 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectromagnetic Modeling and Capacity Analysis of Rydberg Atom-Based MIMO System
Nov 13, 2024Rydberg atom-based antennas exploit the quantum properties of highly excited Rydberg atoms, providing unique advantages over classical antennas, such as high sensitivity, broad frequency range, and compact size. Despite the increasing interests in their applications in antenna and communication engineering, two key properties, involving the lack of polarization multiplexing and isotropic reception without mutual coupling, remain unexplored in the analysis of Rydberg atom-based spatial multiplexing, i.e., multiple-input and multiple-output (MIMO), communications. Generally, the design considerations for any antenna, even for atomic ones, can be extracted to factors such as radiation patterns, efficiency, and polarization, allowing them to be seamlessly integrated into existing system models. In this letter, we extract the antenna properties from relevant quantum characteristics, enabling electromagnetic modeling and capacity analysis of Rydberg MIMO systems in both far-field and near-field scenarios. By employing ray-based method for far-field analysis and dyadic Green's function for near-field calculation, our results indicate that Rydberg atom-based antenna arrays offer specific advantages over classical dipole-type arrays in single-polarization MIMO communications.
Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion
Oct 08, 2024



As remote sensing imaging technology continues to advance and evolve, processing high-resolution and diversified satellite imagery to improve segmentation accuracy and enhance interpretation efficiency emerg as a pivotal area of investigation within the realm of remote sensing. Although segmentation algorithms based on CNNs and Transformers achieve significant progress in performance, balancing segmentation accuracy and computational complexity remains challenging, limiting their wide application in practical tasks. To address this, this paper introduces state space model (SSM) and proposes a novel hybrid semantic segmentation network based on vision Mamba (CVMH-UNet). This method designs a cross-scanning visual state space block (CVSSBlock) that uses cross 2D scanning (CS2D) to fully capture global information from multiple directions, while by incorporating convolutional neural network branches to overcome the constraints of Vision Mamba (VMamba) in acquiring local information, this approach facilitates a comprehensive analysis of both global and local features. Furthermore, to address the issue of limited discriminative power and the difficulty in achieving detailed fusion with direct skip connections, a multi-frequency multi-scale feature fusion block (MFMSBlock) is designed. This module introduces multi-frequency information through 2D discrete cosine transform (2D DCT) to enhance information utilization and provides additional scale local detail information through point-wise convolution branches. Finally, it aggregates multi-scale information along the channel dimension, achieving refined feature fusion. Findings from experiments conducted on renowned datasets of remote sensing imagery demonstrate that proposed CVMH-UNet achieves superior segmentation performance while maintaining low computational complexity, outperforming surpassing current leading-edge segmentation algorithms.
Visible-Thermal Multiple Object Tracking: Large-scale Video Dataset and Progressive Fusion Approach
Aug 02, 2024The complementary benefits from visible and thermal infrared data are widely utilized in various computer vision task, such as visual tracking, semantic segmentation and object detection, but rarely explored in Multiple Object Tracking (MOT). In this work, we contribute a large-scale Visible-Thermal video benchmark for MOT, called VT-MOT. VT-MOT has the following main advantages. 1) The data is large scale and high diversity. VT-MOT includes 582 video sequence pairs, 401k frame pairs from surveillance, drone, and handheld platforms. 2) The cross-modal alignment is highly accurate. We invite several professionals to perform both spatial and temporal alignment frame by frame. 3) The annotation is dense and high-quality. VT-MOT has 3.99 million annotation boxes annotated and double-checked by professionals, including heavy occlusion and object re-acquisition (object disappear and reappear) challenges. To provide a strong baseline, we design a simple yet effective tracking framework, which effectively fuses temporal information and complementary information of two modalities in a progressive manner, for robust visible-thermal MOT. A comprehensive experiment are conducted on VT-MOT and the results prove the superiority and effectiveness of the proposed method compared with state-of-the-art methods. From the evaluation results and analysis, we specify several potential future directions for visible-thermal MOT. The project is released in https://github.com/wqw123wqw/PFTrack.
