 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigate Language Priors in Large Vision-Language Models by Cross-Images Contrastive Decoding
May 19, 2025Language priors are a major cause of hallucinations in Large Vision-Language Models (LVLMs), often leading to text that is linguistically plausible but visually inconsistent. Recent work explores contrastive decoding as a training-free solution, but these methods typically construct negative visual contexts from the original image, resulting in visual information loss and distorted distribution. Motivated by the observation that language priors stem from the LLM backbone and remain consistent across images, we propose Cross-Images Contrastive Decoding (CICD), a simple yet effective training-free method that uses different images to construct negative visual contexts. We further analyze the cross-image behavior of language priors and introduce a distinction between essential priors (supporting fluency) and detrimental priors (causing hallucinations), enabling selective suppression. By selectively preserving essential priors and suppressing detrimental ones, our method reduces hallucinations while maintaining coherent and fluent language generation. Experiments on four benchmarks and six LVLMs across three model families confirm the effectiveness and generalizability of CICD, especially in image captioning, where language priors are particularly pronounced. Code will be released upon acceptance.
PoisonArena: Uncovering Competing Poisoning Attacks in Retrieval-Augmented Generation
May 18, 2025



Retrieval-Augmented Generation (RAG) systems, widely used to improve the factual grounding of large language models (LLMs), are increasingly vulnerable to poisoning attacks, where adversaries inject manipulated content into the retriever's corpus. While prior research has predominantly focused on single-attacker settings, real-world scenarios often involve multiple, competing attackers with conflicting objectives. In this work, we introduce PoisonArena, the first benchmark to systematically study and evaluate competing poisoning attacks in RAG. We formalize the multi-attacker threat model, where attackers vie to control the answer to the same query using mutually exclusive misinformation. PoisonArena leverages the Bradley-Terry model to quantify each method's competitive effectiveness in such adversarial environments. Through extensive experiments on the Natural Questions and MS MARCO datasets, we demonstrate that many attack strategies successful in isolation fail under competitive pressure. Our findings highlight the limitations of conventional evaluation metrics like Attack Success Rate (ASR) and F1 score and underscore the need for competitive evaluation to assess real-world attack robustness. PoisonArena provides a standardized framework to benchmark and develop future attack and defense strategies under more realistic, multi-adversary conditions. Project page: https://github.com/yxf203/PoisonArena.
Shape-Guided Clothing Warping for Virtual Try-On
Apr 21, 2025Image-based virtual try-on aims to seamlessly fit in-shop clothing to a person image while maintaining pose consistency. Existing methods commonly employ the thin plate spline (TPS) transformation or appearance flow to deform in-shop clothing for aligning with the person's body. Despite their promising performance, these methods often lack precise control over fine details, leading to inconsistencies in shape between clothing and the person's body as well as distortions in exposed limb regions. To tackle these challenges, we propose a novel shape-guided clothing warping method for virtual try-on, dubbed SCW-VTON, which incorporates global shape constraints and additional limb textures to enhance the realism and consistency of the warped clothing and try-on results. To integrate global shape constraints for clothing warping, we devise a dual-path clothing warping module comprising a shape path and a flow path. The former path captures the clothing shape aligned with the person's body, while the latter path leverages the mapping between the pre- and post-deformation of the clothing shape to guide the estimation of appearance flow. Furthermore, to alleviate distortions in limb regions of try-on results, we integrate detailed limb guidance by developing a limb reconstruction network based on masked image modeling. Through the utilization of SCW-VTON, we are able to generate try-on results with enhanced clothing shape consistency and precise control over details. Extensive experiments demonstrate the superiority of our approach over state-of-the-art methods both qualitatively and quantitatively. The code is available at https://github.com/xyhanHIT/SCW-VTON.
COST: Contrastive One-Stage Transformer for Vision-Language Small Object Tracking
Apr 02, 2025Transformer has recently demonstrated great potential in improving vision-language (VL) tracking algorithms. However, most of the existing VL trackers rely on carefully designed mechanisms to perform the multi-stage multi-modal fusion. Additionally, direct multi-modal fusion without alignment ignores distribution discrepancy between modalities in feature space, potentially leading to suboptimal representations. In this work, we propose COST, a contrastive one-stage transformer fusion framework for VL tracking, aiming to learn semantically consistent and unified VL representations. Specifically, we introduce a contrastive alignment strategy that maximizes mutual information (MI) between a video and its corresponding language description. This enables effective cross-modal alignment, yielding semantically consistent features in the representation space. By leveraging a visual-linguistic transformer, we establish an efficient multi-modal fusion and reasoning mechanism, empirically demonstrating that a simple stack of transformer encoders effectively enables unified VL representations. Moreover, we contribute a newly collected VL tracking benchmark dataset for small object tracking, named VL-SOT500, with bounding boxes and language descriptions. Our dataset comprises two challenging subsets, VL-SOT230 and VL-SOT270, dedicated to evaluating generic and high-speed small object tracking, respectively. Small object tracking is notoriously challenging due to weak appearance and limited features, and this dataset is, to the best of our knowledge, the first to explore the usage of language cues to enhance visual representation for small object tracking. Extensive experiments demonstrate that COST achieves state-of-the-art performance on five existing VL tracking datasets, as well as on our proposed VL-SOT500 dataset. Source codes and dataset will be made publicly available.
Path-Adaptive Matting for Efficient Inference Under Various Computational Cost Constraints
Mar 05, 2025



