 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Scale Spatial Deployment for Cost-Effective Wireless Networks via Cooperative IRSs and Movable Antennas
Jan 14, 2026This paper proposes a two-scale spatial deployment strategy to ensure reliable coverage for multiple target areas, integrating macroscopic intelligent reflecting surfaces (IRSs) and fine-grained movable antennas (MAs). Specifically, IRSs are selectively deployed from candidate sites to shape the propagation geometry, while MAs are locally repositioned among discretized locations to exploit small-scale channel variations. The objective is to minimize the total deployment cost of MAs and IRSs by jointly optimizing the IRS site selection, MA positions, transmit precoding, and IRS phase shifts, subject to the signal-to-noise ratio (SNR) requirements for all target areas. This leads to a challenging mixed-integer non-convex optimization problem that is intractable to solve directly. To address this, we first formulate an auxiliary problem to verify the feasibility. A penalty-based double-loop algorithm integrating alternating optimization and successive convex approximation (SCA) is developed to solve this feasibility issue, which is subsequently adapted to obtain a suboptimal solution for the original cost minimization problem. Finally, based on the obtained solution, we formulate an element refinement problem to further reduce the deployment cost, which is solved by a penalty-based SCA algorithm. Simulation results demonstrate that the proposed designs consistently outperform benchmarks relying on independent area planning or full IRS deployment in terms of cost-efficiency. Moreover, for cost minimization, MA architectures are preferable in large placement apertures, whereas fully populated FPA architectures excel in compact ones; for worst-case SNR maximization, MA architectures exhibit a lower cost threshold for feasibility, while FPA architectures can attain peak SNR at a lower total cost.
Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
Dec 18, 2025



In this work, we present a panoramic metric depth foundation model that generalizes across diverse scene distances. We explore a data-in-the-loop paradigm from the view of both data construction and framework design. We collect a large-scale dataset by combining public datasets, high-quality synthetic data from our UE5 simulator and text-to-image models, and real panoramic images from the web. To reduce domain gaps between indoor/outdoor and synthetic/real data, we introduce a three-stage pseudo-label curation pipeline to generate reliable ground truth for unlabeled images. For the model, we adopt DINOv3-Large as the backbone for its strong pre-trained generalization, and introduce a plug-and-play range mask head, sharpness-centric optimization, and geometry-centric optimization to improve robustness to varying distances and enforce geometric consistency across views. Experiments on multiple benchmarks (e.g., Stanford2D3D, Matterport3D, and Deep360) demonstrate strong performance and zero-shot generalization, with particularly robust and stable metric predictions in diverse real-world scenes. The project page can be found at: \href{https://insta360-research-team.github.io/DAP_website/} {https://insta360-research-team.github.io/DAP\_website/}
Enhancing Generalization of Depth Estimation Foundation Model via Weakly-Supervised Adaptation with Regularization
Nov 18, 2025The emergence of foundation models has substantially advanced zero-shot generalization in monocular depth estimation (MDE), as exemplified by the Depth Anything series. However, given access to some data from downstream tasks, a natural question arises: can the performance of these models be further improved? To this end, we propose WeSTAR, a parameter-efficient framework that performs Weakly supervised Self-Training Adaptation with Regularization, designed to enhance the robustness of MDE foundation models in unseen and diverse domains. We first adopt a dense self-training objective as the primary source of structural self-supervision. To further improve robustness, we introduce semantically-aware hierarchical normalization, which exploits instance-level segmentation maps to perform more stable and multi-scale structural normalization. Beyond dense supervision, we introduce a cost-efficient weak supervision in the form of pairwise ordinal depth annotations to further guide the adaptation process, which enforces informative ordinal constraints to mitigate local topological errors. Finally, a weight regularization loss is employed to anchor the LoRA updates, ensuring training stability and preserving the model's generalizable knowledge. Extensive experiments on both realistic and corrupted out-of-distribution datasets under diverse and challenging scenarios demonstrate that WeSTAR consistently improves generalization and achieves state-of-the-art performance across a wide range of benchmarks.
