 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Physics to Representation: Audio Learning with Synthetic Pre-training via Procedural Generation
Jun 11, 2026Self-supervised learning advances audio representation for multimedia analysis. However, prevailing data-centric approaches rely on massive real-world corpora, increasing training costs, curation burdens, and privacy barriers. To address this, we present AudioPG, a procedural synthesis framework eliminating real audio recordings during pre-training. AudioPG trains a Transformer-based masked autoencoder on waveforms generated on-the-fly from basic acoustic primitives and composition rules. The encoder transfers effectively to real audio benchmarks, achieving 90.60% accuracy on ESC-50, 0.546 mAP on FSD50K, 88.17% on UrbanSound8K, and 97.03% on Speech Commands V2. Notably, pre-training completes in under 20 minutes on a single GPU. Latent space analysis reveals physical factors, including fundamental frequency and relative intensity, emerge in orthogonal subspaces, making representations linearly decodable. These results establish procedural synthesis as an efficient, interpretable pre-training signal when large-scale corpora are unavailable. Our code is available at: https://github.com/Freyliu0516/audioPG.
Out of Sight, Not Out of Mind: Unveiling Latent Attack in Latent-based Multi-Agent Systems
May 27, 2026Latent-based multi-agent systems replace parts of explicit inter-agent communication with hidden representations, offering a new direction for efficient and flexible agent collaboration. However, moving coordination into latent space may also move attacks beyond the reach of visible-text inspection. In this paper, we study whether latent states can carry attack-associated information that remains effective during clean executions. To examine this question, we introduce a latent attack framework that reactivates attack-induced effects through latent interventions without reusing adversarial text. Extensive experiments show that the resulting latent-only attacks can substantially degrade task performance in clean executions, especially when applied to inter-agent KV-cache handoffs rather than local hidden states. Further control analyses indicate that this degradation cannot be reduced to arbitrary perturbations or invalid generation. Overall, our findings suggest that latent-based collaboration does not remove attack risk. It shifts part of the risk into less observable execution states, calling for safeguards beyond visible-text inspection.
SMRC: Aligning Large Language Models with Student Reasoning for Mathematical Error Correction
Nov 18, 2025Large language models (LLMs) often make reasoning errors when solving mathematical problems, and how to automatically detect and correct these errors has become an important research direction. However, existing approaches \textit{mainly focus on self-correction within the model}, which falls short of the ``teacher-style`` correction required in educational settings, \textit{i.e.}, systematically guiding and revising a student's problem-solving process. To address this gap, we propose \texttt{SMRC} (\textit{\underline{S}tudent \underline{M}athematical \underline{R}easoning \underline{C}orrection}), a novel method that aligns LLMs with student reasoning. Specifically, \texttt{SMRC} formulates student reasoning as a multi-step sequential decision problem and introduces Monte Carlo Tree Search (MCTS) to explore optimal correction paths. To reduce the cost of the annotating process-level rewards, we leverage breadth-first search (BFS) guided by LLMs and final-answer evaluation to generate reward signals, which are then distributed across intermediate reasoning steps via a back-propagation mechanism, enabling fine-grained process supervision. Additionally, we construct a benchmark for high school mathematics, MSEB (Multi-Solution Error Benchmark), consisting of 158 instances that include problem statements, student solutions, and correct reasoning steps. We further propose a dual evaluation protocol centered on \textbf{solution accuracy} and \textbf{correct-step retention}, offering a comprehensive measure of educational applicability. Experiments demonstrate that \texttt{SMRC} significantly outperforms existing methods on two public datasets (ProcessBench and MR-GSM8K) and our MSEB in terms of effectiveness and overall performance. The code and data are available at https://github.com/Mind-Lab-ECNU/SMRC.
