 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Centric BEV Perception: A Survey
Aug 04, 2022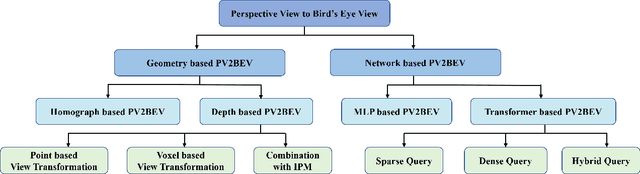

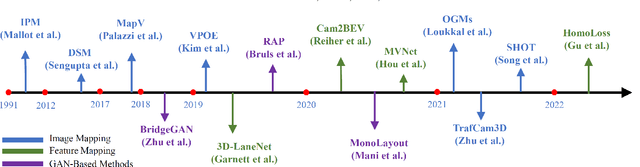
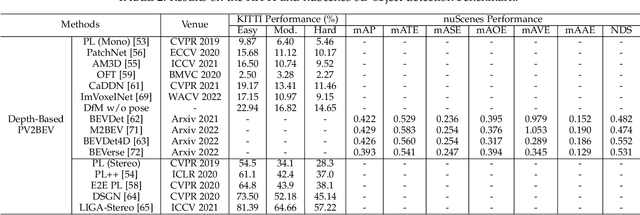
Vision-centric BEV perception has recently received increased attention from both industry and academia due to its inherent merits, including presenting a natural representation of the world and being fusion-friendly. With the rapid development of deep learning, numerous methods have been proposed to address the vision-centric BEV perception. However, there is no recent survey for this novel and growing research field. To stimulate its future research, this paper presents a comprehensive survey of recent progress of vision-centric BEV perception and its extensions. It collects and organizes the recent knowledge, and gives a systematic review and summary of commonly used algorithms. It also provides in-depth analyses and comparative results on several BEV perception tasks, facilitating the comparisons of future works and inspiring future research directions. Moreover, empirical implementation details are also discussed and shown to benefit the development of related algorithms.
MV-FCOS3D++: Multi-View Camera-Only 4D Object Detection with Pretrained Monocular Backbones
Jul 26, 2022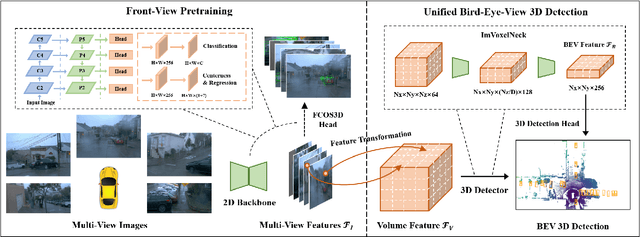
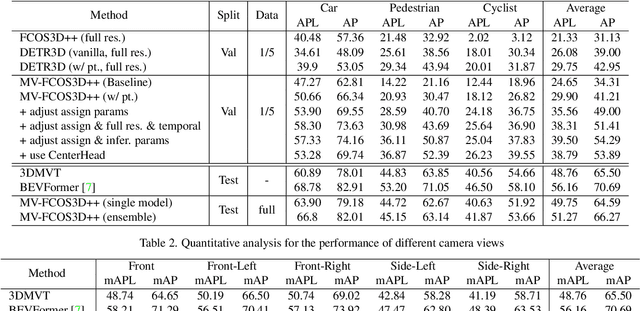
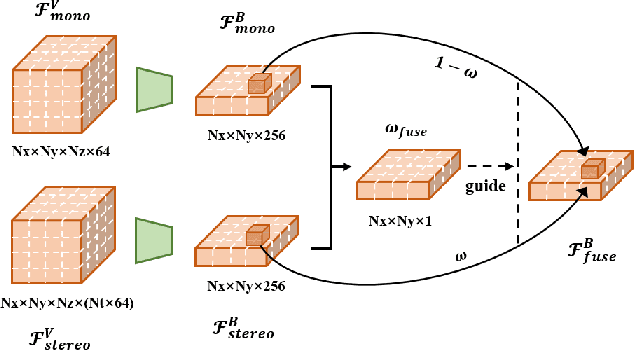

In this technical report, we present our solution, dubbed MV-FCOS3D++, for the Camera-Only 3D Detection track in Waymo Open Dataset Challenge 2022. For multi-view camera-only 3D detection, methods based on bird-eye-view or 3D geometric representations can leverage the stereo cues from overlapped regions between adjacent views and directly perform 3D detection without hand-crafted post-processing. However, it lacks direct semantic supervision for 2D backbones, which can be complemented by pretraining simple monocular-based detectors. Our solution is a multi-view framework for 4D detection following this paradigm. It is built upon a simple monocular detector FCOS3D++, pretrained only with object annotations of Waymo, and converts multi-view features to a 3D grid space to detect 3D objects thereon. A dual-path neck for single-frame understanding and temporal stereo matching is devised to incorporate multi-frame information. Our method finally achieves 49.75% mAPL with a single model and wins 2nd place in the WOD challenge, without any LiDAR-based depth supervision during training. The code will be released at https://github.com/Tai-Wang/Depth-from-Motion.
Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
Jun 05, 2022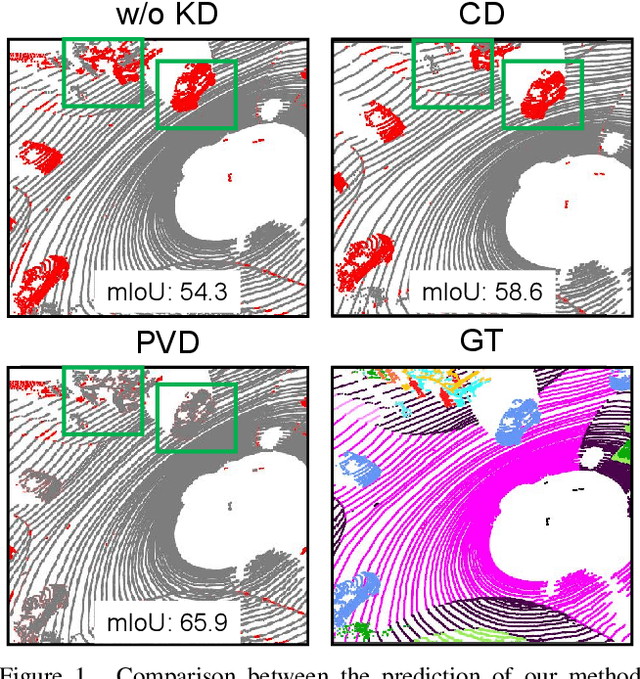
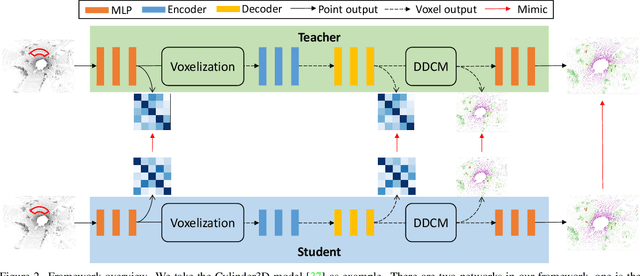
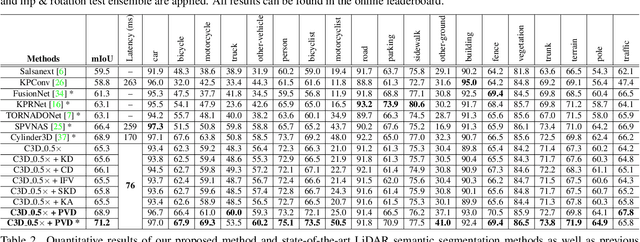
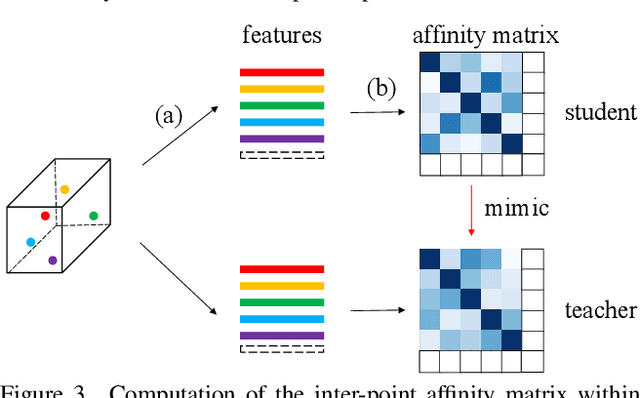
This article addresses the problem of distilling knowledge from a large teacher model to a slim student network for LiDAR semantic segmentation. Directly employing previous distillation approaches yields inferior results due to the intrinsic challenges of point cloud, i.e., sparsity, randomness and varying density. To tackle the aforementioned problems, we propose the Point-to-Voxel Knowledge Distillation (PVD), which transfers the hidden knowledge from both point level and voxel level. Specifically, we first leverage both the pointwise and voxelwise output distillation to complement the sparse supervision signals. Then, to better exploit the structural information, we divide the whole point cloud into several supervoxels and design a difficulty-aware sampling strategy to more frequently sample supervoxels containing less-frequent classes and faraway objects. On these supervoxels, we propose inter-point and inter-voxel affinity distillation, where the similarity information between points and voxels can help the student model better capture the structural information of the surrounding environment. We conduct extensive