 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time
Dec 31, 2025We present SpaceTimePilot, a video diffusion model that disentangles space and time for controllable generative rendering. Given a monocular video, SpaceTimePilot can independently alter the camera viewpoint and the motion sequence within the generative process, re-rendering the scene for continuous and arbitrary exploration across space and time. To achieve this, we introduce an effective animation time-embedding mechanism in the diffusion process, allowing explicit control of the output video's motion sequence with respect to that of the source video. As no datasets provide paired videos of the same dynamic scene with continuous temporal variations, we propose a simple yet effective temporal-warping training scheme that repurposes existing multi-view datasets to mimic temporal differences. This strategy effectively supervises the model to learn temporal control and achieve robust space-time disentanglement. To further enhance the precision of dual control, we introduce two additional components: an improved camera-conditioning mechanism that allows altering the camera from the first frame, and CamxTime, the first synthetic space-and-time full-coverage rendering dataset that provides fully free space-time video trajectories within a scene. Joint training on the temporal-warping scheme and the CamxTime dataset yields more precise temporal control. We evaluate SpaceTimePilot on both real-world and synthetic data, demonstrating clear space-time disentanglement and strong results compared to prior work. Project page: https://zheninghuang.github.io/Space-Time-Pilot/ Code: https://github.com/ZheningHuang/spacetimepilot
Perm: A Parametric Representation for Multi-Style 3D Hair Modeling
Jul 31, 2024We present Perm, a learned parametric model of human 3D hair designed to facilitate various hair-related applications. Unlike previous work that jointly models the global hair shape and local strand details, we propose to disentangle them using a PCA-based strand representation in the frequency domain, thereby allowing more precise editing and output control. Specifically, we leverage our strand representation to fit and decompose hair geometry textures into low- to high-frequency hair structures. These decomposed textures are later parameterized with different generative models, emulating common stages in the hair modeling process. We conduct extensive experiments to validate the architecture design of \textsc{Perm}, and finally deploy the trained model as a generic prior to solve task-agnostic problems, further showcasing its flexibility and superiority in tasks such as 3D hair parameterization, hairstyle interpolation, single-view hair reconstruction, and hair-conditioned image generation. Our code and data will be available at: https://github.com/c-he/perm.
\textsc{Perm}: A Parametric Representation for Multi-Style 3D Hair Modeling
Jul 28, 2024We present \textsc{Perm}, a learned parametric model of human 3D hair designed to facilitate various hair-related applications. Unlike previous work that jointly models the global hair shape and local strand details, we propose to disentangle them using a PCA-based strand representation in the frequency domain, thereby allowing more precise editing and output control. Specifically, we leverage our strand representation to fit and decompose hair geometry textures into low- to high-frequency hair structures. These decomposed textures are later parameterized with different generative models, emulating common stages in the hair modeling process. We conduct extensive experiments to validate the architecture design of \textsc{Perm}, and finally deploy the trained model as a generic prior to solve task-agnostic problems, further showcasing its flexibility and superiority in tasks such as 3D hair parameterization, hairstyle interpolation, single-view hair reconstruction, and hair-conditioned image generation. Our code and data will be available at: \url{https://github.com/c-he/perm}.
Pattern Guided UV Recovery for Realistic Video Garment Texturing
Jul 14, 2024



The fast growth of E-Commerce creates a global market worth USD 821 billion for online fashion shopping. What unique about fashion presentation is that, the same design can usually be offered with different cloths textures. However, only real video capturing or manual per-frame editing can be used for virtual showcase on the same design with different textures, both of which are heavily labor intensive. In this paper, we present a pattern-based approach for UV and shading recovery from a captured real video so that the garment's texture can be replaced automatically. The core of our approach is a per-pixel UV regression module via blended-weight multilayer perceptrons (MLPs) driven by the detected discrete correspondences from the cloth pattern. We propose a novel loss on the Jacobian of the UV mapping to create pleasant seams around the folding areas and the boundary of occluded regions while avoiding UV distortion. We also adopts the temporal constraint to ensure consistency and accuracy in UV prediction across adjacent frames. We show that our approach is robust to a variety type of clothes, in the wild illuminations and with challenging motions. We show plausible texture replacement results in our experiment, in which the folding and overlapping of the garment can be greatly preserved. We also show clear qualitative and quantitative improvement compared to the baselines as well. With the one-click setup, we look forward to our approach contributing to the growth of fashion E-commerce.
Synergistic Global-space Camera and Human Reconstruction from Videos
May 23, 2024



