 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolygon-mamba: Retinal vessel segmentation using polygon scanning mamba and space-frequency collaborative attention
May 11, 2026Retinal vessel segmentation is crucial for diagnosis and assessment of ocular diseases. Notably, segmentation of small retinal vessels has been consistently recognized as a challenging and complex task. To tackle this challenge, we design a hybrid CNN-Mamba fusion network that integrates polygon scanning mamba and space-frequency collaborative attention mechanism for the detection of small vessels. Considering that the traditional mamba architecture with horizontal-vertical scanning may compromise the topological integrity of target structures and result in local discontinuities in small retinal vessels, we present a polygon scanning visual state space model (PS-VSS) to identify small vessel structural features by multi-layer reverse scanning way. Which effectively preserves pixels connectivity, thereby substantially mitigating the loss of information pertaining to small vessels. Furthermore, as we all known that the spatial domain prioritizes positional and structural information, while the frequency domain emphasizes global perception and local detail components, a space-frequency collaborative attention mechanism (SFCAM) is introduced within the skip connection to extract efficient features from the spatial and frequency domains. This strategy empowers the model to dynamically enhance the key features while effectively suppressing clutters. To assess the efficacy of our model, it was tested on three publicly available datasets: DRIVE, STARE, and CHASE_DB1. Compared to manual annotations, our model demonstrated F1 scores of 0.8283, 0.8282, and 0.8251, Area Under Curve (AUC) values of 0.9806, 0.9840, and 0.9866, and Sensitivity (SE) values of of 0.8268, 0.8314, and 0.8484 across three datasets, respectively. The effectiveness of our model was validated through both visual inspection and quantitative analysis.
Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
May 04, 2026We present Mamoda2.5, a unified AR-Diffusion framework that seamlessly integrates multimodal understanding and generation within a single architecture. To efficiently enhance the model's generation capability, we equip the Diffusion Transformer backbone with a fine-grained Mixture-of-Experts (MoE) design (128 experts, Top-8 routing), yielding a 25B-parameter model that activates only 3B parameters, significantly reducing training costs while scaling up the model capacity. Mamoda2.5 achieves top-tier generation performance on VBench 2.0 and sets a new record in video editing quality, surpassing evaluated open-source models and matching the performance of current top-tier proprietary models, including the Kling O1 on OpenVE-Bench. Furthermore, we introduce a joint few-step distillation and reinforcement learning framework that compresses the 30-step editing model into a 4-step model and greatly accelerates model inference. Compared to open-source baselines, Mamoda2.5 achieves up to $95.9\times$ faster video editing inference. In real-world applications, Mamoda2.5 has been successfully deployed for content moderation and creative restoration tasks in advertising scenarios, achieving a 98% success rate in internal advertising video editing scenario.
SMRC: Aligning Large Language Models with Student Reasoning for Mathematical Error Correction
Nov 18, 2025Large language models (LLMs) often make reasoning errors when solving mathematical problems, and how to automatically detect and correct these errors has become an important research direction. However, existing approaches \textit{mainly focus on self-correction within the model}, which falls short of the ``teacher-style`` correction required in educational settings, \textit{i.e.}, systematically guiding and revising a student's problem-solving process. To address this gap, we propose \texttt{SMRC} (\textit{\underline{S}tudent \underline{M}athematical \underline{R}easoning \underline{C}orrection}), a novel method that aligns LLMs with student reasoning. Specifically, \texttt{SMRC} formulates student reasoning as a multi-step sequential decision problem and introduces Monte Carlo Tree Search (MCTS) to explore optimal correction paths. To reduce the cost of the annotating process-level rewards, we leverage breadth-first search (BFS) guided by LLMs and final-answer evaluation to generate reward signals, which are then distributed across intermediate reasoning steps via a back-propagation mechanism, enabling fine-grained process supervision. Additionally, we construct a benchmark for high school mathematics, MSEB (Multi-Solution Error Benchmark), consisting of 158 instances that include problem statements, student solutions, and correct reasoning steps. We further propose a dual evaluation protocol centered on \textbf{solution accuracy} and \textbf{correct-step retention}, offering a comprehensive measure of educational applicability. Experiments demonstrate that \texttt{SMRC} significantly outperforms existing methods on two public datasets (ProcessBench and MR-GSM8K) and our MSEB in terms of effectiveness and overall performance. The code and data are available at https://github.com/Mind-Lab-ECNU/SMRC.