experiments on two popular LiDAR segmentation benchmarks, i.e., nuScenes and SemanticKITTI. On both benchmarks, our PVD consistently outperforms previous distillation approaches by a large margin on three representative backbones, i.e., Cylinder3D, SPVNAS and MinkowskiNet. Notably, on the challenging nuScenes and SemanticKITTI datasets, our method can achieve roughly 75% MACs reduction and 2x speedup on the competitive Cylinder3D model and rank 1st on the SemanticKITTI leaderboard among all published algorithms. Our code is available at https://github.com/cardwing/Codes-for-PVKD.
STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes
Apr 03, 2022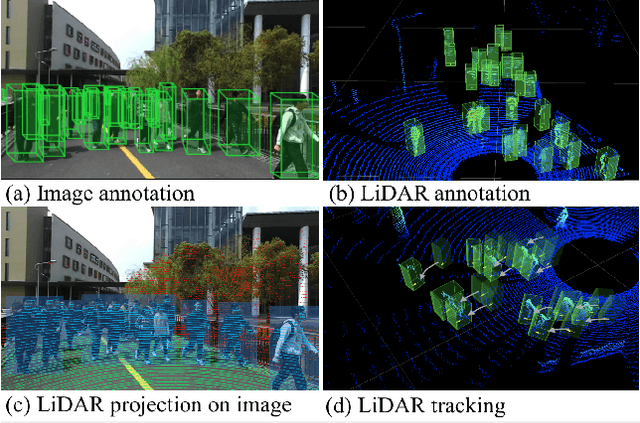
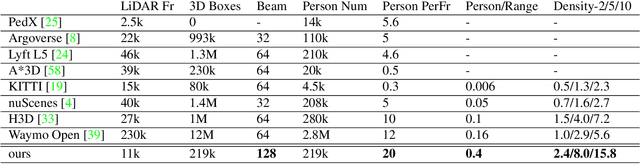

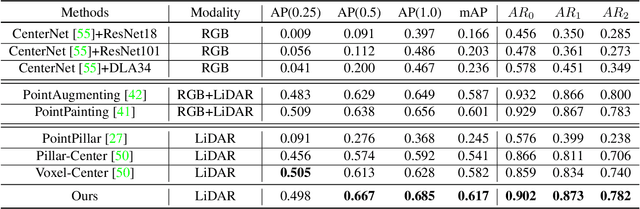
Accurately detecting and tracking pedestrians in 3D space is challenging due to large variations in rotations, poses and scales. The situation becomes even worse for dense crowds with severe occlusions. However, existing benchmarks either only provide 2D annotations, or have limited 3D annotations with low-density pedestrian distribution, making it difficult to build a reliable pedestrian perception system especially in crowded scenes. To better evaluate pedestrian perception algorithms in crowded scenarios, we introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets.
TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
Mar 22, 2022
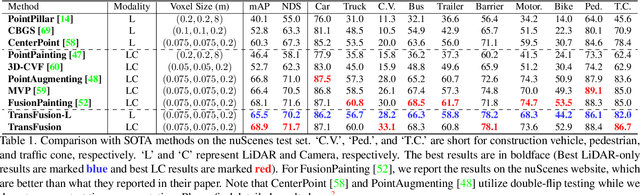
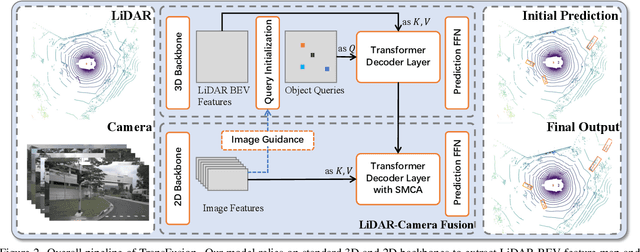
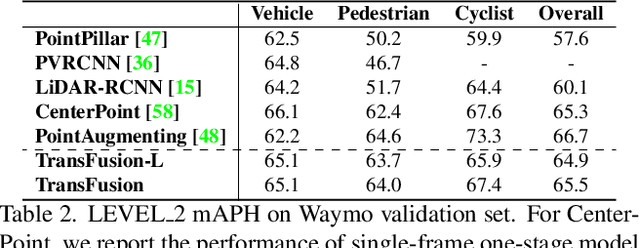
LiDAR and camera are two important sensors for 3D object detection in autonomous driving. Despite the increasing popularity of sensor fusion in this field, the robustness against inferior image conditions, e.g., bad illumination and sensor misalignment, is under-explored. Existing fusion methods are easily affected by such conditions, mainly due to a hard association of LiDAR points and image pixels, established by calibration matrices. We propose TransFusion, a robust solution to LiDAR-camera fusion with a soft-association mechanism to handle inferior image conditions. Specifically, our TransFusion consists of convolutional backbones and a detection head based on a transformer decoder. The first layer of the decoder predicts initial bounding boxes from a LiDAR point cloud using a sparse set of object queries, and its second decoder layer adaptively fuses the object queries with useful image features, leveraging both spatial and contextual relationships. The attention mechanism of the transformer enables our model to adaptively determine where and what information should be taken from the image, leading to a robust and effective fusion strategy. We additionally design an image-guided query initialization strategy to deal with objects that are difficult to detect in point clouds. TransFusion achieves state-of-the-art performance on large-scale datasets. We provide extensive experiments to demonstrate its robustness against degenerated image quality and calibration errors. We also extend the proposed method to the 3D tracking task and achieve the 1st place in the leaderboard of nuScenes tracking, showing its effectiveness and generalization capability.
