 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Speech-to-Spatial: Grounding Utterances on A Live Shared View with Augmented Reality
Feb 03, 2026We introduce Speech-to-Spatial, a referent disambiguation framework that converts verbal remote-assistance instructions into spatially grounded AR guidance. Unlike prior systems that rely on additional cues (e.g., gesture, gaze) or manual expert annotations, Speech-to-Spatial infers the intended target solely from spoken references (speech input). Motivated by our formative study of speech referencing patterns, we characterize recurring ways people specify targets (Direct Attribute, Relational, Remembrance, and Chained) and ground them to our object-centric relational graph. Given an utterance, referent cues are parsed and rendered as persistent in-situ AR visual guidance, reducing iterative micro-guidance ("a bit more to the right", "now, stop.") during remote guidance. We demonstrate the use cases of our system with remote guided assistance and intent disambiguation scenarios. Our evaluation shows that Speechto-Spatial improves task efficiency, reduces cognitive load, and enhances usability compared to a conventional voice-only baseline, transforming disembodied verbal instruction into visually explainable, actionable guidance on a live shared view.
SpeechLess: Micro-utterance with Personalized Spatial Memory-aware Assistant in Everyday Augmented Reality
Jan 31, 2026Speaking aloud to a wearable AR assistant in public can be socially awkward, and re-articulating the same requests every day creates unnecessary effort. We present SpeechLess, a wearable AR assistant that introduces a speech-based intent granularity control paradigm grounded in personalized spatial memory. SpeechLess helps users "speak less," while still obtaining the information they need, and supports gradual explicitation of intent when more complex expression is required. SpeechLess binds prior interactions to multimodal personal context-space, time, activity, and referents-to form spatial memories, and leverages them to extrapolate missing intent dimensions from under-specified user queries. This enables users to dynamically adjust how explicitly they express their informational needs, from full-utterance to micro/zero-utterance interaction. We motivate our design through a week-long formative study using a commercial smart glasses platform, revealing discomfort with public voice use, frustration with repetitive speech, and hardware constraints. Building on these insights, we design SpeechLess, and evaluate it through controlled lab and in-the-wild studies. Our results indicate that regulated speech-based interaction, can improve everyday information access, reduce articulation effort, and support socially acceptable use without substantially degrading perceived usability or intent resolution accuracy across diverse everyday environments.
Evaluating Spatialized Auditory Cues for Rapid Attention Capture in XR
Jan 29, 2026In time-critical eXtended reality (XR) scenarios where users must rapidly reorient their attention to hazards, alerts, or instructions while engaged in a primary task, spatial audio can provide an immediate directional cue without occupying visual bandwidth. However, such scenarios can afford only a brief auditory exposure, requiring users to interpret sound direction quickly and without extended listening or head-driven refinement. This paper reports a controlled exploratory study of rapid spatial-audio localization in XR. Using HRTF-rendered broadband stimuli presented from a semi-dense set of directions around the listener, we quantify how accurately users can infer coarse direction from brief audio alone. We further examine the effects of short-term visuo-auditory feedback training as a lightweight calibration mechanism. Our findings show that brief spatial cues can convey coarse directional information, and that even short calibration can improve users' perception of aural signals. While these results highlight the potential of spatial audio for rapid attention guidance, they also show that auditory cues alone may not provide sufficient precision for complex or high-stakes tasks, and that spatial audio may be most effective when complemented by other sensory modalities or visual cues, without relying on head-driven refinement. We leverage this study on spatial audio as a preliminary investigation into a first-stage attention-guidance channel for wearable XR (e.g., VR head-mounted displays and AR smart glasses), and provide design insights on stimulus selection and calibration for time-critical use.