SMRC: Aligning Large Language Models with Student Reasoning for Mathematical Error Correction
Nov 18, 2025Large language models (LLMs) often make reasoning errors when solving mathematical problems, and how to automatically detect and correct these errors has become an important research direction. However, existing approaches \textit{mainly focus on self-correction within the model}, which falls short of the ``teacher-style`` correction required in educational settings, \textit{i.e.}, systematically guiding and revising a student's problem-solving process. To address this gap, we propose \texttt{SMRC} (\textit{\underline{S}tudent \underline{M}athematical \underline{R}easoning \underline{C}orrection}), a novel method that aligns LLMs with student reasoning. Specifically, \texttt{SMRC} formulates student reasoning as a multi-step sequential decision problem and introduces Monte Carlo Tree Search (MCTS) to explore optimal correction paths. To reduce the cost of the annotating process-level rewards, we leverage breadth-first search (BFS) guided by LLMs and final-answer evaluation to generate reward signals, which are then distributed across intermediate reasoning steps via a back-propagation mechanism, enabling fine-grained process supervision. Additionally, we construct a benchmark for high school mathematics, MSEB (Multi-Solution Error Benchmark), consisting of 158 instances that include problem statements, student solutions, and correct reasoning steps. We further propose a dual evaluation protocol centered on \textbf{solution accuracy} and \textbf{correct-step retention}, offering a comprehensive measure of educational applicability. Experiments demonstrate that \texttt{SMRC} significantly outperforms existing methods on two public datasets (ProcessBench and MR-GSM8K) and our MSEB in terms of effectiveness and overall performance. The code and data are available at https://github.com/Mind-Lab-ECNU/SMRC.
UCO: A Multi-Turn Interactive Reinforcement Learning Method for Adaptive Teaching with Large Language Models
Nov 12, 2025Large language models (LLMs) are shifting from answer providers to intelligent tutors in educational settings, yet current supervised fine-tuning methods only learn surface teaching patterns without dynamic adaptation capabilities. Recent reinforcement learning approaches address this limitation but face two critical challenges. First, they evaluate teaching effectiveness solely based on whether students produce correct outputs, unable to distinguish whether students genuinely understand or echo teacher-provided answers during interaction. Second, they cannot perceive students' evolving cognitive states in real time through interactive dialogue, thus failing to adapt teaching strategies to match students' cognitive levels dynamically. We propose the Unidirectional Cognitive Optimization (UCO) method to address these challenges. UCO uses a multi-turn interactive reinforcement learning paradigm where the innovation lies in two synergistic reward functions: the Progress Reward captures students' cognitive advancement, evaluating whether students truly transition from confusion to comprehension, while the Scaffold Reward dynamically identifies each student's Zone of Proximal Development (ZPD), encouraging teachers to maintain productive teaching within this zone. We evaluate UCO by comparing it against 11 baseline models on BigMath and MathTutorBench benchmarks. Experimental results demonstrate that our UCO model outperforms all models of equivalent scale and achieves performance comparable to advanced closed-source models. The code and data are available at https://github.com/Mind-Lab-ECNU/UCO.
OmniEduBench: A Comprehensive Chinese Benchmark for Evaluating Large Language Models in Education
Oct 30, 2025With the rapid development of large language models (LLMs), various LLM-based works have been widely applied in educational fields. However, most existing LLMs and their benchmarks focus primarily on the knowledge dimension, largely neglecting the evaluation of cultivation capabilities that are essential for real-world educational scenarios. Additionally, current benchmarks are often limited to a single subject or question type, lacking sufficient diversity. This issue is particularly prominent within the Chinese context. To address this gap, we introduce OmniEduBench, a comprehensive Chinese educational benchmark. OmniEduBench consists of 24.602K high-quality question-answer pairs. The data is meticulously divided into two core dimensions: the knowledge dimension and the cultivation dimension, which contain 18.121K and 6.481K entries, respectively. Each dimension is further subdivided into 6 fine-grained categories, covering a total of 61 different subjects (41 in the knowledge and 20 in the cultivation). Furthermore, the dataset features a rich variety of question formats, including 11 common exam question types, providing a solid foundation for comprehensively evaluating LLMs' capabilities in education. Extensive experiments on 11 mainstream open-source and closed-source LLMs reveal a clear performance gap. In the knowledge dimension, only Gemini-2.5 Pro surpassed 60\% accuracy, while in the cultivation dimension, the best-performing model, QWQ, still trailed human intelligence by nearly 30\%. These results highlight the substantial room for improvement and underscore the challenges of applying LLMs in education.
