 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNüshuVoice: Reviving the Voice of Endangered Nüshu with Pitch-Aware Text-to-Speech
Jun 08, 2026Nüshu is an endangered phonetic script historically used by women in Jiangyong County, southern Hunan, China. While existing computational studies of Nüshu mainly focus on textual digitization and visual recognition, the acoustic reconstruction of its authentic pronunciation remains largely unexplored. Building a Nüshu text-to-speech (TTS) system is particularly challenging because available recordings are extremely limited and mostly consist of isolated syllable-level pronunciations rather than natural sentence-level utterances. In this work, we introduce NüshuVoice, the first TTS benchmark for Nüshu. We construct a sentence-level Nüshu text-to-audio dataset that aligns standardized Unicode Nüshu text, phonetic transcriptions, standard Chinese translations, and archival recordings. To synthesize speech under this extreme low-resource setting, we propose Nüshu-PitchVITS, an F0-conditioned VITS framework that leverages Nüshu's five-level pitch notation as an explicit prosodic inductive bias. Experimental results show that Nüshu-PitchVITS outperforms strong TTS baselines in spectral fidelity, pitch reconstruction, and human-rated intelligibility. We publicly release the dataset and code at: https://anonymous.4open.science/r/Nvshu-TTS-2EB6.
Reasoning as an Attack Surface: Adaptive Evolutionary CoT Jailbreaks for LLMs
May 23, 2026Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in reasoning and generation tasks and are increasingly deployed in real-world applications. However, their explicit chain-of-thought (CoT) mechanism introduces new security risks, making them particularly vulnerable to jailbreak attacks. Existing approaches often rely on static CoT templates to elicit harmful outputs, but such fixed designs suffer from limited diversity, adaptability, and effectiveness. To overcome these limitations, we propose an adaptive evolutionary CoT jailbreak framework, called AE-CoT. Specifically, the method first rewrites harmful goals into mild prompts with teacher role-play and decomposes them into semantically coherent reasoning fragments to construct a pool of CoT jailbreak candidates. Then, within a structured representation space, we perform multi-generation evolutionary search, where candidate diversity is expanded through fragment-level crossover and a mutation strategy with an adaptive mutation-rate control mechanism. An independent scoring model provides graded harmfulness evaluations, and high-scoring candidates are further enhanced with a harmful CoT template to induce more destructive generations. Extensive experiments across multiple models and datasets demonstrate the effectiveness of the proposed AE-CoT, consistently outperforming state-of-the-art jailbreak methods.
DeAR: Fine-Grained VLM Adaptation by Decomposing Attention Head Roles
Mar 01, 2026Prompt learning is a dominant paradigm for adapting pre-trained Vision-Language Models (VLMs) to downstream tasks. However, existing methods often rely on a simplistic, layer-centric view, assuming shallow layers capture general features while deep layers handle task-specific knowledge. This assumption results in uncontrolled interactions between learnable tokens and original tokens. Task-specific knowledge could degrades the model's core generalization and creates a trade-off between task adaptation and the preservation of zero-shot generalization. To address this, we challenge the layer-centric view and propose \textbf{DeAR}, a framework that achieves fine-grained VLM adaptation by \textbf{De}composing \textbf{A}ttention head \textbf{R}oles. We posit that the functional specialization within VLMs occurs not between layers, but at the finer-grained level of individual attention heads in the deeper layers. Based on this insight, we introduce a novel metric, Concept Entropy, to systematically classify attention heads into distinct functional roles: \textit{Attribute}, \textit{Generalization}, and \textit{Mixed}. Guided by these roles, we introduce specialized attribute tokens and a Role-Based Attention Mask mechanism to precisely control information flow, ensuring generalization heads remain isolated from task-specific knowledge. We further incorporate a Task-Adaptive Fusion Strategy for inference. Extensive experiments on fifteen datasets show that DeAR achieves a strong balance between task adaptation and generalization, outperforming previous methods across various tasks.
IMMACULATE: A Practical LLM Auditing Framework via Verifiable Computation
Feb 26, 2026Commercial large language models are typically deployed as black-box API services, requiring users to trust providers to execute inference correctly and report token usage honestly. We present IMMACULATE, a practical auditing framework that detects economically motivated deviations-such as model substitution, quantization abuse, and token overbilling-without trusted hardware or access to model internals. IMMACULATE selectively audits a small fraction of requests using verifiable computation, achieving strong detection guarantees while amortizing cryptographic overhead. Experiments on dense and MoE models show that IMMACULATE reliably distinguishes benign and malicious executions with under 1% throughput overhead. Our code is published at https://github.com/guo-yanpei/Immaculate.