Progressive Autoregressive Video Diffusion Models
Oct 10, 2024Current frontier video diffusion models have demonstrated remarkable results at generating high-quality videos. However, they can only generate short video clips, normally around 10 seconds or 240 frames, due to computation limitations during training. In this work, we show that existing models can be naturally extended to autoregressive video diffusion models without changing the architectures. Our key idea is to assign the latent frames with progressively increasing noise levels rather than a single noise level, which allows for fine-grained condition among the latents and large overlaps between the attention windows. Such progressive video denoising allows our models to autoregressively generate video frames without quality degradation or abrupt scene changes. We present state-of-the-art results on long video generation at 1 minute (1440 frames at 24 FPS). Videos from this paper are available at https://desaixie.github.io/pa-vdm/.
LRM-Zero: Training Large Reconstruction Models with Synthesized Data
Jun 13, 2024



We present LRM-Zero, a Large Reconstruction Model (LRM) trained entirely on synthesized 3D data, achieving high-quality sparse-view 3D reconstruction. The core of LRM-Zero is our procedural 3D dataset, Zeroverse, which is automatically synthesized from simple primitive shapes with random texturing and augmentations (e.g., height fields, boolean differences, and wireframes). Unlike previous 3D datasets (e.g., Objaverse) which are often captured or crafted by humans to approximate real 3D data, Zeroverse completely ignores realistic global semantics but is rich in complex geometric and texture details that are locally similar to or even more intricate than real objects. We demonstrate that our LRM-Zero, trained with our fully synthesized Zeroverse, can achieve high visual quality in the reconstruction of real-world objects, competitive with models trained on Objaverse. We also analyze several critical design choices of Zeroverse that contribute to LRM-Zero's capability and training stability. Our work demonstrates that 3D reconstruction, one of the core tasks in 3D vision, can potentially be addressed without the semantics of real-world objects. The Zeroverse's procedural synthesis code and interactive visualization are available at: https://desaixie.github.io/lrm-zero/.
RT-GAN: Recurrent Temporal GAN for Adding Lightweight Temporal Consistency to Frame-Based Domain Translation Approaches
Oct 02, 2023



While developing new unsupervised domain translation methods for endoscopy videos, it is typical to start with approaches that initially work for individual frames without temporal consistency. Once an individual-frame model has been finalized, additional contiguous frames are added with a modified deep learning architecture to train a new model for temporal consistency. This transition to temporally-consistent deep learning models, however, requires