Self-supervised Point Cloud Completion on Real Traffic Scenes via Scene-concerned Bottom-up Mechanism
Mar 20, 2022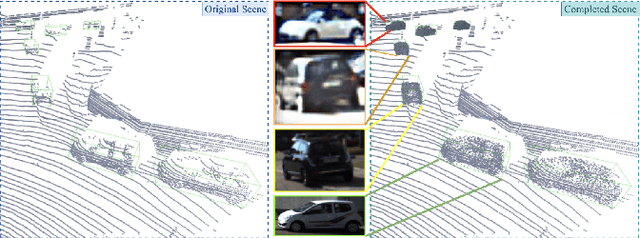

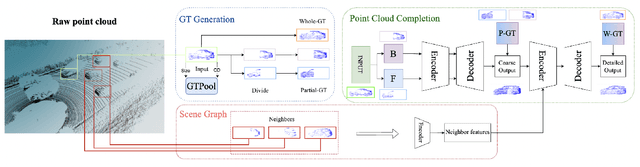
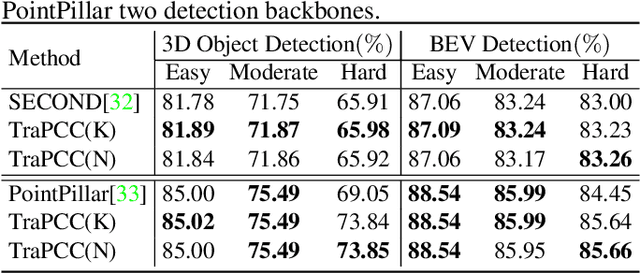
Real scans always miss partial geometries of objects due to the self-occlusions, external-occlusions, and limited sensor resolutions. Point cloud completion aims to refer the complete shapes for incomplete 3D scans of objects. Current deep learning-based approaches rely on large-scale complete shapes in the training process, which are usually obtained from synthetic datasets. It is not applicable for real-world scans due to the domain gap. In this paper, we propose a self-supervised point cloud completion method (TraPCC) for vehicles in real traffic scenes without any complete data. Based on the symmetry and similarity of vehicles, we make use of consecutive point cloud frames to construct vehicle memory bank as reference. We design a bottom-up mechanism to focus on both local geometry details and global shape features of inputs. In addition, we design a scene-graph in the network to pay attention to the missing parts by the aid of neighboring vehicles. Experiments show that TraPCC achieve good performance for real-scan completion on KITTI and nuScenes traffic datasets even without any complete data in training. We also show a downstream application of 3D detection, which benefits from our completion approach.
Towards 3D Scene Understanding by Referring Synthetic Models
Mar 20, 2022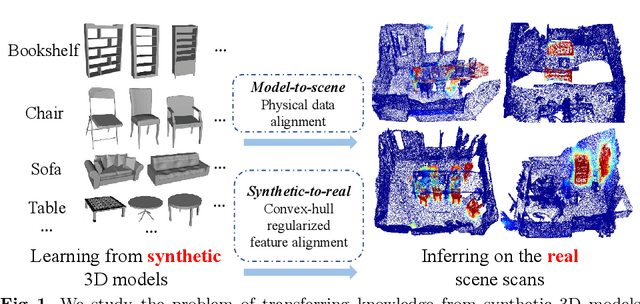
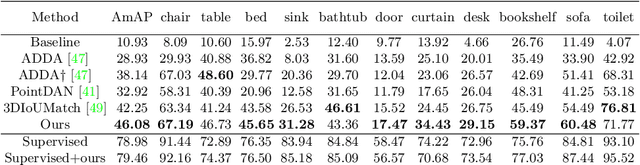
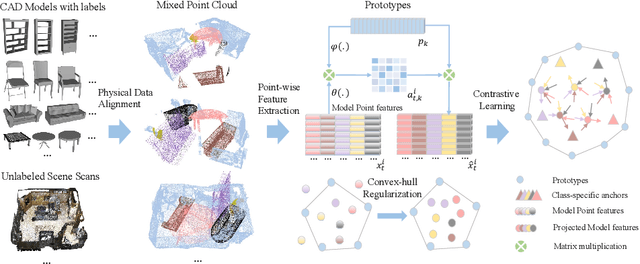
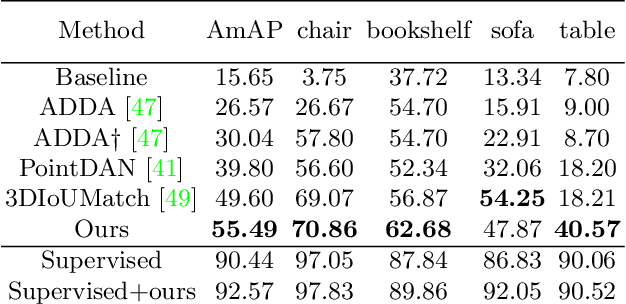
Promising performance has been achieved for visual perception on the point cloud. However, the current methods typically rely on labour-extensive annotations on the scene scans. In this paper, we explore how synthetic models alleviate the real scene annotation burden, i.e., taking the labelled 3D synthetic models as reference for supervision, the neural network aims to recognize specific categories of objects on a real scene scan (without scene annotation for supervision). The problem studies how to transfer knowledge from synthetic 3D models to real 3D scenes and is named Referring Transfer Learning (RTL). The main challenge is solving the model-to-scene (from a single model to the scene) and synthetic-to-real (from synthetic model to real scene's object) gap between the synthetic model and the real scene. To this end, we propose a simple yet effective framework to perform two alignment operations. First, physical data alignment aims to make the synthetic models cover the diversity of the scene's objects with data processing techniques. Then a novel \textbf{convex-hull regularized feature alignment} introduces learnable prototypes to project the point features of both synthetic models and real scenes to a unified feature space, which alleviates the domain gap. These operations ease the model-to-scene and synthetic-to-real difficulty for a network to recognize the target objects on a real unseen scene. Experiments show that our method achieves the average mAP of 46.08\% and 55.49\% on the ScanNet and S3DIS datasets by learning the synthetic models from the ModelNet dataset. Code will be publicly available.
