 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Test 2025: Challenge Summary and a Unified VQA Extension
Jan 09, 2026The Third Perception Test challenge was organised as a full-day workshop alongside the IEEE/CVF International Conference on Computer Vision (ICCV) 2025. Its primary goal is to benchmark state-of-the-art video models and measure the progress in multimodal perception. This year, the workshop featured 2 guest tracks as well: KiVA (an image understanding challenge) and Physic-IQ (a video generation challenge). In this report, we summarise the results from the main Perception Test challenge, detailing both the existing tasks as well as novel additions to the benchmark. In this iteration, we placed an emphasis on task unification, as this poses a more challenging test for current SOTA multimodal models. The challenge included five consolidated tracks: unified video QA, unified object and point tracking, unified action and sound localisation, grounded video QA, and hour-long video QA, alongside an analysis and interpretability track that is still open for submissions. Notably, the unified video QA track introduced a novel subset that reformulates traditional perception tasks (such as point tracking and temporal action localisation) as multiple-choice video QA questions that video-language models can natively tackle. The unified object and point tracking merged the original object tracking and point tracking tasks, whereas the unified action and sound localisation merged the original temporal action localisation and temporal sound localisation tracks. Accordingly, we required competitors to use unified approaches rather than engineered pipelines with task-specific models. By proposing such a unified challenge, Perception Test 2025 highlights the significant difficulties existing models face when tackling diverse perception tasks through unified interfaces.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
Token Cropr: Faster ViTs for Quite a Few Tasks
Dec 01, 2024



The adoption of Vision Transformers (ViTs) in resource-constrained applications necessitates improvements in inference throughput. To this end several token pruning and merging approaches have been proposed that improve efficiency by successively reducing the number of tokens. However, it remains an open problem to design a token reduction method that is fast, maintains high performance, and is applicable to various vision tasks. In this work, we present a token pruner that uses auxiliary prediction heads that learn to select tokens end-to-end based on task relevance. These auxiliary heads can be removed after training, leading to throughput close to that of a random pruner. We evaluate our method on image classification, semantic segmentation, object detection, and instance segmentation, and show speedups of 1.5 to 4x with small drops in performance. As a best case, on the ADE20k semantic segmentation benchmark, we observe a 2x speedup relative to the no-pruning baseline, with a negligible performance penalty of 0.1 median mIoU across 5 seeds.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Invariant Slot Attention: Object Discovery with Slot-Centric Reference Frames
Feb 09, 2023



Automatically discovering composable abstractions from raw perceptual data is a long-standing challenge in machine learning. Recent slot-based neural networks that learn about objects in a self-supervised manner have made exciting progress in this direction. However, they typically fall short at adequately capturing spatial symmetries present in the visual world, which leads to sample inefficiency, such as when entangling object appearance and pose. In this paper, we present a simple yet highly effective method for incorporating spatial symmetries via slot-centric reference frames. We incorporate equivariance to per-object pose transformations into the attention and generation mechanism of Slot Attention by translating, scaling, and rotating position encodings. These changes result in little computational overhead, are easy to implement, and can result in large gains in terms of data efficiency and overall improvements to object discovery. We evaluate our method on a wide range of synthetic object discovery benchmarks namely CLEVR, Tetrominoes, CLEVRTex, Objects Room and MultiShapeNet, and show promising improvements on the challenging real-world Waymo Open dataset.
RUST: Latent Neural Scene Representations from Unposed Imagery
Nov 25, 2022



Inferring the structure of 3D scenes from 2D observations is a fundamental challenge in computer vision. Recently popularized approaches based on neural scene representations have achieved tremendous impact and have been applied across a variety of applications. One of the major remaining challenges in this space is training a single model which can provide latent representations which effectively generalize beyond a single scene. Scene Representation Transformer (SRT) has shown promise in this direction, but scaling it to a larger set of diverse scenes is challenging and necessitates accurately posed ground truth data. To address this problem, we propose RUST (Really Unposed Scene representation Transformer), a pose-free approach to novel view synthesis trained on RGB images alone. Our main insight is that one can train a Pose Encoder that peeks at the target image and learns a latent pose embedding which is used by the decoder for view synthesis. We perform an empirical investigation into the learned latent pose structure and show that it allows meaningful test-time camera transformations and accurate explicit pose readouts. Perhaps surprisingly, RUST achieves similar quality as methods which have access to perfect camera pose, thereby unlocking the potential for large-scale training of amortized neural scene representations.
Iterative Patch Selection for High-Resolution Image Recognition
Oct 24, 2022



