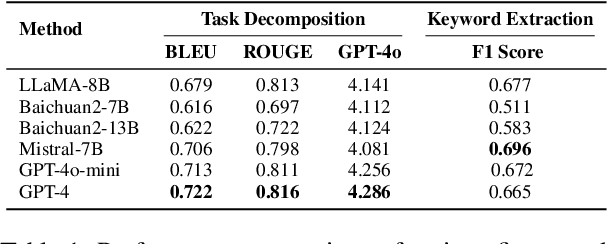


Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.
Exploring What Why and How: A Multifaceted Benchmark for Causation Understanding of Video Anomaly
Dec 10, 2024



Recent advancements in video anomaly understanding (VAU) have opened the door to groundbreaking applications in various fields, such as traffic monitoring and industrial automation. While the current benchmarks in VAU predominantly emphasize the detection and localization of anomalies. Here, we endeavor to delve deeper into the practical aspects of VAU by addressing the essential questions: "what anomaly occurred?", "why did it happen?", and "how severe is this abnormal event?". In pursuit of these answers, we introduce a comprehensive benchmark for Exploring the Causation of Video Anomalies (ECVA). Our benchmark is meticulously designed, with each video accompanied by detailed human annotations. Specifically, each instance of our ECVA involves three sets of human annotations to indicate "what", "why" and "how" of an anomaly, including 1) anomaly type, start and end times, and event descriptions, 2) natural language explanations for the cause of an anomaly, and 3) free text reflecting the effect of the abnormality. Building upon this foundation, we propose a novel prompt-based methodology that serves as a baseline for tackling the intricate challenges posed by ECVA. We utilize "hard prompt" to guide the model to focus on the critical parts related to video anomaly segments, and "soft prompt" to establish temporal and spatial relationships within these anomaly segments. Furthermore, we propose AnomEval, a specialized evaluation metric crafted to align closely with human judgment criteria for ECVA. This metric leverages the unique features of the ECVA dataset to provide a more comprehensive and reliable assessment of various video large language models. We demonstrate the efficacy of our approach through rigorous experimental analysis and delineate possible avenues for further investigation into the comprehension of video anomaly causation.