 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb-Scale Visual Entity Recognition: An LLM-Driven Data Approach
Oct 31, 2024



Web-scale visual entity recognition, the task of associating images with their corresponding entities within vast knowledge bases like Wikipedia, presents significant challenges due to the lack of clean, large-scale training data. In this paper, we propose a novel methodology to curate such a dataset, leveraging a multimodal large language model (LLM) for label verification, metadata generation, and rationale explanation. Instead of relying on the multimodal LLM to directly annotate data, which we found to be suboptimal, we prompt it to reason about potential candidate entity labels by accessing additional contextually relevant information (such as Wikipedia), resulting in more accurate annotations. We further use the multimodal LLM to enrich the dataset by generating question-answer pairs and a grounded finegrained textual description (referred to as "rationale") that explains the connection between images and their assigned entities. Experiments demonstrate that models trained on this automatically curated data achieve state-of-the-art performance on web-scale visual entity recognition tasks (e.g. +6.9% improvement in OVEN entity task), underscoring the importance of high-quality training data in this domain.
Self-Masking Networks for Unsupervised Adaptation
Sep 11, 2024



With the advent of billion-parameter foundation models, efficient fine-tuning has become increasingly important for the adaptation of models to downstream tasks. However, especially in computer vision, it can be hard to achieve good performance when access to quality labeled data is lacking. In this work, we propose a method adapting pretrained generalist models in a self-supervised manner by learning binary masks. These self-supervised masking networks (SMNs) are up to 79x more efficient to store and significantly improve performance on label-efficient downstream tasks. We validate the usefulness of learning binary masks as a fine-tuning method on 8 datasets and 3 model architectures, and we demonstrate the effectiveness of SMNs in 3 label-efficient settings.
A Generative Approach for Wikipedia-Scale Visual Entity Recognition
Mar 04, 2024In this paper, we address web-scale visual entity recognition, specifically the task of mapping a given query image to one of the 6 million existing entities in Wikipedia. One way of approaching a problem of such scale is using dual-encoder models (eg CLIP), where all the entity names and query images are embedded into a unified space, paving the way for an approximate k-NN search. Alternatively, it is also possible to re-purpose a captioning model to directly generate the entity names for a given image. In contrast, we introduce a novel Generative Entity Recognition (GER) framework, which given an input image learns to auto-regressively decode a semantic and discriminative ``code'' identifying the target entity. Our experiments demonstrate the efficacy of this GER paradigm, showcasing state-of-the-art performance on the challenging OVEN benchmark. GER surpasses strong captioning, dual-encoder, visual matching and hierarchical classification baselines, affirming its advantage in tackling the complexities of web-scale recognition.
Guided Diffusion from Self-Supervised Diffusion Features
Dec 14, 2023



Guidance serves as a key concept in diffusion models, yet its effectiveness is often limited by the need for extra data annotation or classifier pretraining. That is why guidance was harnessed from self-supervised learning backbones, like DINO. However, recent studies have revealed that the feature representation derived from diffusion model itself is discriminative for numerous downstream tasks as well, which prompts us to propose a framework to extract guidance from, and specifically for, diffusion models. Our research has yielded several significant contributions. Firstly, the guidance signals from diffusion models are on par with those from class-conditioned diffusion models. Secondly, feature regularization, when based on the Sinkhorn-Knopp algorithm, can further enhance feature discriminability in comparison to unconditional diffusion models. Thirdly, we have constructed an online training approach that can concurrently derive guidance from diffusion models for diffusion models. Lastly, we have extended the application of diffusion models along the constant velocity path of ODE to achieve a more favorable balance between sampling steps and fidelity. The performance of our methods has been outstanding, outperforming related baseline comparisons in large-resolution datasets, such as ImageNet256, ImageNet256-100 and LSUN-Churches. Our code will be released.
Weakly-Supervised Surgical Phase Recognition
Oct 26, 2023