Remarkable strides have been made in reconstructing static scenes or human bodies from monocular videos. Yet, the two problems have largely been approached independently, without much synergy. Most visual SLAM methods can only reconstruct camera trajectories and scene structures up to scale, while most HMR methods reconstruct human meshes in metric scale but fall short in reasoning with cameras and scenes. This work introduces Synergistic Camera and Human Reconstruction (SynCHMR) to marry the best of both worlds. Specifically, we design Human-aware Metric SLAM to reconstruct metric-scale camera poses and scene point clouds using camera-frame HMR as a strong prior, addressing depth, scale, and dynamic ambiguities. Conditioning on the dense scene recovered, we further learn a Scene-aware SMPL Denoiser to enhance world-frame HMR by incorporating spatio-temporal coherency and dynamic scene constraints. Together, they lead to consistent reconstructions of camera trajectories, human meshes, and dense scene point clouds in a common world frame. Project page: https://paulchhuang.github.io/synchmr
Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
Mar 15, 2023



Cinemagraphs are short looping videos created by adding subtle motions to a static image. This kind of media is popular and engaging. However, automatic generation of cinemagraphs is an underexplored area and current solutions require tedious low-level manual authoring by artists. In this paper, we present an automatic method that allows generating human cinemagraphs from single RGB images. We investigate the problem in the context of dressed humans under the wind. At the core of our method is a novel cyclic neural network that produces looping cinemagraphs for the target loop duration. To circumvent the problem of collecting real data, we demonstrate that it is possible, by working in the image normal space, to learn garment motion dynamics on synthetic data and generalize to real data. We evaluate our method on both synthetic and real data and demonstrate that it is possible to create compelling and plausible cinemagraphs from single RGB images.
Normal-guided Garment UV Prediction for Human Re-texturing
Mar 11, 2023



Clothes undergo complex geometric deformations, which lead to appearance changes. To edit human videos in a physically plausible way, a texture map must take into account not only the garment transformation induced by the body movements and clothes fitting, but also its 3D fine-grained surface geometry. This poses, however, a new challenge of 3D reconstruction of dynamic clothes from an image or a video. In this paper, we show that it is possible to edit dressed human images and videos without 3D reconstruction. We estimate a geometry aware texture map between the garment region in an image and the texture space, a.k.a, UV map. Our UV map is designed to preserve isometry with respect to the underlying 3D surface by making use of the 3D surface normals predicted from the image. Our approach captures the underlying geometry of the garment in a self-supervised way, requiring no ground truth annotation of UV maps and can be readily extended to predict temporally coherent UV maps. We demonstrate that our method outperforms the state-of-the-art human UV map estimation approaches on both real and synthetic data.
Learning Motion-Dependent Appearance for High-Fidelity Rendering of Dynamic Humans from a Single Camera
Mar 24, 2022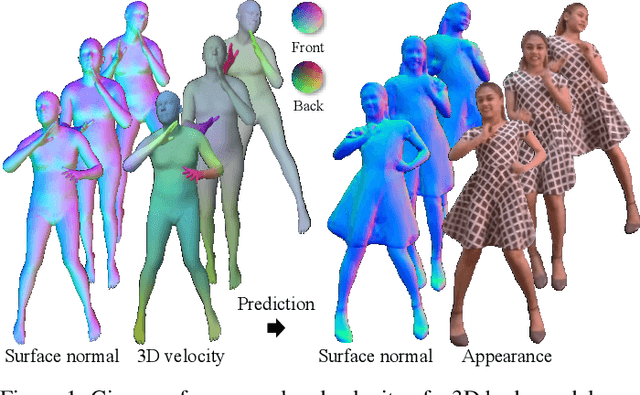