In this paper, we explore a novel image matting task aimed at achieving efficient inference under various computational cost constraints, specifically FLOP limitations, using a single matting network. Existing matting methods which have not explored scalable architectures or path-learning strategies, fail to tackle this challenge. To overcome these limitations, we introduce Path-Adaptive Matting (PAM), a framework that dynamically adjusts network paths based on image contexts and computational cost constraints. We formulate the training of the computational cost-constrained matting network as a bilevel optimization problem, jointly optimizing the matting network and the path estimator. Building on this formalization, we design a path-adaptive matting architecture by incorporating path selection layers and learnable connect layers to estimate optimal paths and perform efficient inference within a unified network. Furthermore, we propose a performance-aware path-learning strategy to generate path labels online by evaluating a few paths sampled from the prior distribution of optimal paths and network estimations, enabling robust and efficient online path learning. Experiments on five image matting datasets demonstrate that the proposed PAM framework achieves competitive performance across a range of computational cost constraints.
Rethinking the Upsampling Layer in Hyperspectral Image Super Resolution
Jan 30, 2025



Deep learning has achieved significant success in single hyperspectral image super-resolution (SHSR); however, the high spectral dimensionality leads to a heavy computational burden, thus making it difficult to deploy in real-time scenarios. To address this issue, this paper proposes a novel lightweight SHSR network, i.e., LKCA-Net, that incorporates channel attention to calibrate multi-scale channel features of hyperspectral images. Furthermore, we demonstrate, for the first time, that the low-rank property of the learnable upsampling layer is a key bottleneck in lightweight SHSR methods. To address this, we employ the low-rank approximation strategy to optimize the parameter redundancy of the learnable upsampling layer. Additionally, we introduce a knowledge distillation-based feature alignment technique to ensure the low-rank approximated network retains the same feature representation capacity as the original. We conducted extensive experiments on the Chikusei, Houston 2018, and Pavia Center datasets compared to some SOTAs. The results demonstrate that our method is competitive in performance while achieving speedups of several dozen to even hundreds of times compared to other well-performing SHSR methods.
Semi-supervised Semantic Segmentation for Remote Sensing Images via Multi-scale Uncertainty Consistency and Cross-Teacher-Student Attention
Jan 18, 2025Semi-supervised learning offers an appealing solution for remote sensing (RS) image segmentation to relieve the burden of labor-intensive pixel-level labeling. However, RS images pose unique challenges, including rich multi-scale features and high inter-class similarity. To address these problems, this paper proposes a novel semi-supervised Multi-Scale Uncertainty and Cross-Teacher-Student Attention (MUCA) model for RS image semantic segmentation tasks. Specifically, MUCA constrains the consistency among feature maps at different layers of the network by introducing a multi-scale uncertainty consistency regularization. It improves the multi-scale learning capability of semi-supervised algorithms on unlabeled data. Additionally, MUCA utilizes a Cross-Teacher-Student attention mechanism to guide the student network, guiding the student network to construct more discriminative feature representations through complementary features from the teacher network. This design effectively integrates weak and strong augmentations (WA and SA) to further boost segmentation performance. To verify the effectiveness of our model, we conduct extensive experiments on ISPRS-Potsdam and LoveDA datasets. The experimental results show the superiority of our method over state-of-the-art semi-supervised methods. Notably, our model excels in distinguishing highly similar objects, showcasing its potential for advancing semi-supervised RS image segmentation tasks.
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
A Knowledge-enhanced Pathology Vision-language Foundation Model for Cancer Diagnosis
Dec 17, 2024