High-resolution images are prevalent in various applications, such as autonomous driving and computer-aided diagnosis. However, training neural networks on such images is computationally challenging and easily leads to out-of-memory errors even on modern GPUs. We propose a simple method, Iterative Patch Selection (IPS), which decouples the memory usage from the input size and thus enables the processing of arbitrarily large images under tight hardware constraints. IPS achieves this by selecting only the most salient patches, which are then aggregated into a global representation for image recognition. For both patch selection and aggregation, a cross-attention based transformer is introduced, which exhibits a close connection to Multiple Instance Learning. Our method demonstrates strong performance and has wide applicability across different domains, training regimes and image sizes while using minimal accelerator memory. For example, we are able to finetune our model on whole-slide images consisting of up to 250k patches (>16 gigapixels) with only 5 GB of GPU VRAM at a batch size of 16.
SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos
Jun 15, 2022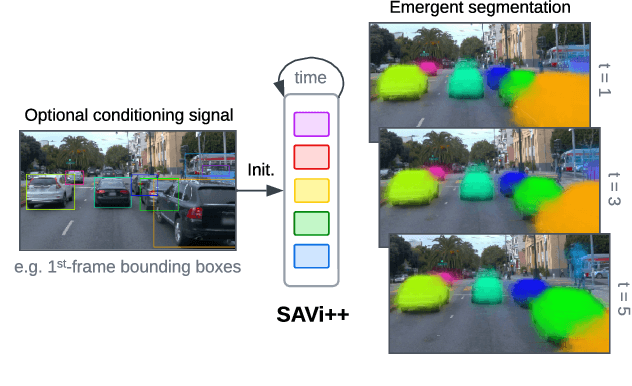
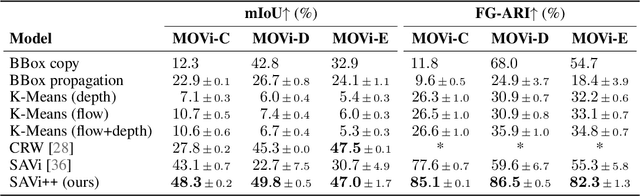
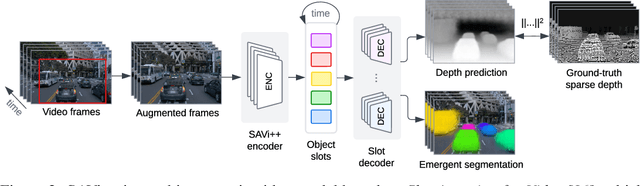

The visual world can be parsimoniously characterized in terms of distinct entities with sparse interactions. Discovering this compositional structure in dynamic visual scenes has proven challenging for end-to-end computer vision approaches unless explicit instance-level supervision is provided. Slot-based models leveraging motion cues have recently shown great promise in learning to represent, segment, and track objects without direct supervision, but they still fail to scale to complex real-world multi-object videos. In an effort to bridge this gap, we take inspiration from human development and hypothesize that information about scene geometry in the form of depth signals can facilitate object-centric learning. We introduce SAVi++, an object-centric video model which is trained to predict depth signals from a slot-based video representation. By further leveraging best practices for model scaling, we are able to train SAVi++ to segment complex dynamic scenes recorded with moving cameras, containing both static and moving objects of diverse appearance on naturalistic backgrounds, without the need for segmentation supervision. Finally, we demonstrate that by using sparse depth signals obtained from LiDAR, SAVi++ is able to learn emergent object segmentation and tracking from videos in the real-world Waymo Open dataset.
Object Scene Representation Transformer
Jun 14, 2022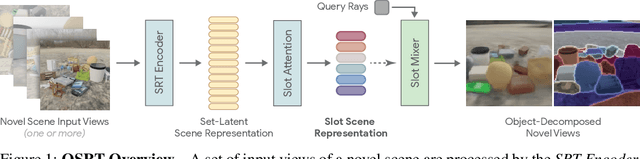

