 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hepatopathy Clinical Trial Efficiency: A Secure, Large Language Model-Powered Pre-Screening Pipeline
Feb 25, 2025Background: Recruitment for cohorts involving complex liver diseases, such as hepatocellular carcinoma and liver cirrhosis, often requires interpreting semantically complex criteria. Traditional manual screening methods are time-consuming and prone to errors. While AI-powered pre-screening offers potential solutions, challenges remain regarding accuracy, efficiency, and data privacy. Methods: We developed a novel patient pre-screening pipeline that leverages clinical expertise to guide the precise, safe, and efficient application of large language models. The pipeline breaks down complex criteria into a series of composite questions and then employs two strategies to perform semantic question-answering through electronic health records - (1) Pathway A, Anthropomorphized Experts' Chain of Thought strategy, and (2) Pathway B, Preset Stances within an Agent Collaboration strategy, particularly in managing complex clinical reasoning scenarios. The pipeline is evaluated on three key metrics-precision, time consumption, and counterfactual inference - at both the question and criterion levels. Results: Our pipeline achieved high precision (0.921, in criteria level) and efficiency (0.44s per task). Pathway B excelled in complex reasoning, while Pathway A was effective in precise data extraction with faster processing times. Both pathways achieved comparable precision. The pipeline showed promising results in hepatocellular carcinoma (0.878) and cirrhosis trials (0.843). Conclusions: This data-secure and time-efficient pipeline shows high precision in hepatopathy trials, providing promising solutions for streamlining clinical trial workflows. Its efficiency and adaptability make it suitable for improving patient recruitment. And its capability to function in resource-constrained environments further enhances its utility in clinical settings.
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
Feb 25, 2025



Data diversity is crucial for the instruction tuning of large language models. Existing studies have explored various diversity-aware data selection methods to construct high-quality datasets and enhance model performance. However, the fundamental problem of precisely defining and measuring data diversity remains underexplored, limiting clear guidance for data engineering. To address this, we systematically analyze 11 existing diversity measurement methods by evaluating their correlation with model performance through extensive fine-tuning experiments. Our results indicate that a reliable diversity measure should properly account for both inter-sample differences and the information distribution in the sample space. Building on this, we propose NovelSum, a new diversity metric based on sample-level "novelty." Experiments on both simulated and real-world data show that NovelSum accurately captures diversity variations and achieves a 0.97 correlation with instruction-tuned model performance, highlighting its value in guiding data engineering practices. With NovelSum as an optimization objective, we further develop a greedy, diversity-oriented data selection strategy that outperforms existing approaches, validating both the effectiveness and practical significance of our metric.
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025



We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
RAG-Gym: Optimizing Reasoning and Search Agents with Process Supervision
Feb 19, 2025