LiDAR-based 4D Panoptic Segmentation via Dynamic Shifting Network
Mar 14, 2022
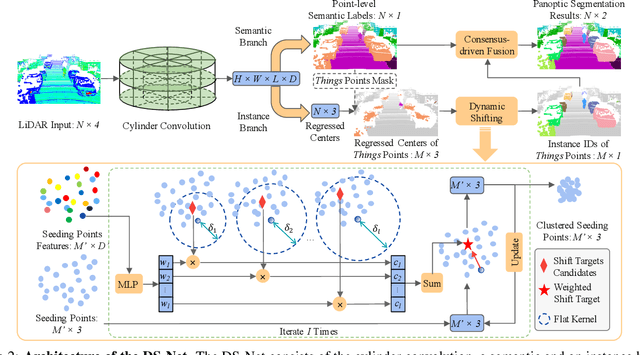

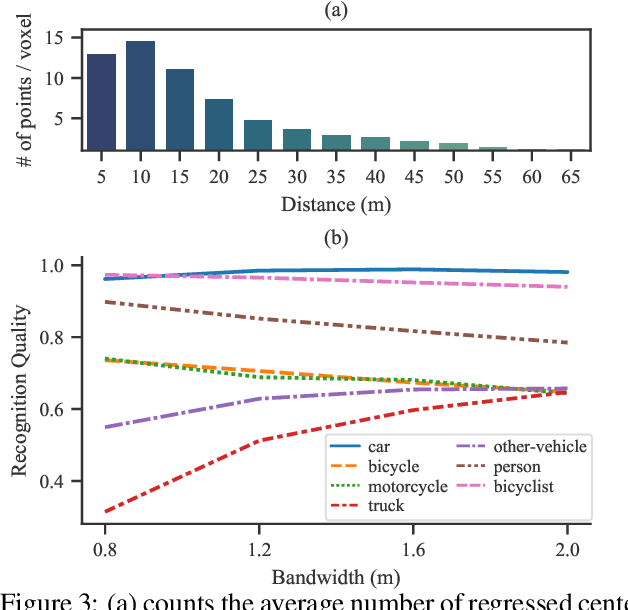
With the rapid advances of autonomous driving, it becomes critical to equip its sensing system with more holistic 3D perception. However, existing works focus on parsing either the objects (e.g. cars and pedestrians) or scenes (e.g. trees and buildings) from the LiDAR sensor. In this work, we address the task of LiDAR-based panoptic segmentation, which aims to parse both objects and scenes in a unified manner. As one of the first endeavors towards this new challenging task, we propose the Dynamic Shifting Network (DS-Net), which serves as an effective panoptic segmentation framework in the point cloud realm. In particular, DS-Net has three appealing properties: 1) Strong backbone design. DS-Net adopts the cylinder convolution that is specifically designed for LiDAR point clouds. 2) Dynamic Shifting for complex point distributions. We observe that commonly-used clustering algorithms are incapable of handling complex autonomous driving scenes with non-uniform point cloud distributions and varying instance sizes. Thus, we present an efficient learnable clustering module, dynamic shifting, which adapts kernel functions on the fly for different instances. 3) Extension to 4D prediction. Furthermore, we extend DS-Net to 4D panoptic LiDAR segmentation by the temporally unified instance clustering on aligned LiDAR frames. To comprehensively evaluate the performance of LiDAR-based panoptic segmentation, we construct and curate benchmarks from two large-scale autonomous driving LiDAR datasets, SemanticKITTI and nuScenes. Extensive experiments demonstrate that our proposed DS-Net achieves superior accuracies over current state-of-the-art methods in both tasks. Notably, in the single frame version of the task, we outperform the SOTA method by 1.8% in terms of the PQ metric. In the 4D version of the task, we surpass 2nd place by 5.4% in terms of the LSTQ metric.
