 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
Jul 24, 2025



Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators. Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications. To circumvent this inherent drawback, we propose Adversarial Distribution Matching (ADM), a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner. In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces. Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage. By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed DMDX, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time. Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.
VividDreamer: Towards High-Fidelity and Efficient Text-to-3D Generation
Jun 21, 2024



Text-to-3D generation aims to create 3D assets from text-to-image diffusion models. However, existing methods face an inherent bottleneck in generation quality because the widely-used objectives such as Score Distillation Sampling (SDS) inappropriately omit U-Net jacobians for swift generation, leading to significant bias compared to the "true" gradient obtained by full denoising sampling. This bias brings inconsistent updating direction, resulting in implausible 3D generation e.g., color deviation, Janus problem, and semantically inconsistent details). In this work, we propose Pose-dependent Consistency Distillation Sampling (PCDS), a novel yet efficient objective for diffusion-based 3D generation tasks. Specifically, PCDS builds the pose-dependent consistency function within diffusion trajectories, allowing to approximate true gradients through minimal sampling steps (1-3). Compared to SDS, PCDS can acquire a more accurate updating direction with the same sampling time (1 sampling step), while enabling few-step (2-3) sampling to trade compute for higher generation quality. For efficient generation, we propose a coarse-to-fine optimization strategy, which first utilizes 1-step PCDS to create the basic structure of 3D objects, and then gradually increases PCDS steps to generate fine-grained details. Extensive experiments demonstrate that our approach outperforms the state-of-the-art in generation quality and training efficiency, conspicuously alleviating the implausible 3D generation issues caused by the deviated updating direction. Moreover, it can be simply applied to many 3D generative applications to yield impressive 3D assets, please see our project page: https://narcissusex.github.io/VividDreamer.
CoCPF: Coordinate-based Continuous Projection Field for Ill-Posed Inverse Problem in Imaging
Jun 21, 2024



Sparse-view computed tomography (SVCT) reconstruction aims to acquire CT images based on sparsely-sampled measurements. It allows the subjects exposed to less ionizing radiation, reducing the lifetime risk of developing cancers. Recent researches employ implicit neural representation (INR) techniques to reconstruct CT images from a single SV sinogram. However, due to ill-posedness, these INR-based methods may leave considerable ``holes'' (i.e., unmodeled spaces) in their fields, leading to sub-optimal results. In this paper, we propose the Coordinate-based Continuous Projection Field (CoCPF), which aims to build hole-free representation fields for SVCT reconstruction, achieving better reconstruction quality. Specifically, to fill the holes, CoCPF first employs the stripe-based volume sampling module to broaden the sampling regions of Radon transformation from rays (1D space) to stripes (2D space), which can well cover the internal regions between SV projections. Then, by feeding the sampling regions into the proposed differentiable rendering modules, the holes can be jointly optimized during training, reducing the ill-posed levels. As a result, CoCPF can accurately estimate the internal measurements between SV projections (i.e., DV sinograms), producing high-quality CT images after re-projection. Extensive experiments on simulated and real projection datasets demonstrate that CoCPF outperforms state-of-the-art methods for 2D and 3D SVCT reconstructions under various projection numbers and geometries, yielding fine-grained details and fewer artifacts. Our code will be publicly available.
Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
Feb 28, 2024



Diffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of the pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available at https://github.com/YanzuoLu/CFLD.
Attention-based Interactive Disentangling Network for Instance-level Emotional Voice Conversion
Dec 29, 2023



Emotional Voice Conversion aims to manipulate a speech according to a given emotion while preserving non-emotion components. Existing approaches cannot well express fine-grained emotional attributes. In this paper, we propose an Attention-based Interactive diseNtangling Network (AINN) that leverages instance-wise emotional knowledge for voice conversion. We introduce a two-stage pipeline to effectively train our network: Stage I utilizes inter-speech contrastive learning to model fine-grained emotion and intra-speech disentanglement learning to better separate emotion and content. In Stage II, we propose to regularize the conversion with a multi-view consistency mechanism. This technique helps us transfer fine-grained emotion and maintain speech content. Extensive experiments show that our AINN outperforms state-of-the-arts in both objective and subjective metrics.
MLNet: Mutual Learning Network with Neighborhood Invariance for Universal Domain Adaptation
Dec 21, 2023