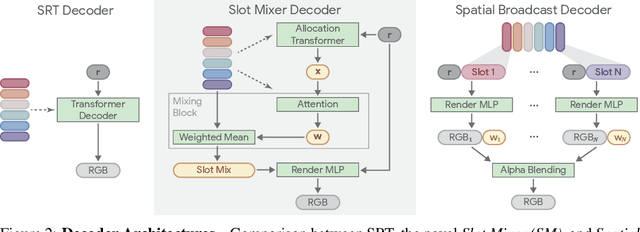
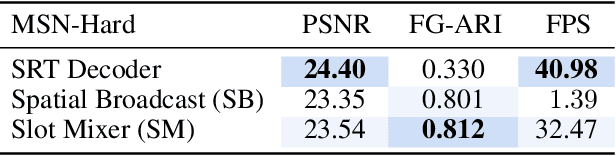
A compositional understanding of the world in terms of objects and their geometry in 3D space is considered a cornerstone of human cognition. Facilitating the learning of such a representation in neural networks holds promise for substantially improving labeled data efficiency. As a key step in this direction, we make progress on the problem of learning 3D-consistent decompositions of complex scenes into individual objects in an unsupervised fashion. We introduce Object Scene Representation Transformer (OSRT), a 3D-centric model in which individual object representations naturally emerge through novel view synthesis. OSRT scales to significantly more complex scenes with larger diversity of objects and backgrounds than existing methods. At the same time, it is multiple orders of magnitude faster at compositional rendering thanks to its light field parametrization and the novel Slot Mixer decoder. We believe this work will not only accelerate future architecture exploration and scaling efforts, but it will also serve as a useful tool for both object-centric as well as neural scene representation learning communities.
Simple Open-Vocabulary Object Detection with Vision Transformers
May 12, 2022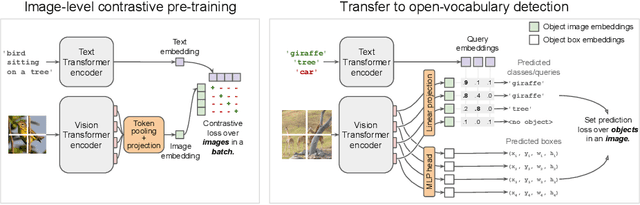
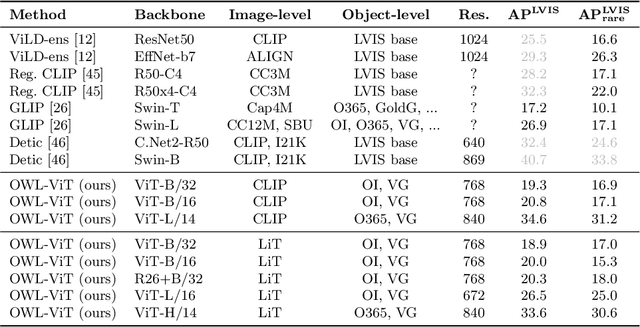
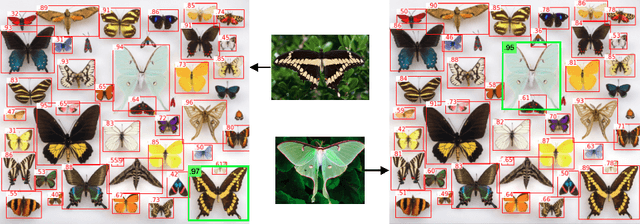
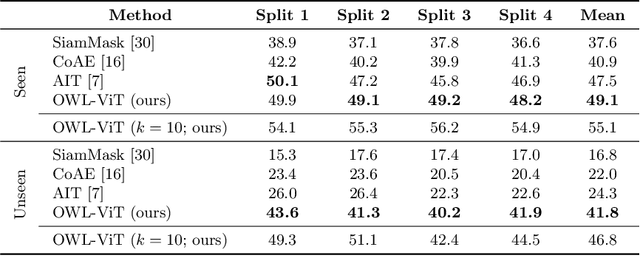
Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.