How Implicit Bias Accumulates and Propagates in LLM Long-term Memory
Feb 02, 2026Long-term memory mechanisms enable Large Language Models (LLMs) to maintain continuity and personalization across extended interaction lifecycles, but they also introduce new and underexplored risks related to fairness. In this work, we study how implicit bias, defined as subtle statistical prejudice, accumulates and propagates within LLMs equipped with long-term memory. To support systematic analysis, we introduce the Decision-based Implicit Bias (DIB) Benchmark, a large-scale dataset comprising 3,776 decision-making scenarios across nine social domains, designed to quantify implicit bias in long-term decision processes. Using a realistic long-horizon simulation framework, we evaluate six state-of-the-art LLMs integrated with three representative memory architectures on DIB and demonstrate that LLMs' implicit bias does not remain static but intensifies over time and propagates across unrelated domains. We further analyze mitigation strategies and show that a static system-level prompting baseline provides limited and short-lived debiasing effects. To address this limitation, we propose Dynamic Memory Tagging (DMT), an agentic intervention that enforces fairness constraints at memory write time. Extensive experimental results show that DMT substantially reduces bias accumulation and effectively curtails cross-domain bias propagation.
DP-MGTD: Privacy-Preserving Machine-Generated Text Detection via Adaptive Differentially Private Entity Sanitization
Jan 08, 2026The deployment of Machine-Generated Text (MGT) detection systems necessitates processing sensitive user data, creating a fundamental conflict between authorship verification and privacy preservation. Standard anonymization techniques often disrupt linguistic fluency, while rigorous Differential Privacy (DP) mechanisms typically degrade the statistical signals required for accurate detection. To resolve this dilemma, we propose \textbf{DP-MGTD}, a framework incorporating an Adaptive Differentially Private Entity Sanitization algorithm. Our approach utilizes a two-stage mechanism that performs noisy frequency estimation and dynamically calibrates privacy budgets, applying Laplace and Exponential mechanisms to numerical and textual entities respectively. Crucially, we identify a counter-intuitive phenomenon where the application of DP noise amplifies the distinguishability between human and machine text by exposing distinct sensitivity patterns to perturbation. Extensive experiments on the MGTBench-2.0 dataset show that our method achieves near-perfect detection accuracy, significantly outperforming non-private baselines while satisfying strict privacy guarantees.
AppellateGen: A Benchmark for Appellate Legal Judgment Generation
Jan 08, 2026Legal judgment generation is a critical task in legal intelligence. However, existing research in legal judgment generation has predominantly focused on first-instance trials, relying on static fact-to-verdict mappings while neglecting the dialectical nature of appellate (second-instance) review. To address this, we introduce AppellateGen, a benchmark for second-instance legal judgment generation comprising 7,351 case pairs. The task requires models to draft legally binding judgments by reasoning over the initial verdict and evidentiary updates, thereby modeling the causal dependency between trial stages. We further propose a judicial Standard Operating Procedure (SOP)-based Legal Multi-Agent System (SLMAS) to simulate judicial workflows, which decomposes the generation process into discrete stages of issue identification, retrieval, and drafting. Experimental results indicate that while SLMAS improves logical consistency, the complexity of appellate reasoning remains a substantial challenge for current LLMs. The dataset and code are publicly available at: https://anonymous.4open.science/r/AppellateGen-5763.
SugarTextNet: A Transformer-Based Framework for Detecting Sugar Dating-Related Content on Social Media with Context-Aware Focal Loss
Nov 11, 2025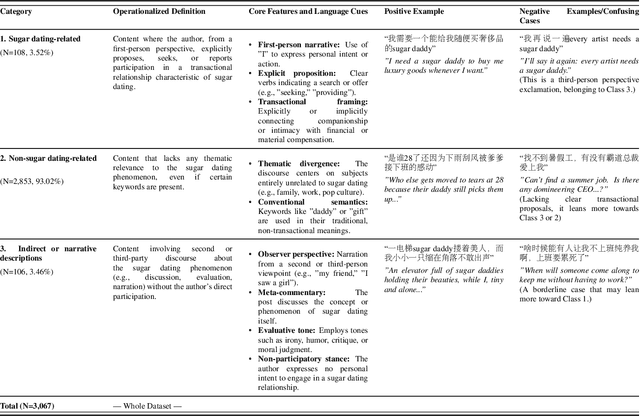
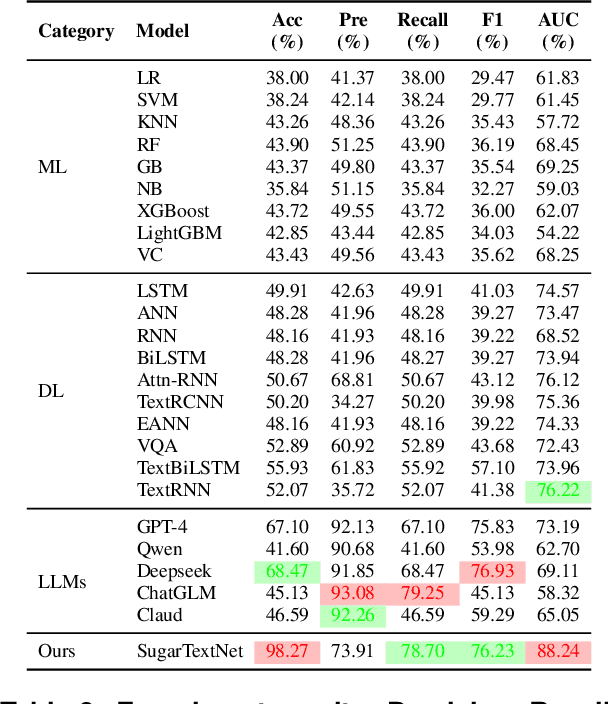