Universal domain adaptation (UniDA) is a practical but challenging problem, in which information about the relation between the source and the target domains is not given for knowledge transfer. Existing UniDA methods may suffer from the problems of overlooking intra-domain variations in the target domain and difficulty in separating between the similar known and unknown class. To address these issues, we propose a novel Mutual Learning Network (MLNet) with neighborhood invariance for UniDA. In our method, confidence-guided invariant feature learning with self-adaptive neighbor selection is designed to reduce the intra-domain variations for more generalizable feature representation. By using the cross-domain mixup scheme for better unknown-class identification, the proposed method compensates for the misidentified known-class errors by mutual learning between the closed-set and open-set classifiers. Extensive experiments on three publicly available benchmarks demonstrate that our method achieves the best results compared to the state-of-the-arts in most cases and significantly outperforms the baseline across all the four settings in UniDA. Code is available at https://github.com/YanzuoLu/MLNet.
HomoGCL: Rethinking Homophily in Graph Contrastive Learning
Jun 16, 2023



Contrastive learning (CL) has become the de-facto learning paradigm in self-supervised learning on graphs, which generally follows the "augmenting-contrasting" learning scheme. However, we observe that unlike CL in computer vision domain, CL in graph domain performs decently even without augmentation. We conduct a systematic analysis of this phenomenon and argue that homophily, i.e., the principle that "like attracts like", plays a key role in the success of graph CL. Inspired to leverage this property explicitly, we propose HomoGCL, a model-agnostic framework to expand the positive set using neighbor nodes with neighbor-specific significances. Theoretically, HomoGCL introduces a stricter lower bound of the mutual information between raw node features and node embeddings in augmented views. Furthermore, HomoGCL can be combined with existing graph CL models in a plug-and-play way with light extra computational overhead. Extensive experiments demonstrate that HomoGCL yields multiple state-of-the-art results across six public datasets and consistently brings notable performance improvements when applied to various graph CL methods. Code is avilable at https://github.com/wenzhilics/HomoGCL.
GraphSHA: Synthesizing Harder Samples for Class-Imbalanced Node Classification
Jun 16, 2023



Class imbalance is the phenomenon that some classes have much fewer instances than others, which is ubiquitous in real-world graph-structured scenarios. Recent studies find that off-the-shelf Graph Neural Networks (GNNs) would under-represent minor class samples. We investigate this phenomenon and discover that the subspaces of minor classes being squeezed by those of the major ones in the latent space is the main cause of this failure. We are naturally inspired to enlarge the decision boundaries of minor classes and propose a general framework GraphSHA by Synthesizing HArder minor samples. Furthermore, to avoid the enlarged minor boundary violating the subspaces of neighbor classes, we also propose a module called SemiMixup to transmit enlarged boundary information to the interior of the minor classes while blocking information propagation from minor classes to neighbor classes. Empirically, GraphSHA shows its effectiveness in enlarging the decision boundaries of minor classes, as it outperforms various baseline methods in class-imbalanced node classification with different GNN backbone encoders over seven public benchmark datasets. Code is avilable at https://github.com/wenzhilics/GraphSHA.
One-step Bipartite Graph Cut: A Normalized Formulation and Its Application to Scalable Subspace Clustering
May 12, 2023