CRSOT: Cross-Resolution Object Tracking using Unaligned Frame and Event Cameras
Jan 05, 2024Existing datasets for RGB-DVS tracking are collected with DVS346 camera and their resolution ($346 \times 260$) is low for practical applications. Actually, only visible cameras are deployed in many practical systems, and the newly designed neuromorphic cameras may have different resolutions. The latest neuromorphic sensors can output high-definition event streams, but it is very difficult to achieve strict alignment between events and frames on both spatial and temporal views. Therefore, how to achieve accurate tracking with unaligned neuromorphic and visible sensors is a valuable but unresearched problem. In this work, we formally propose the task of object tracking using unaligned neuromorphic and visible cameras. We build the first unaligned frame-event dataset CRSOT collected with a specially built data acquisition system, which contains 1,030 high-definition RGB-Event video pairs, 304,974 video frames. In addition, we propose a novel unaligned object tracking framework that can realize robust tracking even using the loosely aligned RGB-Event data. Specifically, we extract the template and search regions of RGB and Event data and feed them into a unified ViT backbone for feature embedding. Then, we propose uncertainty perception modules to encode the RGB and Event features, respectively, then, we propose a modality uncertainty fusion module to aggregate the two modalities. These three branches are jointly optimized in the training phase. Extensive experiments demonstrate that our tracker can collaborate the dual modalities for high-performance tracking even without strictly temporal and spatial alignment. The source code, dataset, and pre-trained models will be released at https://github.com/Event-AHU/Cross_Resolution_SOT.
The Causal Impact of Credit Lines on Spending Distributions
Dec 16, 2023Consumer credit services offered by e-commerce platforms provide customers with convenient loan access during shopping and have the potential to stimulate sales. To understand the causal impact of credit lines on spending, previous studies have employed causal estimators, based on direct regression (DR), inverse propensity weighting (IPW), and double machine learning (DML) to estimate the treatment effect. However, these estimators do not consider the notion that an individual's spending can be understood and represented as a distribution, which captures the range and pattern of amounts spent across different orders. By disregarding the outcome as a distribution, valuable insights embedded within the outcome distribution might be overlooked. This paper develops a distribution-valued estimator framework that extends existing real-valued DR-, IPW-, and DML-based estimators to distribution-valued estimators within Rubin's causal framework. We establish their consistency and apply them to a real dataset from a large e-commerce platform. Our findings reveal that credit lines positively influence spending across all quantiles; however, as credit lines increase, consumers allocate more to luxuries (higher quantiles) than necessities (lower quantiles).
UTBoost: A Tree-boosting based System for Uplift Modeling
Dec 05, 2023


Uplift modeling refers to the set of machine learning techniques that a manager may use to estimate customer uplift, that is, the net effect of an action on some customer outcome. By identifying the subset of customers for whom a treatment will have the greatest effect, uplift models assist decision-makers in optimizing resource allocations and maximizing overall returns. Accurately estimating customer uplift poses practical challenges, as it requires assessing the difference between two mutually exclusive outcomes for each individual. In this paper, we propose two innovative adaptations of the well-established Gradient Boosting Decision Trees (GBDT) algorithm, which learn the causal effect in a sequential way and overcome the counter-factual nature. Both approaches innovate existing techniques in terms of ensemble learning method and learning objectives, respectively. Experiments on large-scale datasets demonstrate the usefulness of the proposed methods, which often yielding remarkable improvements over base models. To facilitate the application, we develop the UTBoost, an end-to-end tree boosting system specifically designed for uplift modeling. The package is open source and has been optimized for training speed to meet the needs of real industrial applications.