Sugar dating-related content has rapidly proliferated on mainstream social media platforms, giving rise to serious societal and regulatory concerns, including commercialization of intimate relationships and the normalization of transactional relationships.~Detecting such content is highly challenging due to the prevalence of subtle euphemisms, ambiguous linguistic cues, and extreme class imbalance in real-world data.~In this work, we present SugarTextNet, a novel transformer-based framework specifically designed to identify sugar dating-related posts on social media.~SugarTextNet integrates a pretrained transformer encoder, an attention-based cue extractor, and a contextual phrase encoder to capture both salient and nuanced features in user-generated text.~To address class imbalance and enhance minority-class detection, we introduce Context-Aware Focal Loss, a tailored loss function that combines focal loss scaling with contextual weighting.~We evaluate SugarTextNet on a newly curated, manually annotated dataset of 3,067 Chinese social media posts from Sina Weibo, demonstrating that our approach substantially outperforms traditional machine learning models, deep learning baselines, and large language models across multiple metrics.~Comprehensive ablation studies confirm the indispensable role of each component.~Our findings highlight the importance of domain-specific, context-aware modeling for sensitive content detection, and provide a robust solution for content moderation in complex, real-world scenarios.
Sub-Clustering for Class Distance Recalculation in Long-Tailed Drug Classification
Apr 07, 2025In the real world, long-tailed data distributions are prevalent, making it challenging for models to effectively learn and classify tail classes. However, we discover that in the field of drug chemistry, certain tail classes exhibit higher identifiability during training due to their unique molecular structural features, a finding that significantly contrasts with the conventional understanding that tail classes are generally difficult to identify. Existing imbalance learning methods, such as resampling and cost-sensitive reweighting, overly rely on sample quantity priors, causing models to excessively focus on tail classes at the expense of head class performance. To address this issue, we propose a novel method that breaks away from the traditional static evaluation paradigm based on sample size. Instead, we establish a dynamical inter-class separability metric using feature distances between different classes. Specifically, we employ a sub-clustering contrastive learning approach to thoroughly learn the embedding features of each class, and we dynamically compute the distances between class embeddings to capture the relative positional evolution of samples from different classes in the feature space, thereby rebalancing the weights of the classification loss function. We conducted experiments on multiple existing long-tailed drug datasets and achieved competitive results by improving the accuracy of tail classes without compromising the performance of dominant classes.
JiraiBench: A Bilingual Benchmark for Evaluating Large Language Models' Detection of Human Self-Destructive Behavior Content in Jirai Community
Mar 27, 2025



This paper introduces JiraiBench, the first bilingual benchmark for evaluating large language models' effectiveness in detecting self-destructive content across Chinese and Japanese social media communities. Focusing on the transnational "Jirai" (landmine) online subculture that encompasses multiple forms of self-destructive behaviors including drug overdose, eating disorders, and self-harm, we present a comprehensive evaluation framework incorporating both linguistic and cultural dimensions. Our dataset comprises 10,419 Chinese posts and 5,000 Japanese posts with multidimensional annotation along three behavioral categories, achieving substantial inter-annotator agreement. Experimental evaluations across four state-of-the-art models reveal significant performance variations based on instructional language, with Japanese prompts unexpectedly outperforming Chinese prompts when processing Chinese content. This emergent cross-cultural transfer suggests that cultural proximity can sometimes outweigh linguistic similarity in detection tasks. Cross-lingual transfer experiments with fine-tuned models further demonstrate the potential for knowledge transfer between these language systems without explicit target language training. These findings highlight the need for culturally-informed approaches to multilingual content moderation and provide empirical evidence for the importance of cultural context in developing more effective detection systems for vulnerable online communities.