The bipartite graph structure has shown its promising ability in facilitating the subspace clustering and spectral clustering algorithms for large-scale datasets. To avoid the post-processing via k-means during the bipartite graph partitioning, the constrained Laplacian rank (CLR) is often utilized for constraining the number of connected components (i.e., clusters) in the bipartite graph, which, however, neglects the distribution (or normalization) of these connected components and may lead to imbalanced or even ill clusters. Despite the significant success of normalized cut (Ncut) in general graphs, it remains surprisingly an open problem how to enforce a one-step normalized cut for bipartite graphs, especially with linear-time complexity. In this paper, we first characterize a novel one-step bipartite graph cut (OBCut) criterion with normalized constraints, and theoretically prove its equivalence to a trace maximization problem. Then we extend this cut criterion to a scalable subspace clustering approach, where adaptive anchor learning, bipartite graph learning, and one-step normalized bipartite graph partitioning are simultaneously modeled in a unified objective function, and an alternating optimization algorithm is further designed to solve it in linear time. Experiments on a variety of general and large-scale datasets demonstrate the effectiveness and scalability of our approach.
Adaptively-weighted Integral Space for Fast Multiview Clustering
Aug 25, 2022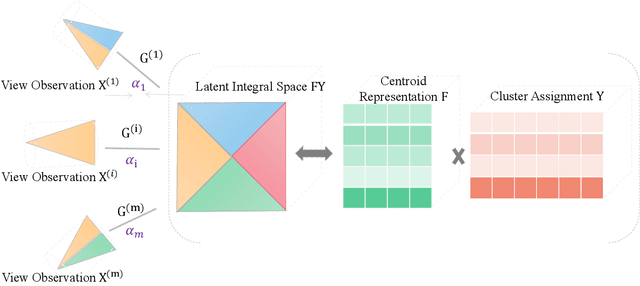
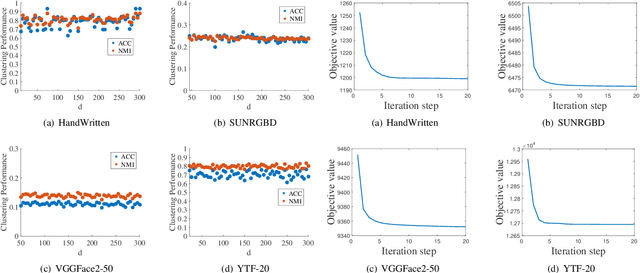
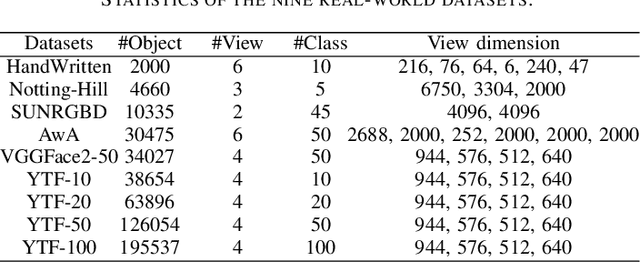
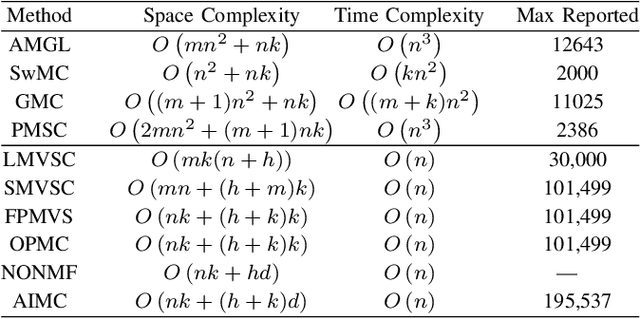
Multiview clustering has been extensively studied to take advantage of multi-source information to improve the clustering performance. In general, most of the existing works typically compute an n * n affinity graph by some similarity/distance metrics (e.g. the Euclidean distance) or learned representations, and explore the pairwise correlations across views. But unfortunately, a quadratic or even cubic complexity is often needed, bringing about difficulty in clustering largescale datasets. Some efforts have been made recently to capture data distribution in multiple views by selecting view-wise anchor representations with k-means, or by direct matrix factorization on the original observations. Despite the significant success, few of them have considered the view-insufficiency issue, implicitly holding the assumption that each individual view is sufficient to recover the cluster structure. Moreover, the latent integral space as well as the shared cluster structure from multiple insufficient views is not able to be simultaneously discovered. In view of this, we propose an Adaptively-weighted Integral Space for Fast Multiview Clustering (AIMC) with nearly linear complexity. Specifically, view generation models are designed to reconstruct the view observations from the latent integral space with diverse adaptive contributions. Meanwhile, a centroid representation with orthogonality constraint and cluster partition are seamlessly constructed to approximate the latent integral space. An alternate minimizing algorithm is developed to solve the optimization problem, which is proved to have linear time complexity w.r.t. the sample size. Extensive experiments conducted on several realworld datasets confirm the superiority of the proposed AIMC method compared with the state-of-the-art methods.