Retrieval-augmented generation (RAG) has shown great potential for knowledge-intensive tasks, but its traditional architectures rely on static retrieval, limiting their effectiveness for complex questions that require sequential information-seeking. While agentic reasoning and search offer a more adaptive approach, most existing methods depend heavily on prompt engineering. In this work, we introduce RAG-Gym, a unified optimization framework that enhances information-seeking agents through fine-grained process supervision at each search step. We also propose ReSearch, a novel agent architecture that synergizes answer reasoning and search query generation within the RAG-Gym framework. Experiments on four challenging datasets show that RAG-Gym improves performance by up to 25.6\% across various agent architectures, with ReSearch consistently outperforming existing baselines. Further analysis highlights the effectiveness of advanced LLMs as process reward judges and the transferability of trained reward models as verifiers for different LLMs. Additionally, we examine the scaling properties of training and inference in agentic RAG. The project homepage is available at https://rag-gym.github.io/.
Censor Dependent Variational Inference
Feb 13, 2025This paper provides a comprehensive analysis of variational inference in latent variable models for survival analysis, emphasizing the distinctive challenges associated with applying variational methods to survival data. We identify a critical weakness in the existing methodology, demonstrating how a poorly designed variational distribution may hinder the objective of survival analysis tasks--modeling time-to-event distributions. We prove that the optimal variational distribution, which perfectly bounds the log-likelihood, may depend on the censoring mechanism. To address this issue, we propose censor-dependent variational inference (CDVI), tailored for latent variable models in survival analysis. More practically, we introduce CD-CVAE, a V-structure Variational Autoencoder (VAE) designed for the scalable implementation of CDVI. Further discussion extends some existing theories and training techniques to survival analysis. Extensive experiments validate our analysis and demonstrate significant improvements in the estimation of individual survival distributions.
EventSTR: A Benchmark Dataset and Baselines for Event Stream based Scene Text Recognition
Feb 13, 2025Mainstream Scene Text Recognition (STR) algorithms are developed based on RGB cameras which are sensitive to challenging factors such as low illumination, motion blur, and cluttered backgrounds. In this paper, we propose to recognize the scene text using bio-inspired event cameras by collecting and annotating a large-scale benchmark dataset, termed EventSTR. It contains 9,928 high-definition (1280 * 720) event samples and involves both Chinese and English characters. We also benchmark multiple STR algorithms as the baselines for future works to compare. In addition, we propose a new event-based scene text recognition framework, termed SimC-ESTR. It first extracts the event features using a visual encoder and projects them into tokens using a Q-former module. More importantly, we propose to augment the vision tokens based on a memory mechanism before feeding into the large language models. A similarity-based error correction mechanism is embedded within the large language model to correct potential minor errors fundamentally based on contextual information. Extensive experiments on the newly proposed EventSTR dataset and two simulation STR datasets fully demonstrate the effectiveness of our proposed model. We believe that the dataset and algorithmic model can innovatively propose an event-based STR task and are expected to accelerate the application of event cameras in various industries. The source code and pre-trained models will be released on https://github.com/Event-AHU/EventSTR
Scaling Pre-training to One Hundred Billion Data for Vision Language Models
Feb 11, 2025We provide an empirical investigation of the potential of pre-training vision-language models on an unprecedented scale: 100 billion examples. We find that model performance tends to saturate at this scale on many common Western-centric classification and retrieval benchmarks, such as COCO Captions. Nevertheless, tasks of cultural diversity achieve more substantial gains from the 100-billion scale web data, thanks to its coverage of long-tail concepts. Furthermore, we analyze the model's multilinguality and show gains in low-resource languages as well. In addition, we observe that reducing the size of the pretraining dataset via quality filters like using CLIP, typically used to enhance performance, may inadvertently reduce the cultural diversity represented even in large-scale datasets. Our results highlight that while traditional benchmarks may not benefit significantly from scaling noisy, raw web data to 100 billion examples, this data scale is vital for building truly inclusive multimodal systems.
Event Stream-based Visual Object Tracking: HDETrack V2 and A High-Definition Benchmark
Feb 08, 2025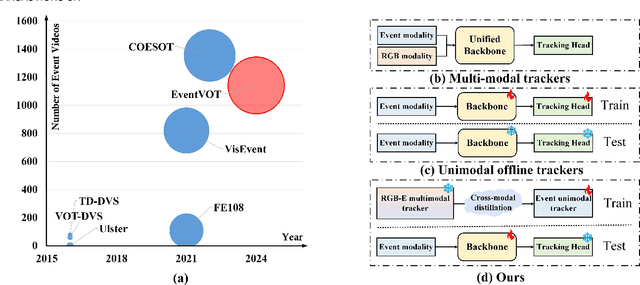