A key element of computer-assisted surgery systems is phase recognition of surgical videos. Existing phase recognition algorithms require frame-wise annotation of a large number of videos, which is time and money consuming. In this work we join concepts of graph segmentation with self-supervised learning to derive a random-walk solution for per-frame phase prediction. Furthermore, we utilize within our method two forms of weak supervision: sparse timestamps or few-shot learning. The proposed algorithm enjoys low complexity and can operate in lowdata regimes. We validate our method by running experiments with the public Cholec80 dataset of laparoscopic cholecystectomy videos, demonstrating promising performance in multiple setups.
Self-Supervised Learning for Endoscopic Video Analysis
Aug 23, 2023Self-supervised learning (SSL) has led to important breakthroughs in computer vision by allowing learning from large amounts of unlabeled data. As such, it might have a pivotal role to play in biomedicine where annotating data requires a highly specialized expertise. Yet, there are many healthcare domains for which SSL has not been extensively explored. One such domain is endoscopy, minimally invasive procedures which are commonly used to detect and treat infections, chronic inflammatory diseases or cancer. In this work, we study the use of a leading SSL framework, namely Masked Siamese Networks (MSNs), for endoscopic video analysis such as colonoscopy and laparoscopy. To fully exploit the power of SSL, we create sizable unlabeled endoscopic video datasets for training MSNs. These strong image representations serve as a foundation for secondary training with limited annotated datasets, resulting in state-of-the-art performance in endoscopic benchmarks like surgical phase recognition during laparoscopy and colonoscopic polyp characterization. Additionally, we achieve a 50% reduction in annotated data size without sacrificing performance. Thus, our work provides evidence that SSL can dramatically reduce the need of annotated data in endoscopy.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Jul 12, 2023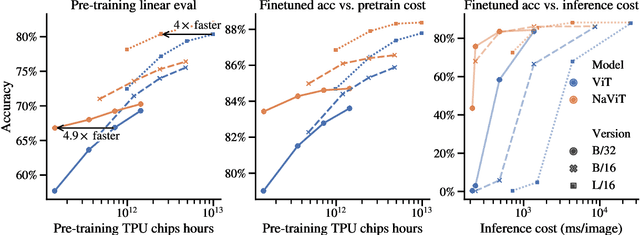
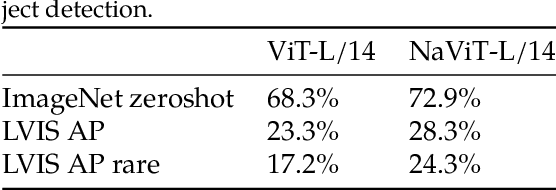
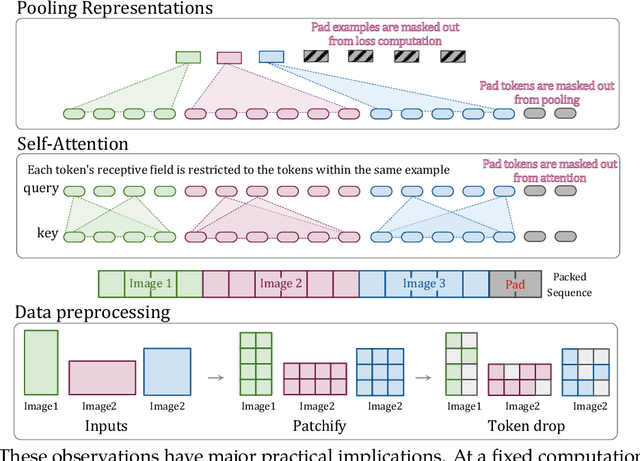
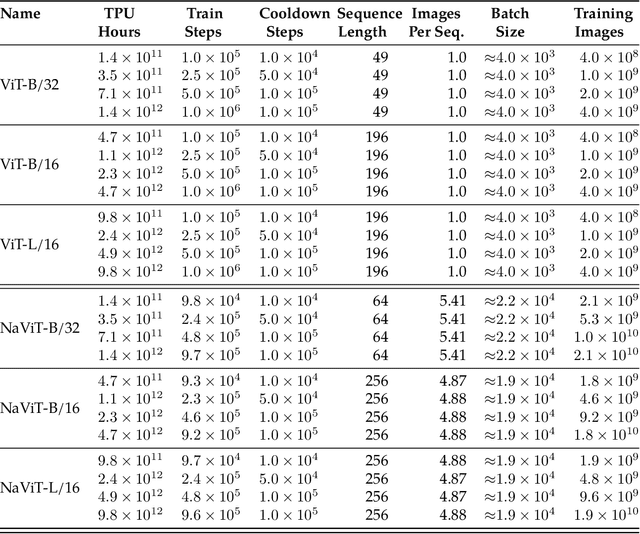
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been successfully challenged. However, models such as the Vision Transformer (ViT) offer flexible sequence-based modeling, and hence varying input sequence lengths. We take advantage of this with NaViT (Native Resolution ViT) which uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios. Alongside flexible model usage, we demonstrate improved training efficiency for large-scale supervised and contrastive image-text pretraining. NaViT can be efficiently transferred to standard tasks such as image and video classification, object detection, and semantic segmentation and leads to improved results on robustness and fairness benchmarks. At inference time, the input resolution flexibility can be used to smoothly navigate the test-time cost-performance trade-off. We believe that NaViT marks a departure from the standard, CNN-designed, input and modelling pipeline used by most computer vision models, and represents a promising direction for ViTs.