Large-scale Multi-sequence Pretraining for Generalizable MRI Analysis in Versatile Clinical Applications
Aug 10, 2025



Multi-sequence Magnetic Resonance Imaging (MRI) offers remarkable versatility, enabling the distinct visualization of different tissue types. Nevertheless, the inherent heterogeneity among MRI sequences poses significant challenges to the generalization capability of deep learning models. These challenges undermine model performance when faced with varying acquisition parameters, thereby severely restricting their clinical utility. In this study, we present PRISM, a foundation model PRe-trained with large-scale multI-Sequence MRI. We collected a total of 64 datasets from both public and private sources, encompassing a wide range of whole-body anatomical structures, with scans spanning diverse MRI sequences. Among them, 336,476 volumetric MRI scans from 34 datasets (8 public and 26 private) were curated to construct the largest multi-organ multi-sequence MRI pretraining corpus to date. We propose a novel pretraining paradigm that disentangles anatomically invariant features from sequence-specific variations in MRI, while preserving high-level semantic representations. We established a benchmark comprising 44 downstream tasks, including disease diagnosis, image segmentation, registration, progression prediction, and report generation. These tasks were evaluated on 32 public datasets and 5 private cohorts. PRISM consistently outperformed both non-pretrained models and existing foundation models, achieving first-rank results in 39 out of 44 downstream benchmarks with statistical significance improvements. These results underscore its ability to learn robust and generalizable representations across unseen data acquired under diverse MRI protocols. PRISM provides a scalable framework for multi-sequence MRI analysis, thereby enhancing the translational potential of AI in radiology. It delivers consistent performance across diverse imaging protocols, reinforcing its clinical applicability.
Cross-Modal Clustering-Guided Negative Sampling for Self-Supervised Joint Learning from Medical Images and Reports
Jun 13, 2025Learning medical visual representations directly from paired images and reports through multimodal self-supervised learning has emerged as a novel and efficient approach to digital diagnosis in recent years. However, existing models suffer from several severe limitations. 1) neglecting the selection of negative samples, resulting in the scarcity of hard negatives and the inclusion of false negatives; 2) focusing on global feature extraction, but overlooking the fine-grained local details that are crucial for medical image recognition tasks; and 3) contrastive learning primarily targets high-level features but ignoring low-level details which are essential for accurate medical analysis. Motivated by these critical issues, this paper presents a Cross-Modal Cluster-Guided Negative Sampling (CM-CGNS) method with two-fold ideas. First, it extends the k-means clustering used for local text features in the single-modal domain to the multimodal domain through cross-modal attention. This improvement increases the number of negative samples and boosts the model representation capability. Second, it introduces a Cross-Modal Masked Image Reconstruction (CM-MIR) module that leverages local text-to-image features obtained via cross-modal attention to reconstruct masked local image regions. This module significantly strengthens the model's cross-modal information interaction capabilities and retains low-level image features essential for downstream tasks. By well handling the aforementioned limitations, the proposed CM-CGNS can learn effective and robust medical visual representations suitable for various recognition tasks. Extensive experimental results on classification, detection, and segmentation tasks across five downstream datasets show that our method outperforms state-of-the-art approaches on multiple metrics, verifying its superior performance.
MSLAU-Net: A Hybird CNN-Transformer Network for Medical Image Segmentation
May 24, 2025

Both CNN-based and Transformer-based methods have achieved remarkable success in medical image segmentation tasks. However, CNN-based methods struggle to effectively capture global contextual information due to the inherent limitations of convolution operations. Meanwhile, Transformer-based methods suffer from insufficient local feature modeling and face challenges related to the high computational complexity caused by the self-attention mechanism. To address these limitations, we propose a novel hybrid CNN-Transformer architecture, named MSLAU-Net, which integrates the strengths of both paradigms. The proposed MSLAU-Net incorporates two key ideas. First, it introduces Multi-Scale Linear Attention, designed to efficiently extract multi-scale features from medical images while modeling long-range dependencies with low computational complexity. Second, it adopts a top-down feature aggregation mechanism, which performs multi-level feature aggregation and restores spatial resolution using a lightweight structure. Extensive experiments conducted on benchmark datasets covering three imaging modalities demonstrate that the proposed MSLAU-Net outperforms other state-of-the-art methods on nearly all evaluation metrics, validating the superiority, effectiveness, and robustness of our approach. Our code is available at https://github.com/Monsoon49/MSLAU-Net.
