 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Physics to Representation: Audio Learning with Synthetic Pre-training via Procedural Generation
Jun 11, 2026Self-supervised learning advances audio representation for multimedia analysis. However, prevailing data-centric approaches rely on massive real-world corpora, increasing training costs, curation burdens, and privacy barriers. To address this, we present AudioPG, a procedural synthesis framework eliminating real audio recordings during pre-training. AudioPG trains a Transformer-based masked autoencoder on waveforms generated on-the-fly from basic acoustic primitives and composition rules. The encoder transfers effectively to real audio benchmarks, achieving 90.60% accuracy on ESC-50, 0.546 mAP on FSD50K, 88.17% on UrbanSound8K, and 97.03% on Speech Commands V2. Notably, pre-training completes in under 20 minutes on a single GPU. Latent space analysis reveals physical factors, including fundamental frequency and relative intensity, emerge in orthogonal subspaces, making representations linearly decodable. These results establish procedural synthesis as an efficient, interpretable pre-training signal when large-scale corpora are unavailable. Our code is available at: https://github.com/Freyliu0516/audioPG.
CASTLE: A Comprehensive Benchmark for Evaluating Student-Tailored Personalized Safety in Large Language Models
Feb 05, 2026Large language models (LLMs) have advanced the development of personalized learning in education. However, their inherent generation mechanisms often produce homogeneous responses to identical prompts. This one-size-fits-all mechanism overlooks the substantial heterogeneity in students cognitive and psychological, thereby posing potential safety risks to vulnerable groups. Existing safety evaluations primarily rely on context-independent metrics such as factual accuracy, bias, or toxicity, which fail to capture the divergent harms that the same response might cause across different student attributes. To address this gap, we propose the concept of Student-Tailored Personalized Safety and construct CASTLE based on educational theories. This benchmark covers 15 educational safety risks and 14 student attributes, comprising 92,908 bilingual scenarios. We further design three evaluation metrics: Risk Sensitivity, measuring the model ability to detect risks; Emotional Empathy, evaluating the model capacity to recognize student states; and Student Alignment, assessing the match between model responses and student attributes. Experiments on 18 SOTA LLMs demonstrate that CASTLE poses a significant challenge: all models scored below an average safety rating of 2.3 out of 5, indicating substantial deficiencies in personalized safety assurance.
SMRC: Aligning Large Language Models with Student Reasoning for Mathematical Error Correction
Nov 18, 2025Large language models (LLMs) often make reasoning errors when solving mathematical problems, and how to automatically detect and correct these errors has become an important research direction. However, existing approaches \textit{mainly focus on self-correction within the model}, which falls short of the ``teacher-style`` correction required in educational settings, \textit{i.e.}, systematically guiding and revising a student's problem-solving process. To address this gap, we propose \texttt{SMRC} (\textit{\underline{S}tudent \underline{M}athematical \underline{R}easoning \underline{C}orrection}), a novel method that aligns LLMs with student reasoning. Specifically, \texttt{SMRC} formulates student reasoning as a multi-step sequential decision problem and introduces Monte Carlo Tree Search (MCTS) to explore optimal correction paths. To reduce the cost of the annotating process-level rewards, we leverage breadth-first search (BFS) guided by LLMs and final-answer evaluation to generate reward signals, which are then distributed across intermediate reasoning steps via a back-propagation mechanism, enabling fine-grained process supervision. Additionally, we construct a benchmark for high school mathematics, MSEB (Multi-Solution Error Benchmark), consisting of 158 instances that include problem statements, student solutions, and correct reasoning steps. We further propose a dual evaluation protocol centered on \textbf{solution accuracy} and \textbf{correct-step retention}, offering a comprehensive measure of educational applicability. Experiments demonstrate that \texttt{SMRC} significantly outperforms existing methods on two public datasets (ProcessBench and MR-GSM8K) and our MSEB in terms of effectiveness and overall performance. The code and data are available at https://github.com/Mind-Lab-ECNU/SMRC.