AdaStereo: An Efficient Domain-Adaptive Stereo Matching Approach
Dec 09, 2021
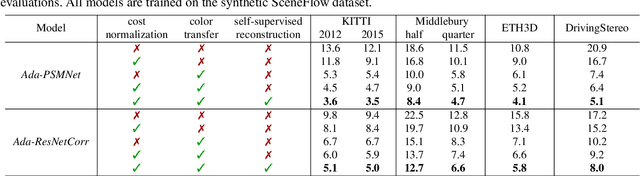
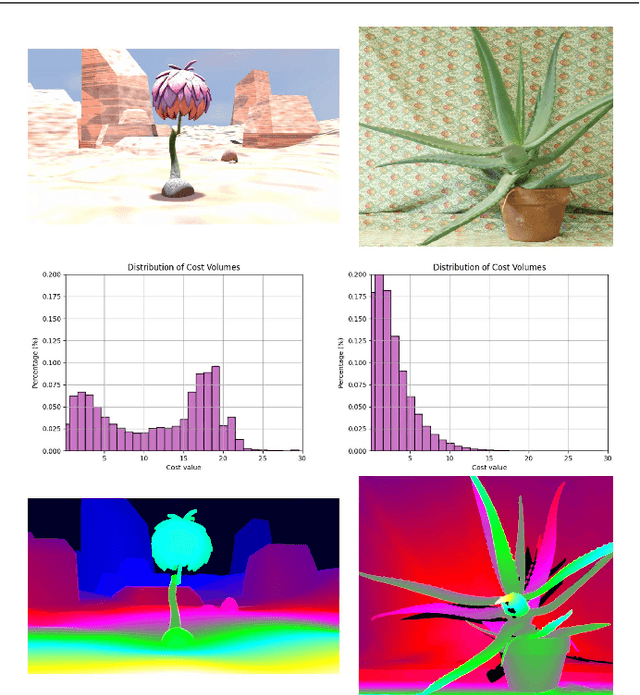
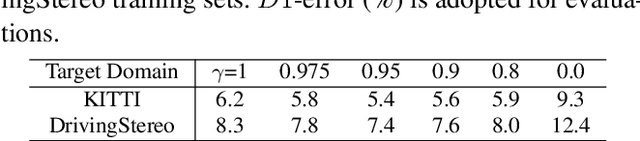
Recently, records on stereo matching benchmarks are constantly broken by end-to-end disparity networks. However, the domain adaptation ability of these deep models is quite limited. Addressing such problem, we present a novel domain-adaptive approach called AdaStereo that aims to align multi-level representations for deep stereo matching networks. Compared to previous methods, our AdaStereo realizes a more standard, complete and effective domain adaptation pipeline. Firstly, we propose a non-adversarial progressive color transfer algorithm for input image-level alignment. Secondly, we design an efficient parameter-free cost normalization layer for internal feature-level alignment. Lastly, a highly related auxiliary task, self-supervised occlusion-aware reconstruction is presented to narrow the gaps in output space. We perform intensive ablation studies and break-down comparisons to validate the effectiveness of each proposed module. With no extra inference overhead and only a slight increase in training complexity, our AdaStereo models achieve state-of-the-art cross-domain performance on multiple benchmarks, including KITTI, Middlebury, ETH3D and DrivingStereo, even outperforming some state-of-the-art disparity networks finetuned with target-domain ground-truths. Moreover, based on two additional evaluation metrics, the superiority of our domain-adaptive stereo matching pipeline is further uncovered from more perspectives. Finally, we demonstrate that our method is robust to various domain adaptation settings, and can be easily integrated into quick adaptation application scenarios and real-world deployments.