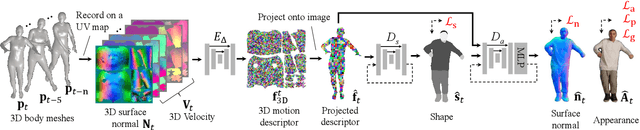

Appearance of dressed humans undergoes a complex geometric transformation induced not only by the static pose but also by its dynamics, i.e., there exists a number of cloth geometric configurations given a pose depending on the way it has moved. Such appearance modeling conditioned on motion has been largely neglected in existing human rendering methods, resulting in rendering of physically implausible motion. A key challenge of learning the dynamics of the appearance lies in the requirement of a prohibitively large amount of observations. In this paper, we present a compact motion representation by enforcing equivariance -- a representation is expected to be transformed in the way that the pose is transformed. We model an equivariant encoder that can generate the generalizable representation from the spatial and temporal derivatives of the 3D body surface. This learned representation is decoded by a compositional multi-task decoder that renders high fidelity time-varying appearance. Our experiments show that our method can generate a temporally coherent video of dynamic humans for unseen body poses and novel views given a single view video.
* CVPR accepted. 15 pages. 17 figures, 5 tables
Dance In the Wild: Monocular Human Animation with Neural Dynamic Appearance Synthesis
Nov 10, 2021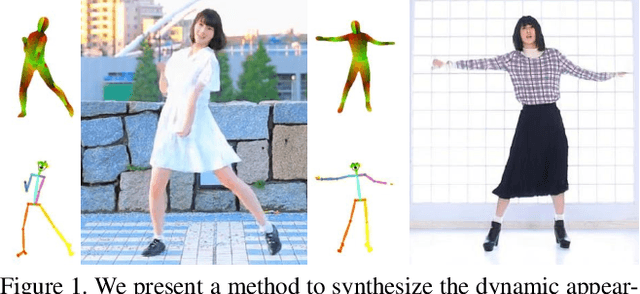
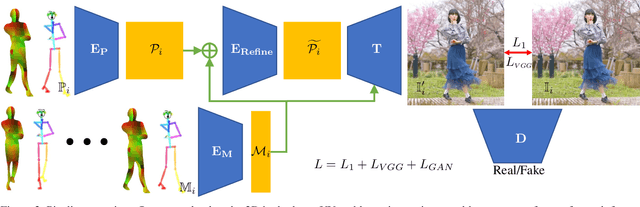
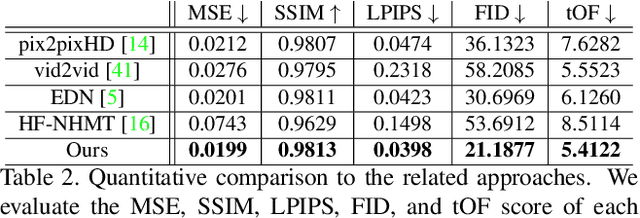
Synthesizing dynamic appearances of humans in motion plays a central role in applications such as AR/VR and video editing. While many recent methods have been proposed to tackle this problem, handling loose garments with complex textures and high dynamic motion still remains challenging. In this paper, we propose a video based appearance synthesis method that tackles such challenges and demonstrates high quality results for in-the-wild videos that have not been shown before. Specifically, we adopt a StyleGAN based architecture to the task of person specific video based motion retargeting. We introduce a novel motion signature that is used to modulate the generator weights to capture dynamic appearance changes as well as regularizing the single frame based pose estimates to improve temporal coherency. We evaluate our method on a set of challenging videos and show that our approach achieves state-of-the art performance both qualitatively and quantitatively.