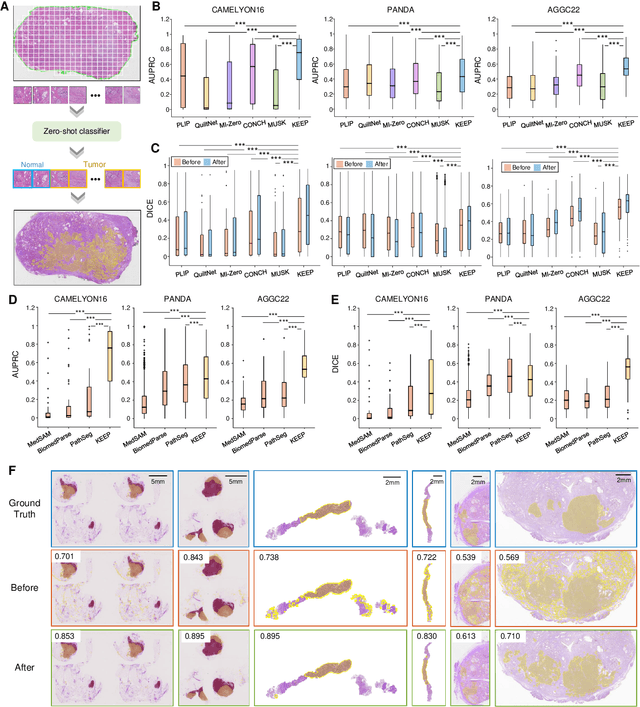

Deep learning has enabled the development of highly robust foundation models for various pathological tasks across diverse diseases and patient cohorts. Among these models, vision-language pre-training, which leverages large-scale paired data to align pathology image and text embedding spaces, and provides a novel zero-shot paradigm for downstream tasks. However, existing models have been primarily data-driven and lack the incorporation of domain-specific knowledge, which limits their performance in cancer diagnosis, especially for rare tumor subtypes. To address this limitation, we establish a Knowledge-enhanced Pathology (KEEP) foundation model that harnesses disease knowledge to facilitate vision-language pre-training. Specifically, we first construct a disease knowledge graph (KG) that covers 11,454 human diseases with 139,143 disease attributes, including synonyms, definitions, and hypernym relations. We then systematically reorganize the millions of publicly available noisy pathology image-text pairs, into 143K well-structured semantic groups linked through the hierarchical relations of the disease KG. To derive more nuanced image and text representations, we propose a novel knowledge-enhanced vision-language pre-training approach that integrates disease knowledge into the alignment within hierarchical semantic groups instead of unstructured image-text pairs. Validated on 18 diverse benchmarks with more than 14,000 whole slide images (WSIs), KEEP achieves state-of-the-art performance in zero-shot cancer diagnostic tasks. Notably, for cancer detection, KEEP demonstrates an average sensitivity of 89.8% at a specificity of 95.0% across 7 cancer types. For cancer subtyping, KEEP achieves a median balanced accuracy of 0.456 in subtyping 30 rare brain cancers, indicating strong generalizability for diagnosing rare tumors.
AuscultaBase: A Foundational Step Towards AI-Powered Body Sound Diagnostics
Nov 12, 2024



Auscultation of internal body sounds is essential for diagnosing a range of health conditions, yet its effectiveness is often limited by clinicians' expertise and the acoustic constraints of human hearing, restricting its use across various clinical scenarios. To address these challenges, we introduce AuscultaBase, a foundational framework aimed at advancing body sound diagnostics through innovative data integration and contrastive learning techniques. Our contributions include the following: First, we compile AuscultaBase-Corpus, a large-scale, multi-source body sound database encompassing 11 datasets with 40,317 audio recordings and totaling 322.4 hours of heart, lung, and bowel sounds. Second, we develop AuscultaBase-Model, a foundational diagnostic model for body sounds, utilizing contrastive learning on the compiled corpus. Third, we establish AuscultaBase-Bench, a comprehensive benchmark containing 16 sub-tasks, assessing the performance of various open-source acoustic pre-trained models. Evaluation results indicate that our model outperforms all other open-source models in 12 out of 16 tasks, demonstrating the efficacy of our approach in advancing diagnostic capabilities for body sound analysis.