EduAgentQG: A Multi-Agent Workflow Framework for Personalized Question Generation
Nov 08, 2025High-quality personalized question banks are crucial for supporting adaptive learning and individualized assessment. Manually designing questions is time-consuming and often fails to meet diverse learning needs, making automated question generation a crucial approach to reduce teachers' workload and improve the scalability of educational resources. However, most existing question generation methods rely on single-agent or rule-based pipelines, which still produce questions with unstable quality, limited diversity, and insufficient alignment with educational goals. To address these challenges, we propose EduAgentQG, a multi-agent collaborative framework for generating high-quality and diverse personalized questions. The framework consists of five specialized agents and operates through an iterative feedback loop: the Planner generates structured design plans and multiple question directions to enhance diversity; the Writer produces candidate questions based on the plan and optimizes their quality and diversity using feedback from the Solver and Educator; the Solver and Educator perform binary scoring across multiple evaluation dimensions and feed the evaluation results back to the Writer; the Checker conducts final verification, including answer correctness and clarity, ensuring alignment with educational goals. Through this multi-agent collaboration and iterative feedback loop, EduAgentQG generates questions that are both high-quality and diverse, while maintaining consistency with educational objectives. Experiments on two mathematics question datasets demonstrate that EduAgentQG outperforms existing single-agent and multi-agent methods in terms of question diversity, goal consistency, and overall quality.
Bitcoin Transaction Strategy Construction Based on Deep Reinforcement Learning
Sep 30, 2021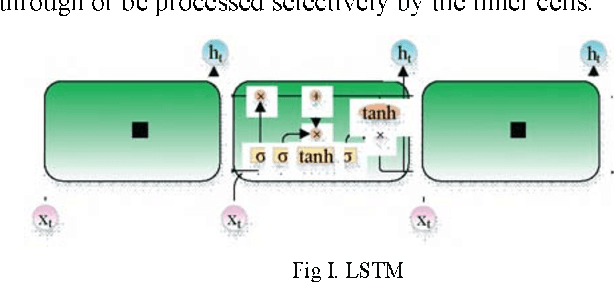
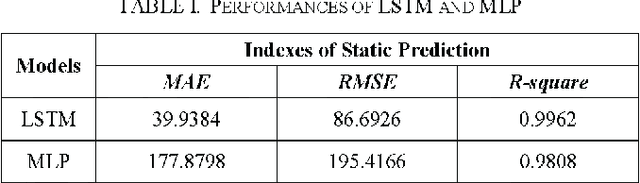
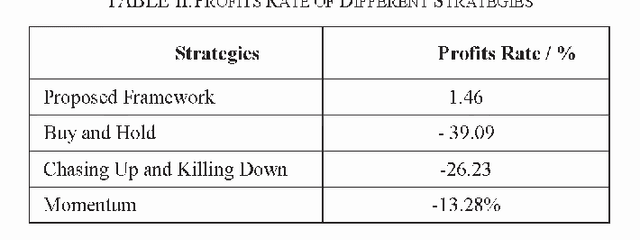
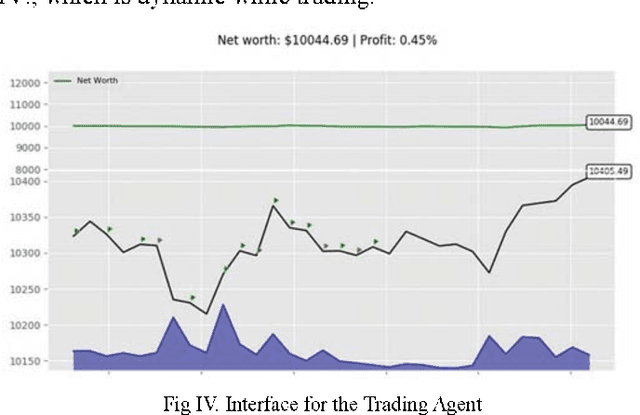
The emerging cryptocurrency market has lately received great attention for asset allocation due to its decentralization uniqueness. However, its volatility and brand new trading mode have made it challenging to devising an acceptable automatically-generating strategy. This study proposes a framework for automatic high-frequency bitcoin transactions based on a deep reinforcement learning algorithm-proximal policy optimization (PPO). The framework creatively regards the transaction process as actions, returns as awards and prices as states to align with the idea of reinforcement learning. It compares advanced machine learning-based models for static price predictions including support vector machine (SVM), multi-layer perceptron (MLP), long short-term memory (LSTM), temporal convolutional network (TCN), and Transformer by applying them to the real-time bitcoin price and the experimental results demonstrate that LSTM outperforms. Then an automatically-generating transaction strategy is constructed building on PPO with LSTM as the basis to construct the policy. Extensive empirical studies validate that the proposed method performs superiorly to various common trading strategy benchmarks for a single financial product. The approach is able to trade bitcoins in a simulated environment with synchronous data and obtains a 31.67% more return than that of the best benchmark, improving the benchmark by 12.75%. The proposed framework can earn excess returns through both the period of volatility and surge, which opens the door to research on building a single cryptocurrency trading strategy based on deep learning. Visualizations of trading the process show how the model handles high-frequency transactions to provide inspiration and demonstrate that it can be expanded to other financial products.