DA$^2$: Depth Anything in Any Direction
Sep 30, 2025Panorama has a full FoV (360$^\circ\times$180$^\circ$), offering a more complete visual description than perspective images. Thanks to this characteristic, panoramic depth estimation is gaining increasing traction in 3D vision. However, due to the scarcity of panoramic data, previous methods are often restricted to in-domain settings, leading to poor zero-shot generalization. Furthermore, due to the spherical distortions inherent in panoramas, many approaches rely on perspective splitting (e.g., cubemaps), which leads to suboptimal efficiency. To address these challenges, we propose $\textbf{DA}$$^{\textbf{2}}$: $\textbf{D}$epth $\textbf{A}$nything in $\textbf{A}$ny $\textbf{D}$irection, an accurate, zero-shot generalizable, and fully end-to-end panoramic depth estimator. Specifically, for scaling up panoramic data, we introduce a data curation engine for generating high-quality panoramic depth data from perspective, and create $\sim$543K panoramic RGB-depth pairs, bringing the total to $\sim$607K. To further mitigate the spherical distortions, we present SphereViT, which explicitly leverages spherical coordinates to enforce the spherical geometric consistency in panoramic image features, yielding improved performance. A comprehensive benchmark on multiple datasets clearly demonstrates DA$^{2}$'s SoTA performance, with an average 38% improvement on AbsRel over the strongest zero-shot baseline. Surprisingly, DA$^{2}$ even outperforms prior in-domain methods, highlighting its superior zero-shot generalization. Moreover, as an end-to-end solution, DA$^{2}$ exhibits much higher efficiency over fusion-based approaches. Both the code and the curated panoramic data will be released. Project page: https://depth-any-in-any-dir.github.io/.
CoDoL: Conditional Domain Prompt Learning for Out-of-Distribution Generalization
Sep 18, 2025Recent advances in pre-training vision-language models (VLMs), e.g., contrastive language-image pre-training (CLIP) methods, have shown great potential in learning out-of-distribution (OOD) representations. Despite showing competitive performance, the prompt-based CLIP methods still suffer from: i) inaccurate text descriptions, which leads to degraded accuracy and robustness, and poses a challenge for zero-shot CLIP methods. ii) limited vision-language embedding alignment, which significantly affects the generalization performance. To tackle the above issues, this paper proposes a novel Conditional Domain prompt Learning (CoDoL) method, which utilizes readily-available domain information to form prompts and improves the vision-language embedding alignment for improving OOD generalization. To capture both instance-specific and domain-specific information, we further propose a lightweight Domain Meta Network (DMN) to generate input-conditional tokens for images in each domain. Extensive experiments on four OOD benchmarks (PACS, VLCS, OfficeHome and DigitDG) validate the effectiveness of our proposed CoDoL in terms of improving the vision-language embedding alignment as well as the out-of-distribution generalization performance.
LLM-OREF: An Open Relation Extraction Framework Based on Large Language Models
Sep 18, 2025The goal of open relation extraction (OpenRE) is to develop an RE model that can generalize to new relations not encountered during training. Existing studies primarily formulate OpenRE as a clustering task. They first cluster all test instances based on the similarity between the instances, and then manually assign a new relation to each cluster. However, their reliance on human annotation limits their practicality. In this paper, we propose an OpenRE framework based on large language models (LLMs), which directly predicts new relations for test instances by leveraging their strong language understanding and generation abilities, without human intervention. Specifically, our framework consists of two core components: (1) a relation discoverer (RD), designed to predict new relations for test instances based on \textit{demonstrations} formed by training instances with known relations; and (2) a relation predictor (RP), used to select the most likely relation for a test instance from $n$ candidate relations, guided by \textit{demonstrations} composed of their instances. To enhance the ability of our framework to predict new relations, we design a self-correcting inference strategy composed of three stages: relation discovery, relation denoising, and relation prediction. In the first stage, we use RD to preliminarily predict new relations for all test instances. Next, we apply RP to select some high-reliability test instances for each new relation from the prediction results of RD through a cross-validation method. During the third stage, we employ RP to re-predict the relations of all test instances based on the demonstrations constructed from these reliable test instances. Extensive experiments on three OpenRE datasets demonstrate the effectiveness of our framework. We release our code at https://github.com/XMUDeepLIT/LLM-OREF.git.