Image-Based Virtual Try-On: A Survey
Nov 08, 2023Image-based virtual try-on aims to synthesize a naturally dressed person image with a clothing image, which revolutionizes online shopping and inspires related topics within image generation, showing both research significance and commercial potentials. However, there is a great gap between current research progress and commercial applications and an absence of comprehensive overview towards this field to accelerate the development. In this survey, we provide a comprehensive analysis of the state-of-the-art techniques and methodologies in aspects of pipeline architecture, person representation and key modules such as try-on indication, clothing warping and try-on stage. We propose a new semantic criteria with CLIP, and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset. In addition to quantitative and qualitative evaluation of current open-source methods, we also utilize ControlNet to fine-tune a recent large image generation model (PBE) to show future potentials of large-scale models on image-based virtual try-on task. Finally, unresolved issues are revealed and future research directions are prospected to identify key trends and inspire further exploration. The uniformly implemented evaluation metrics, dataset and collected methods will be made public available at https://github.com/little-misfit/Survey-Of-Virtual-Try-On.
Deep Angular Embedding and Feature Correlation Attention for Breast MRI Cancer Analysis
Jun 07, 2019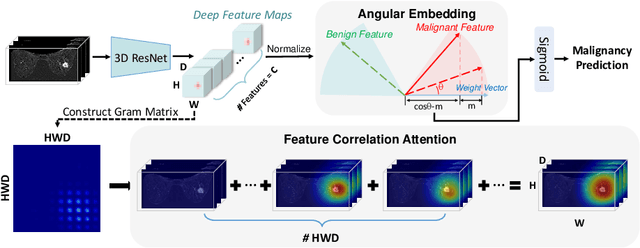
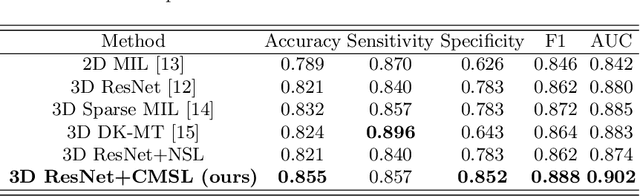
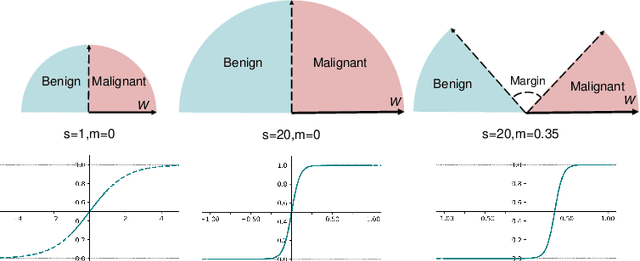
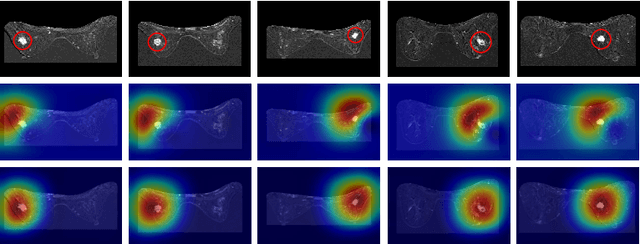
Accurate and automatic analysis of breast MRI plays an important role in early diagnosis and successful treatment planning for breast cancer. Due to the heterogeneity nature, accurate diagnosis of tumors remains a challenging task. In this paper, we propose to identify breast tumor in MRI by Cosine Margin Sigmoid Loss (CMSL) with deep learning (DL) and localize possible cancer lesion by COrrelation Attention Map (COAM) based on the learned features. The CMSL embeds tumor features onto a hypersphere and imposes a decision margin through cosine constraints. In this way, the DL model could learn more separable inter-class features and more compact intra-class features in the angular space. Furthermore, we utilize the correlations among feature vectors to generate attention maps that could accurately localize cancer candidates with only image-level label. We build the largest breast cancer dataset involving 10,290 DCE-MRI scan volumes for developing and evaluating the proposed methods. The model driven by CMSL achieved classification accuracy of 0.855 and AUC of 0.902 on the testing set, with sensitivity and specificity of 0.857 and 0.852, respectively, outperforming other competitive methods overall. In addition, the proposed COAM accomplished more accurate localization of the cancer center compared with other state-of-the-art weakly supervised localization method.