significantly more computational and memory resources for training. In this paper, we present a lightweight solution with a tunable temporal parameter, RT-GAN (Recurrent Temporal GAN), for adding temporal consistency to individual frame-based approaches that reduces training requirements by a factor of 5. We demonstrate the effectiveness of our approach on two challenging use cases in colonoscopy: haustral fold segmentation (indicative of missed surface) and realistic colonoscopy simulator video generation. The datasets, accompanying code, and pretrained models will be made available at \url{https://github.com/nadeemlab/CEP}.
CLTS-GAN: Color-Lighting-Texture-Specular Reflection Augmentation for Colonoscopy
Jun 29, 2022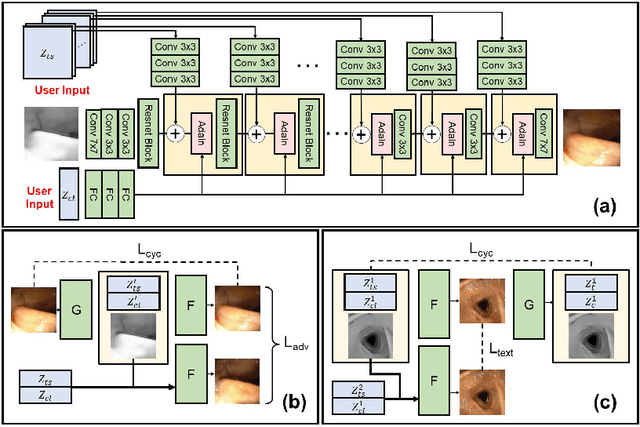


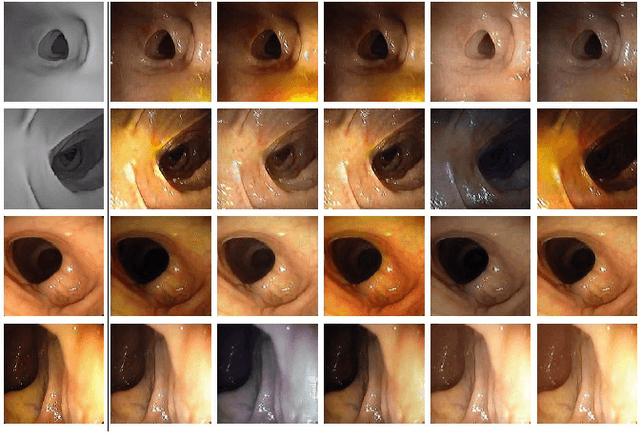
Automated analysis of optical colonoscopy (OC) video frames (to assist endoscopists during OC) is challenging due to variations in color, lighting, texture, and specular reflections. Previous methods either remove some of these variations via preprocessing (making pipelines cumbersome) or add diverse training data with annotations (but expensive and time-consuming). We present CLTS-GAN, a new deep learning model that gives fine control over color, lighting, texture, and specular reflection synthesis for OC video frames. We show that adding these colonoscopy-specific augmentations to the training data can improve state-of-the-art polyp detection/segmentation methods as well as drive next generation of OC simulators for training medical students. The code and pre-trained models for CLTS-GAN are available on Computational Endoscopy Platform GitHub (https://github.com/nadeemlab/CEP).
FoldIt: Haustral Folds Detection and Segmentation in Colonoscopy Videos
Jun 23, 2021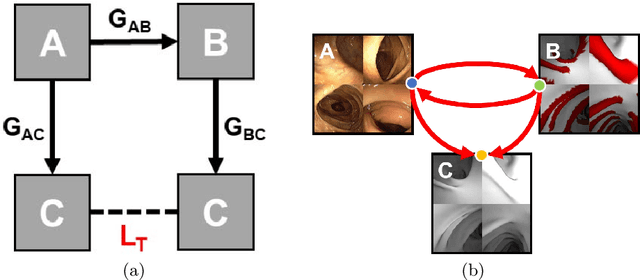


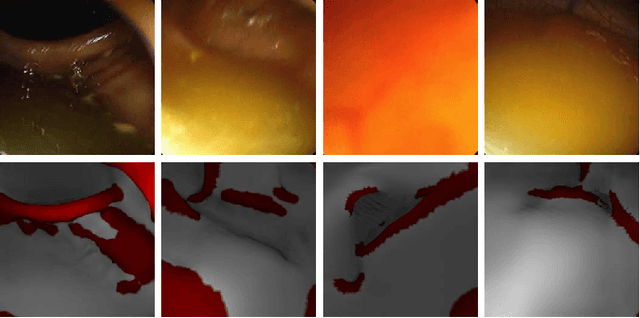
Haustral folds are colon wall protrusions implicated for high polyp miss rate during optical colonoscopy procedures. If segmented accurately, haustral folds can allow for better estimation of missed surface and can also serve as valuable landmarks for registering pre-treatment virtual (CT) and optical colonoscopies, to guide navigation towards the anomalies found in pre-treatment scans. We present a novel generative adversarial network, FoldIt, for feature-consistent image translation of optical colonoscopy videos to virtual colonoscopy renderings with haustral fold overlays. A new transitive loss is introduced in order to leverage ground truth information between haustral fold annotations and virtual colonoscopy renderings. We demonstrate the effectiveness of our model on real challenging optical colonoscopy videos as well as on textured virtual colonoscopy videos with clinician-verified haustral fold annotations. All code and scripts to reproduce the experiments of this paper will be made available via our Computational Endoscopy Platform at https://github.com/nadeemlab/CEP.