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR-based Perception
Sep 12, 2021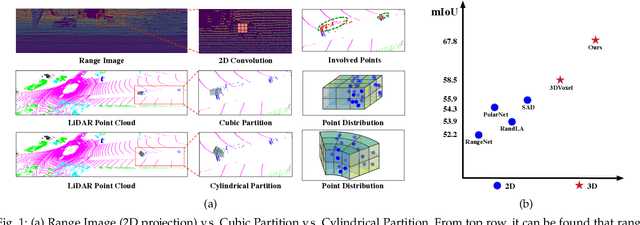
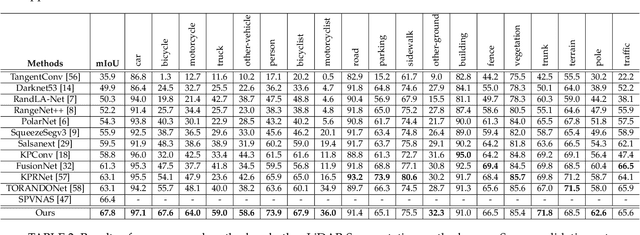
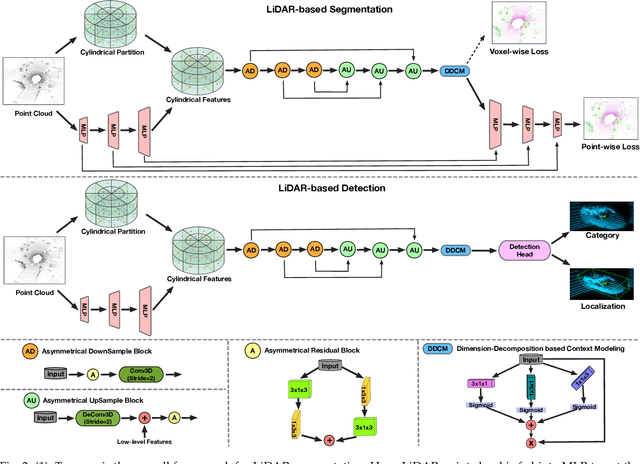
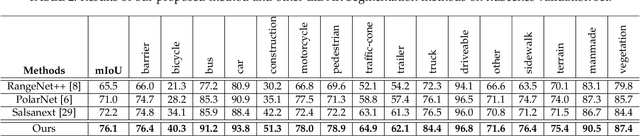
State-of-the-art methods for driving-scene LiDAR-based perception (including point cloud semantic segmentation, panoptic segmentation and 3D detection, \etc) often project the point clouds to 2D space and then process them via 2D convolution. Although this cooperation shows the competitiveness in the point cloud, it inevitably alters and abandons the 3D topology and geometric relations. A natural remedy is to utilize the 3D voxelization and 3D convolution network. However, we found that in the outdoor point cloud, the improvement obtained in this way is quite limited. An important reason is the property of the outdoor point cloud, namely sparsity and varying density. Motivated by this investigation, we propose a new framework for the outdoor LiDAR segmentation, where cylindrical partition and asymmetrical 3D convolution networks are designed to explore the 3D geometric pattern while maintaining these inherent properties. The proposed model acts as a backbone and the learned features from this model can be used for downstream tasks such as point cloud semantic and panoptic segmentation or 3D detection. In this paper, we benchmark our model on these three tasks. For semantic segmentation, we evaluate the proposed model on several large-scale datasets, \ie, SemanticKITTI, nuScenes and A2D2. Our method achieves the state-of-the-art on the leaderboard of SemanticKITTI (both single-scan and multi-scan challenge), and significantly outperforms existing methods on nuScenes and A2D2 dataset. Furthermore, the proposed 3D framework also shows strong performance and good generalization on LiDAR panoptic segmentation and LiDAR 3D detection.