 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Unrolling in Omni Models
Apr 23, 2026We present Omni, a unified multimodal model natively trained on diverse modalities, including text, images, videos, 3D geometry, and hidden representations. We find that such training enables Context Unrolling, where the model explicitly reasons across multiple modal representations before producing predictions. This process enables the model to aggregate complementary information across heterogeneous modalities, facilitating a more faithful approximation of the shared multimodal knowledge manifold and improving downstream reasoning fidelity. As a result, Omni achieves strong performance on both multimodal generation and understanding benchmarks, while demonstrating advanced multimodal reasoning capabilities, including in-context generation of text, image, video, and 3D geometry.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Continuous Adversarial Flow Models
Apr 13, 2026We propose continuous adversarial flow models, a type of continuous-time flow model trained with an adversarial objective. Unlike flow matching, which uses a fixed mean-squared-error criterion, our approach introduces a learned discriminator to guide training. This change in objective induces a different generalized distribution, which empirically produces samples that are better aligned with the target data distribution. Our method is primarily proposed for post-training existing flow-matching models, although it can also train models from scratch. On the ImageNet 256px generation task, our post-training substantially improves the guidance-free FID of latent-space SiT from 8.26 to 3.63 and of pixel-space JiT from 7.17 to 3.57. It also improves guided generation, reducing FID from 2.06 to 1.53 for SiT and from 1.86 to 1.80 for JiT. We further evaluate our approach on text-to-image generation, where it achieves improved results on both the GenEval and DPG benchmarks.
UniWeTok: An Unified Binary Tokenizer with Codebook Size $\mathit{2^{128}}$ for Unified Multimodal Large Language Model
Feb 15, 2026Unified Multimodal Large Language Models (MLLMs) require a visual representation that simultaneously supports high-fidelity reconstruction, complex semantic extraction, and generative suitability. However, existing visual tokenizers typically struggle to satisfy these conflicting objectives within a single framework. In this paper, we introduce UniWeTok, a unified discrete tokenizer designed to bridge this gap using a massive binary codebook ($\mathit{2^{128}}$). For training framework, we introduce Pre-Post Distillation and a Generative-Aware Prior to enhance the semantic extraction and generative prior of the discrete tokens. In terms of model architecture, we propose a convolution-attention hybrid architecture with the SigLu activation function. SigLu activation not only bounds the encoder output and stabilizes the semantic distillation process but also effectively addresses the optimization conflict between token entropy loss and commitment loss. We further propose a three-stage training framework designed to enhance UniWeTok's adaptability cross various image resolutions and perception-sensitive scenarios, such as those involving human faces and textual content. On ImageNet, UniWeTok achieves state-of-the-art image generation performance (FID: UniWeTok 1.38 vs. REPA 1.42) while requiring a remarkably low training compute (Training Tokens: UniWeTok 33B vs. REPA 262B). On general-domain, UniWeTok demonstrates highly competitive capabilities across a broad range of tasks, including multimodal understanding, image generation (DPG Score: UniWeTok 86.63 vs. FLUX.1 [Dev] 83.84), and editing (GEdit Overall Score: UniWeTok 5.09 vs. OmniGen 5.06). We release code and models to facilitate community exploration of unified tokenizer and MLLM.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Growing Visual Generative Capacity for Pre-Trained MLLMs
Oct 02, 2025Multimodal large language models (MLLMs) extend the success of language models to visual understanding, and recent efforts have sought to build unified MLLMs that support both understanding and generation. However, constructing such models remains challenging: hybrid approaches combine continuous embeddings with diffusion or flow-based objectives, producing high-quality images but breaking the autoregressive paradigm, while pure autoregressive approaches unify text and image prediction over discrete visual tokens but often face trade-offs between semantic alignment and pixel-level fidelity. In this work, we present Bridge, a pure autoregressive unified MLLM that augments pre-trained visual understanding models with generative ability through a Mixture-of-Transformers architecture, enabling both image understanding and generation within a single next-token prediction framework. To further improve visual generation fidelity, we propose a semantic-to-pixel discrete representation that integrates compact semantic tokens with fine-grained pixel tokens, achieving strong language alignment and precise description of visual details with only a 7.9% increase in sequence length. Extensive experiments across diverse multimodal benchmarks demonstrate that Bridge achieves competitive or superior results in both understanding and generation benchmarks, while requiring less training data and reduced training time compared to prior unified MLLMs.
Adversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
Jul 24, 2025



Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators. Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications. To circumvent this inherent drawback, we propose Adversarial Distribution Matching (ADM), a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner. In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces. Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage. By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed DMDX, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time. Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.
VINCIE: Unlocking In-context Image Editing from Video
Jun 12, 2025In-context image editing aims to modify images based on a contextual sequence comprising text and previously generated images. Existing methods typically depend on task-specific pipelines and expert models (e.g., segmentation and inpainting) to curate training data. In this work, we explore whether an in-context image editing model can be learned directly from videos. We introduce a scalable approach to annotate videos as interleaved multimodal sequences. To effectively learn from this data, we design a block-causal diffusion transformer trained on three proxy tasks: next-image prediction, current segmentation prediction, and next-segmentation prediction. Additionally, we propose a novel multi-turn image editing benchmark to advance research in this area. Extensive experiments demonstrate that our model exhibits strong in-context image editing capabilities and achieves state-of-the-art results on two multi-turn image editing benchmarks. Despite being trained exclusively on videos, our model also shows promising abilities in multi-concept composition, story generation, and chain-of-editing applications.
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Jun 11, 2025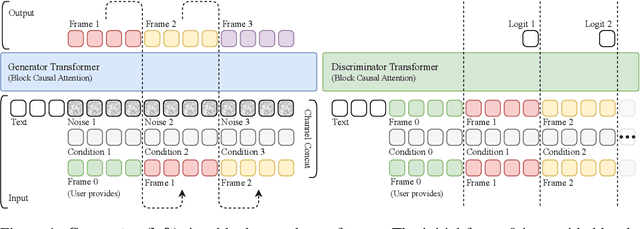
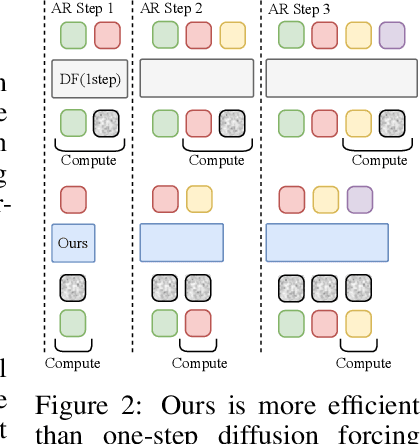
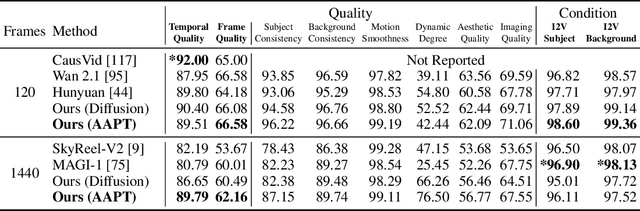

Existing large-scale video generation models are computationally intensive, preventing adoption in real-time and interactive applications. In this work, we propose autoregressive adversarial post-training (AAPT) to transform a pre-trained latent video diffusion model into a real-time, interactive video generator. Our model autoregressively generates a latent frame at a time using a single neural function evaluation (1NFE). The model can stream the result to the user in real time and receive interactive responses as controls to generate the next latent frame. Unlike existing approaches, our method explores adversarial training as an effective paradigm for autoregressive generation. This not only allows us to design an architecture that is more efficient for one-step generation while fully utilizing the KV cache, but also enables training the model in a student-forcing manner that proves to be effective in reducing error accumulation during long video generation. Our experiments demonstrate that our 8B model achieves real-time, 24fps, streaming video generation at 736x416 resolution on a single H100, or 1280x720 on 8xH100 up to a minute long (1440 frames). Visit our research website at https://seaweed-apt.com/2
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025



Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.