Visualizing Missing Surfaces In Colonoscopy Videos using Shared Latent Space Representations
Jan 18, 2021
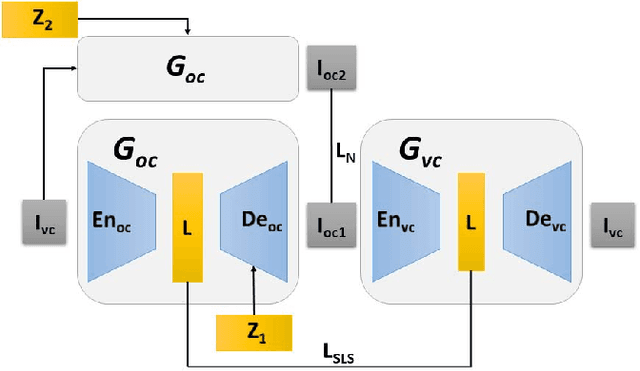
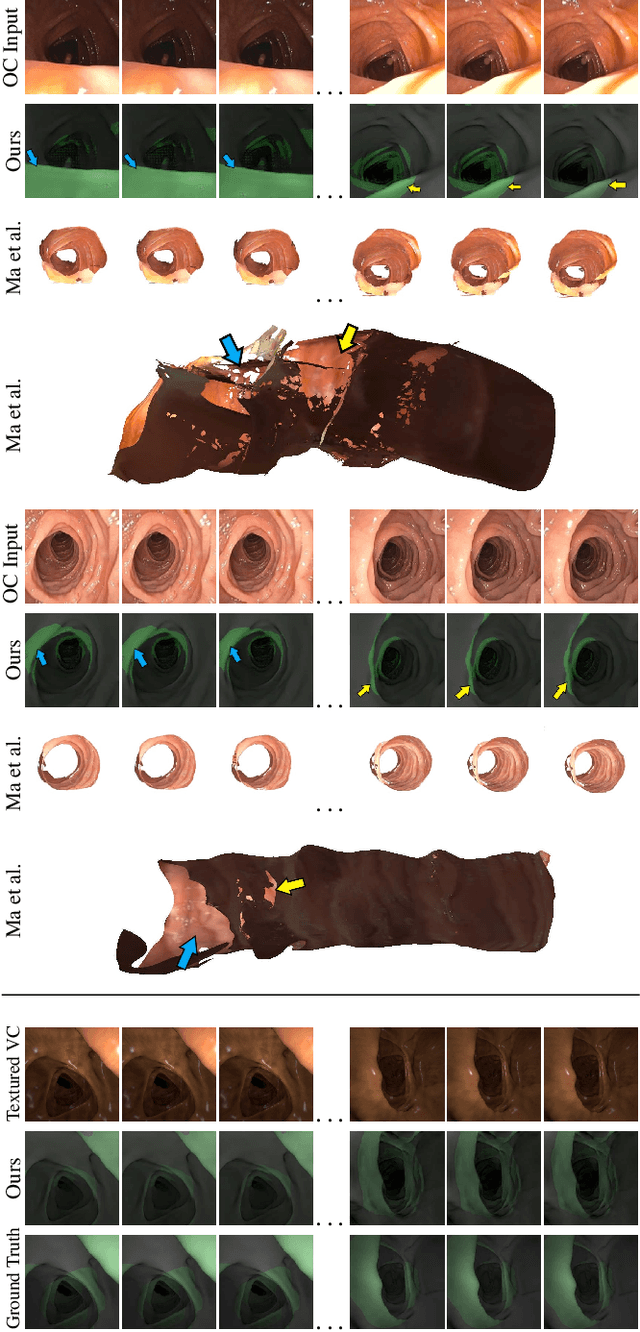
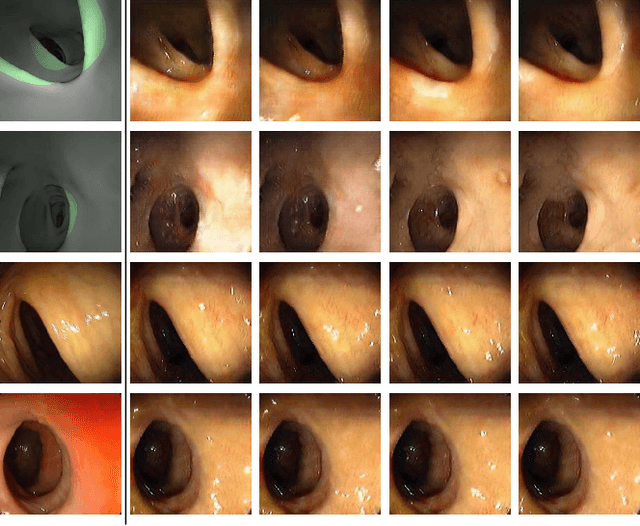
Optical colonoscopy (OC), the most prevalent colon cancer screening tool, has a high miss rate due to a number of factors, including the geometry of the colon (haustral fold and sharp bends occlusions), endoscopist inexperience or fatigue, endoscope field of view, etc. We present a framework to visualize the missed regions per-frame during the colonoscopy, and provides a workable clinical solution. Specifically, we make use of 3D reconstructed virtual colonoscopy (VC) data and the insight that VC and OC share the same underlying geometry but differ in color, texture and specular reflections, embedded in the OC domain. A lossy unpaired image-to-image translation model is introduced with enforced shared latent space for OC and VC. This shared latent space captures the geometric information while deferring the color, texture, and specular information creation to additional Gaussian noise input. This additional noise input can be utilized to generate one-to-many mappings from VC to OC and OC to OC.
Augmenting Colonoscopy using Extended and Directional CycleGAN for Lossy Image Translation
Mar 27, 2020
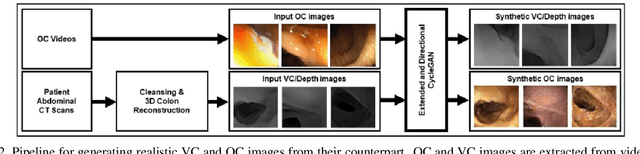
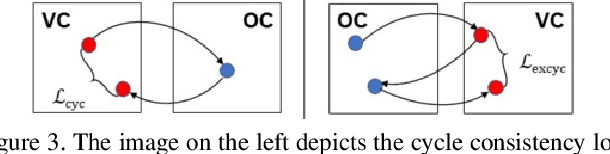
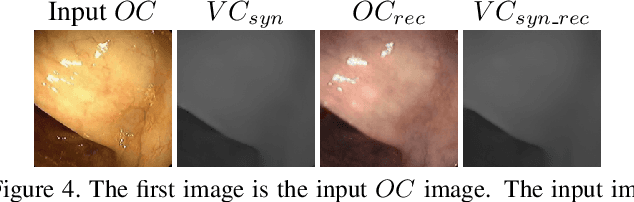