DeLELSTM: Decomposition-based Linear Explainable LSTM to Capture Instantaneous and Long-term Effects in Time Series
Aug 26, 2023



Time series forecasting is prevalent in various real-world applications. Despite the promising results of deep learning models in time series forecasting, especially the Recurrent Neural Networks (RNNs), the explanations of time series models, which are critical in high-stakes applications, have received little attention. In this paper, we propose a Decomposition-based Linear Explainable LSTM (DeLELSTM) to improve the interpretability of LSTM. Conventionally, the interpretability of RNNs only concentrates on the variable importance and time importance. We additionally distinguish between the instantaneous influence of new coming data and the long-term effects of historical data. Specifically, DeLELSTM consists of two components, i.e., standard LSTM and tensorized LSTM. The tensorized LSTM assigns each variable with a unique hidden state making up a matrix $\mathbf{h}_t$, and the standard LSTM models all the variables with a shared hidden state $\mathbf{H}_t$. By decomposing the $\mathbf{H}_t$ into the linear combination of past information $\mathbf{h}_{t-1}$ and the fresh information $\mathbf{h}_{t}-\mathbf{h}_{t-1}$, we can get the instantaneous influence and the long-term effect of each variable. In addition, the advantage of linear regression also makes the explanation transparent and clear. We demonstrate the effectiveness and interpretability of DeLELSTM on three empirical datasets. Extensive experiments show that the proposed method achieves competitive performance against the baseline methods and provides a reliable explanation relative to domain knowledge.
Deep into The Domain Shift: Transfer Learning through Dependence Regularization
May 31, 2023



Classical Domain Adaptation methods acquire transferability by regularizing the overall distributional discrepancies between features in the source domain (labeled) and features in the target domain (unlabeled). They often do not differentiate whether the domain differences come from the marginals or the dependence structures. In many business and financial applications, the labeling function usually has different sensitivities to the changes in the marginals versus changes in the dependence structures. Measuring the overall distributional differences will not be discriminative enough in acquiring transferability. Without the needed structural resolution, the learned transfer is less optimal. This paper proposes a new domain adaptation approach in which one can measure the differences in the internal dependence structure separately from those in the marginals. By optimizing the relative weights among them, the new regularization strategy greatly relaxes the rigidness of the existing approaches. It allows a learning machine to pay special attention to places where the differences matter the most. Experiments on three real-world datasets show that the improvements are quite notable and robust compared to various benchmark domain adaptation models.
RGBT Tracking via Progressive Fusion Transformer with Dynamically Guided Learning
Mar 26, 2023



Existing Transformer-based RGBT tracking methods either use cross-attention to fuse the two modalities, or use self-attention and cross-attention to model both modality-specific and modality-sharing information. However, the significant appearance gap between modalities limits the feature representation ability of certain modalities during the fusion process. To address this problem, we propose a novel Progressive Fusion Transformer called ProFormer, which progressively integrates single-modality information into the multimodal representation for robust RGBT tracking. In particular, ProFormer first uses a self-attention module to collaboratively extract the multimodal representation, and then uses two cross-attention modules to interact it with the features of the dual modalities respectively. In this way, the modality-specific information can well be activated in the multimodal representation. Finally, a feed-forward network is used to fuse two interacted multimodal representations for the further enhancement of the final multimodal representation. In addition, existing learning methods of RGBT trackers either fuse multimodal features into one for final classification, or exploit the relationship between unimodal branches and fused branch through a competitive learning strategy. However, they either ignore the learning of single-modality branches or result in one branch failing to be well optimized. To solve these problems, we propose a dynamically guided learning algorithm that adaptively uses well-performing branches to guide the learning of other branches, for enhancing the representation ability of each branch. Extensive experiments demonstrate that our proposed ProFormer sets a new state-of-the-art performance on RGBT210, RGBT234, LasHeR, and VTUAV datasets.