Criticality-Based Dynamic Topology Optimization for Enhancing Aerial-Marine Swarm Resilience
Aug 01, 2025Heterogeneous marine-aerial swarm networks encounter substantial difficulties due to targeted communication disruptions and structural weaknesses in adversarial environments. This paper proposes a two-step framework to strengthen the network's resilience. Specifically, our framework combines the node prioritization based on criticality with multi-objective topology optimization. First, we design a three-layer architecture to represent structural, communication, and task dependencies of the swarm networks. Then, we introduce the SurBi-Ranking method, which utilizes graph convolutional networks, to dynamically evaluate and rank the criticality of nodes and edges in real time. Next, we apply the NSGA-III algorithm to optimize the network topology, aiming to balance communication efficiency, global connectivity, and mission success rate. Experiments demonstrate that compared to traditional methods like K-Shell, our SurBi-Ranking method identifies critical nodes and edges with greater accuracy, as deliberate attacks on these components cause more significant connectivity degradation. Furthermore, our optimization approach, when prioritizing SurBi-Ranked critical components under attack, reduces the natural connectivity degradation by around 30%, achieves higher mission success rates, and incurs lower communication reconfiguration costs, ensuring sustained connectivity and mission effectiveness across multi-phase operations.
An Attention-Gated Convolutional Neural Network for Sentence Classification
Aug 28, 2018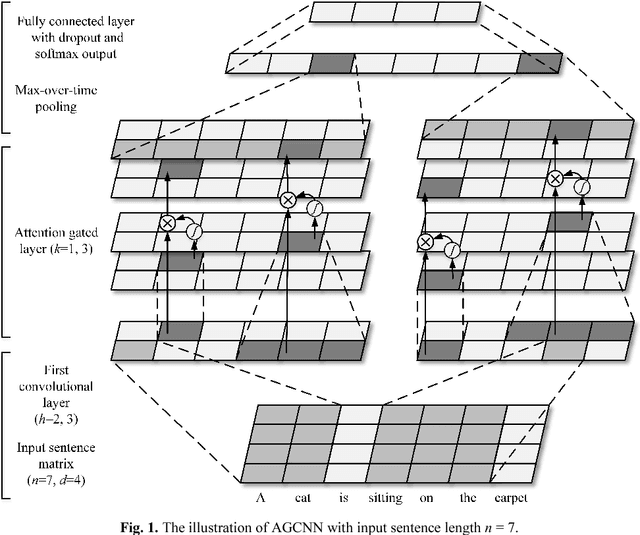
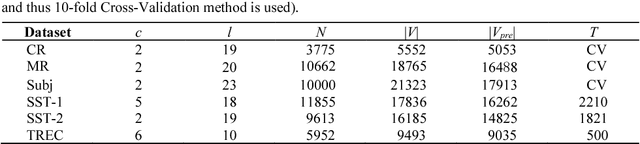
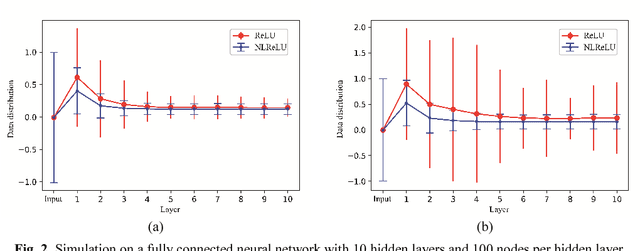

The classification task of sentences is very challenging because of the limited contextual information that sentences contain. In this paper, we propose an Attention Gated Convolutional Neural Network (AGCNN) for sentence classification, which generates attention weights from the feature's context windows of different sizes by using specialized convolution encoders, to enhance the influence of critical features in predicting the sentence's category. Experimental results demonstrate that our model could achieve a general accuracy improvement highest up to 3.1% (compared with standard CNN models), and gain competitive results over the strong baseline methods on four out of the six tasks. Besides, we propose an activation function named Natural Logarithm rescaled Rectified Linear Unit (NLReLU). Experimental results show that NLReLU could outperform ReLU and performs comparably to other well-known activation functions on AGCNN.