One Flight Over the Gap: A Survey from Perspective to Panoramic Vision
Sep 04, 2025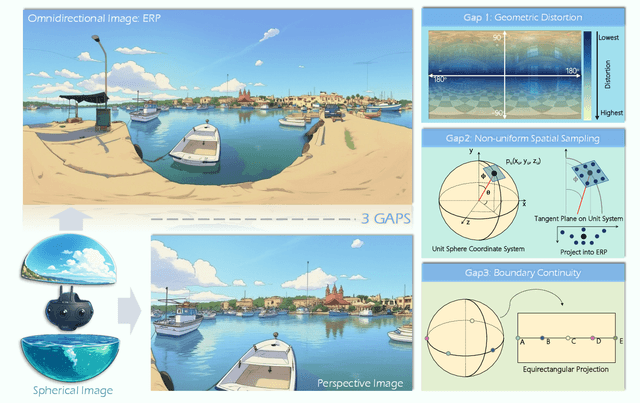
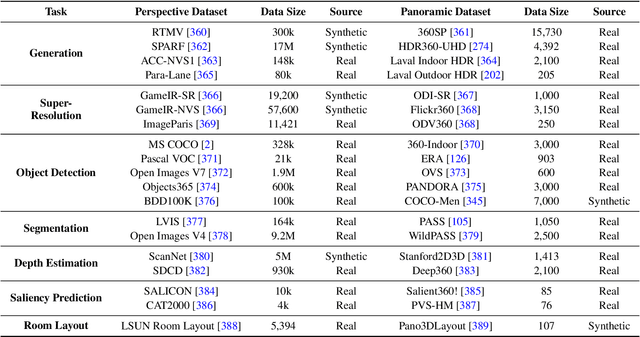
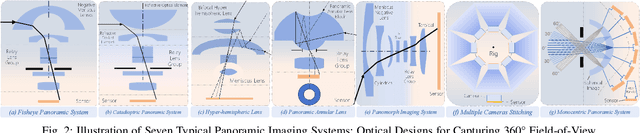
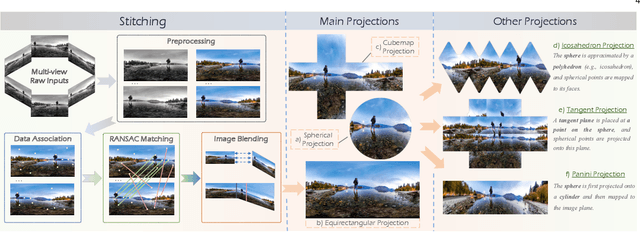
Driven by the demand for spatial intelligence and holistic scene perception, omnidirectional images (ODIs), which provide a complete 360\textdegree{} field of view, are receiving growing attention across diverse applications such as virtual reality, autonomous driving, and embodied robotics. Despite their unique characteristics, ODIs exhibit remarkable differences from perspective images in geometric projection, spatial distribution, and boundary continuity, making it challenging for direct domain adaption from perspective methods. This survey reviews recent panoramic vision techniques with a particular emphasis on the perspective-to-panorama adaptation. We first revisit the panoramic imaging pipeline and projection methods to build the prior knowledge required for analyzing the structural disparities. Then, we summarize three challenges of domain adaptation: severe geometric distortions near the poles, non-uniform sampling in Equirectangular Projection (ERP), and periodic boundary continuity. Building on this, we cover 20+ representative tasks drawn from more than 300 research papers in two dimensions. On one hand, we present a cross-method analysis of representative strategies for addressing panoramic specific challenges across different tasks. On the other hand, we conduct a cross-task comparison and classify panoramic vision into four major categories: visual quality enhancement and assessment, visual understanding, multimodal understanding, and visual generation. In addition, we discuss open challenges and future directions in data, models, and applications that will drive the advancement of panoramic vision research. We hope that our work can provide new insight and forward looking perspectives to advance the development of panoramic vision technologies. Our project page is https://insta360-research-team.github.io/Survey-of-Panorama