Retrieval-Enhanced Contrastive Vision-Text Models
Jun 12, 2023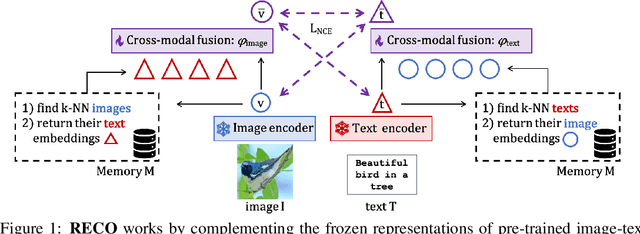
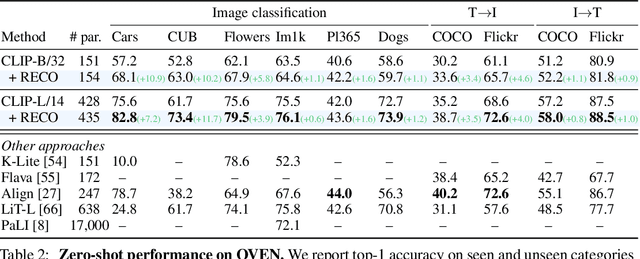
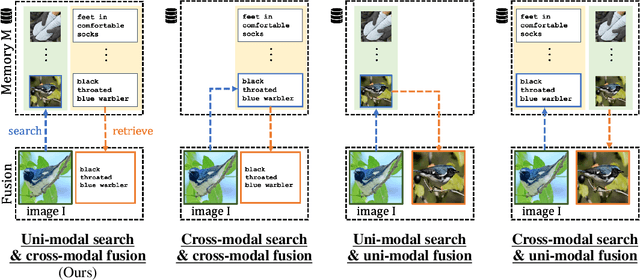
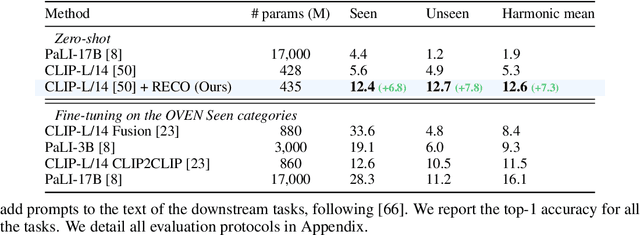
Contrastive image-text models such as CLIP form the building blocks of many state-of-the-art systems. While they excel at recognizing common generic concepts, they still struggle on fine-grained entities which are rare, or even absent from the pre-training dataset. Hence, a key ingredient to their success has been the use of large-scale curated pre-training data aiming at expanding the set of concepts that they can memorize during the pre-training stage. In this work, we explore an alternative to encoding fine-grained knowledge directly into the model's parameters: we instead train the model to retrieve this knowledge from an external memory. Specifically, we propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time, which greatly improves their zero-shot predictions. Remarkably, we show that this can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP. Our experiments validate that our retrieval-enhanced contrastive (RECO) training improves CLIP performance substantially on several challenging fine-grained tasks: for example +10.9 on Stanford Cars, +10.2 on CUB-2011 and +7.3 on the recent OVEN benchmark.
Verbs in Action: Improving verb understanding in video-language models
Apr 13, 2023



Understanding verbs is crucial to modelling how people and objects interact with each other and the environment through space and time. Recently, state-of-the-art video-language models based on CLIP have been shown to have limited verb understanding and to rely extensively on nouns, restricting their performance in real-world video applications that require action and temporal understanding. In this work, we improve verb understanding for CLIP-based video-language models by proposing a new Verb-Focused Contrastive (VFC) framework. This consists of two main components: (1) leveraging pretrained large language models (LLMs) to create hard negatives for cross-modal contrastive learning, together with a calibration strategy to balance the occurrence of concepts in positive and negative pairs; and (2) enforcing a fine-grained, verb phrase alignment loss. Our method achieves state-of-the-art results for zero-shot performance on three downstream tasks that focus on verb understanding: video-text matching, video question-answering and video classification. To the best of our knowledge, this is the first work which proposes a method to alleviate the verb understanding problem, and does not simply highlight it.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.