Moderately-Balanced Representation Learning for Treatment Effects with Orthogonality Information
Sep 05, 2022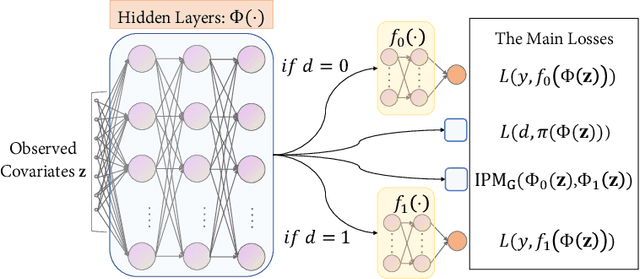
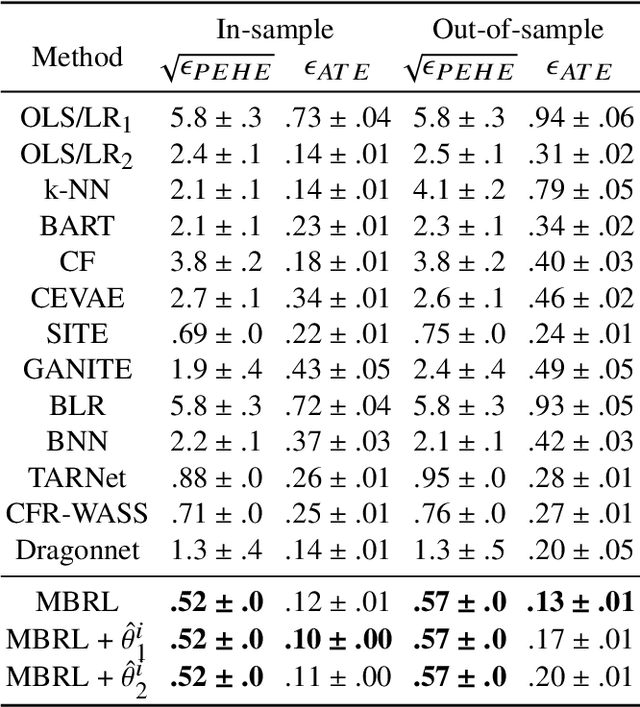
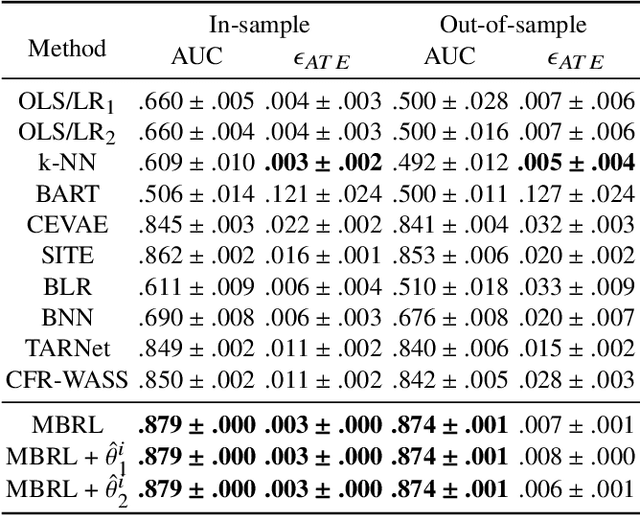
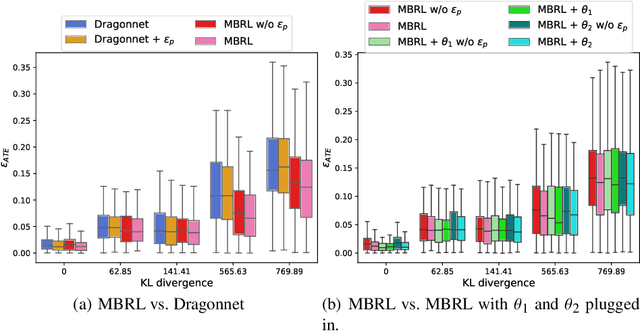
Estimating the average treatment effect (ATE) from observational data is challenging due to selection bias. Existing works mainly tackle this challenge in two ways. Some researchers propose constructing a score function that satisfies the orthogonal condition, which guarantees that the established ATE estimator is "orthogonal" to be more robust. The others explore representation learning models to achieve a balanced representation between the treated and the controlled groups. However, existing studies fail to 1) discriminate treated units from controlled ones in the representation space to avoid the over-balanced issue; 2) fully utilize the "orthogonality information". In this paper, we propose a moderately-balanced representation learning (MBRL) framework based on recent covariates balanced representation learning methods and orthogonal machine learning theory. This framework protects the representation from being over-balanced via multi-task learning. Simultaneously, MBRL incorporates the noise orthogonality information in the training and validation stages to achieve a better ATE estimation. The comprehensive experiments on benchmark and simulated datasets show the superiority and robustness of our method on treatment effect estimations compared with existing state-of-the-art methods.