Colorectal cancer screening modalities, such as optical colonoscopy (OC) and virtual colonoscopy (VC), are critical for diagnosing and ultimately removing polyps (precursors of colon cancer). The non-invasive VC is normally used to inspect a 3D reconstructed colon (from CT scans) for polyps and if found, the OC procedure is performed to physically traverse the colon via endoscope and remove these polyps. In this paper, we present a deep learning framework, Extended and Directional CycleGAN, for lossy unpaired image-to-image translation between OC and VC to augment OC video sequences with scale-consistent depth information from VC, and augment VC with patient-specific textures, color and specular highlights from OC (e.g, for realistic polyp synthesis). Both OC and VC contain structural information, but it is obscured in OC by additional patient-specific texture and specular highlights, hence making the translation from OC to VC lossy. The existing CycleGAN approaches do not handle lossy transformations. To address this shortcoming, we introduce an extended cycle consistency loss, which compares the geometric structures from OC in the VC domain. This loss removes the need for the CycleGAN to embed OC information in the VC domain. To handle a stronger removal of the textures and lighting, a Directional Discriminator is introduced to differentiate the direction of translation (by creating paired information for the discriminator), as opposed to the standard CycleGAN which is direction-agnostic. Combining the extended cycle consistency loss and the Directional Discriminator, we show state-of-the-art results on scale-consistent depth inference for phantom, textured VC and for real polyp and normal colon video sequences. We also present results for realistic pendunculated and flat polyp synthesis from bumps introduced in 3D VC models.