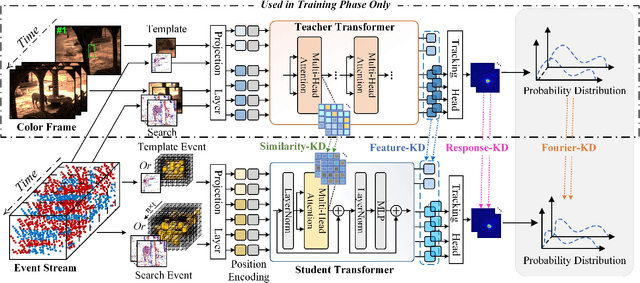

We then introduce a novel hierarchical knowledge distillation strategy that incorporates the similarity matrix, feature representation, and response map-based distillation to guide the learning of the student Transformer network. We also enhance the model's ability to capture temporal dependencies by applying the temporal Fourier transform to establish temporal relationships between video frames. We adapt the network model to specific target objects during testing via a newly proposed test-time tuning strategy to achieve high performance and flexibility in target tracking. Recognizing the limitations of existing event-based tracking datasets, which are predominantly low-resolution, we propose EventVOT, the first large-scale high-resolution event-based tracking dataset. It comprises 1141 videos spanning diverse categories such as pedestrians, vehicles, UAVs, ping pong, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, FELT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. Both the benchmark dataset and source code have been released on https://github.com/Event-AHU/EventVOT_Benchmark
XiHeFusion: Harnessing Large Language Models for Science Communication in Nuclear Fusion
Feb 08, 2025



Nuclear fusion is one of the most promising ways for humans to obtain infinite energy. Currently, with the rapid development of artificial intelligence, the mission of nuclear fusion has also entered a critical period of its development. How to let more people to understand nuclear fusion and join in its research is one of the effective means to accelerate the implementation of fusion. This paper proposes the first large model in the field of nuclear fusion, XiHeFusion, which is obtained through supervised fine-tuning based on the open-source large model Qwen2.5-14B. We have collected multi-source knowledge about nuclear fusion tasks to support the training of this model, including the common crawl, eBooks, arXiv, dissertation, etc. After the model has mastered the knowledge of the nuclear fusion field, we further used the chain of thought to enhance its logical reasoning ability, making XiHeFusion able to provide more accurate and logical answers. In addition, we propose a test questionnaire containing 180+ questions to assess the conversational ability of this science popularization large model. Extensive experimental results show that our nuclear fusion dialogue model, XiHeFusion, can perform well in answering science popularization knowledge. The pre-trained XiHeFusion model is released on https://github.com/Event-AHU/XiHeFusion.
Sparse Measurement Medical CT Reconstruction using Multi-Fused Block Matching Denoising Priors
Feb 03, 2025A major challenge for medical X-ray CT imaging is reducing the number of X-ray projections to lower radiation dosage and reduce scan times without compromising image quality. However these under-determined inverse imaging problems rely on the formulation of an expressive prior model to constrain the solution space while remaining computationally tractable. Traditional analytical reconstruction methods like Filtered Back Projection (FBP) often fail with sparse measurements, producing artifacts due to their reliance on the Shannon-Nyquist Sampling Theorem. Consensus Equilibrium, which is a generalization of Plug and Play, is a recent advancement in Model-Based Iterative Reconstruction (MBIR), has facilitated the use of multiple denoisers are prior models in an optimization free framework to capture complex, non-linear prior information. However, 3D prior modelling in a Plug and Play approach for volumetric image reconstruction requires long processing time due to high computing requirement. Instead of directly using a 3D prior, this work proposes a BM3D Multi Slice Fusion (BM3D-MSF) prior that uses multiple 2D image denoisers fused to act as a fully 3D prior model in Plug and Play reconstruction approach. Our approach does not require training and are thus able to circumvent ethical issues related with patient training data and are readily deployable in varying noise and measurement sparsity levels. In addition, reconstruction with the BM3D-MSF prior achieves similar reconstruction image quality as fully 3D image priors, but with significantly reduced computational complexity. We test our method on clinical CT data and demonstrate that our approach improves reconstructed image quality.