 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill to Think, Foresee to Act: Cognitive-Physical Reinforcement Learning for Autonomous Driving
May 20, 2026Current end-to-end autonomous driving models are fundamentally constrained by the behavioral cloning ceiling of imitation learning. While reinforcement learning offers a path to smarter autonomy, it demands two missing pieces of infrastructure: (1) a cognitive foundation that understands traffic semantics and driving intent, and (2) a foresighted physical environment that can anticipate the consequences of candidate actions. To this end, we propose CoPhy, a CognitivePhysical reinforcement learning framework for autonomous driving. To distill to think, we distill VLM knowledge into the BEV encoder and then discard the VLM entirely, retaining cognitive ability at zero inference cost while releasing the cognitive channel as a pluggable interface for optional human language commands. To foresee to act, we build an auto-regressive BEV world model that explicitly predicts future semantic maps conditioned on candidate actions, serving as an interpretable physical sandbox from which safety metrics are directly derived. Built upon this dual infrastructure, we optimize the driving policy via GRPO with a novel dual-reward mechanism: a physical reward derived from BEV rollouts enforces hard safety constraints, while a cognitive reward from a language-aligned scorer ensures intent compliance. Extensive experiments demonstrate that CoPhy not only achieves state-of-the-art results on NAVSIM v1 and v2 benchmarks, but also enables safer driving via cognitively informed scene compliance and flexible intent control through user-defined language instructions.
COME: Adding Scene-Centric Forecasting Control to Occupancy World Model
Jun 16, 2025World models are critical for autonomous driving to simulate environmental dynamics and generate synthetic data. Existing methods struggle to disentangle ego-vehicle motion (perspective shifts) from scene evolvement (agent interactions), leading to suboptimal predictions. Instead, we propose to separate environmental changes from ego-motion by leveraging the scene-centric coordinate systems. In this paper, we introduce COME: a framework that integrates scene-centric forecasting Control into the Occupancy world ModEl. Specifically, COME first generates ego-irrelevant, spatially consistent future features through a scene-centric prediction branch, which are then converted into scene condition using a tailored ControlNet. These condition features are subsequently injected into the occupancy world model, enabling more accurate and controllable future occupancy predictions. Experimental results on the nuScenes-Occ3D dataset show that COME achieves consistent and significant improvements over state-of-the-art (SOTA) methods across diverse configurations, including different input sources (ground-truth, camera-based, fusion-based occupancy) and prediction horizons (3s and 8s). For example, under the same settings, COME achieves 26.3% better mIoU metric than DOME and 23.7% better mIoU metric than UniScene. These results highlight the efficacy of disentangled representation learning in enhancing spatio-temporal prediction fidelity for world models. Code and videos will be available at https://github.com/synsin0/COME.
DiffRoad: Realistic and Diverse Road Scenario Generation for Autonomous Vehicle Testing
Nov 14, 2024



Generating realistic and diverse road scenarios is essential for autonomous vehicle testing and validation. Nevertheless, owing to the complexity and variability of real-world road environments, creating authentic and varied scenarios for intelligent driving testing is challenging. In this paper, we propose DiffRoad, a novel diffusion model designed to produce controllable and high-fidelity 3D road scenarios. DiffRoad leverages the generative capabilities of diffusion models to synthesize road layouts from white noise through an inverse denoising process, preserving real-world spatial features. To enhance the quality of generated scenarios, we design the Road-UNet architecture, optimizing the balance between backbone and skip connections for high-realism scenario generation. Furthermore, we introduce a road scenario evaluation module that screens adequate and reasonable scenarios for intelligent driving testing using two critical metrics: road continuity and road reasonableness. Experimental results on multiple real-world datasets demonstrate DiffRoad's ability to generate realistic and smooth road structures while maintaining the original distribution. Additionally, the generated scenarios can be fully automated into the OpenDRIVE format, facilitating generalized autonomous vehicle simulation testing. DiffRoad provides a rich and diverse scenario library for large-scale autonomous vehicle testing and offers valuable insights for future infrastructure designs that are better suited for autonomous vehicles.
OPUS: Occupancy Prediction Using a Sparse Set
Sep 14, 2024



Occupancy prediction, aiming at predicting the occupancy status within voxelized 3D environment, is quickly gaining momentum within the autonomous driving community. Mainstream occupancy prediction works first discretize the 3D environment into voxels, then perform classification on such dense grids. However, inspection on sample data reveals that the vast majority of voxels is unoccupied. Performing classification on these empty voxels demands suboptimal computation resource allocation, and reducing such empty voxels necessitates complex algorithm designs. To this end, we present a novel perspective on the occupancy prediction task: formulating it as a streamlined set prediction paradigm without the need for explicit space modeling or complex sparsification procedures. Our proposed framework, called OPUS, utilizes a transformer encoder-decoder architecture to simultaneously predict occupied locations and classes using a set of learnable queries. Firstly, we employ the Chamfer distance loss to scale the set-to-set comparison problem to unprecedented magnitudes, making training such model end-to-end a reality. Subsequently, semantic classes are adaptively assigned using nearest neighbor search based on the learned locations. In addition, OPUS incorporates a suite of non-trivial strategies to enhance model performance, including coarse-to-fine learning, consistent point sampling, and adaptive re-weighting, etc. Finally, compared with current state-of-the-art methods, our lightest model achieves superior RayIoU on the Occ3D-nuScenes dataset at near 2x FPS, while our heaviest model surpasses previous best results by 6.1 RayIoU.
Towards Stable 3D Object Detection
Jul 05, 2024



In autonomous driving, the temporal stability of 3D object detection greatly impacts the driving safety. However, the detection stability cannot be accessed by existing metrics such as mAP and MOTA, and consequently is less explored by the community. To bridge this gap, this work proposes Stability Index (SI), a new metric that can comprehensively evaluate the stability of 3D detectors in terms of confidence, box localization, extent, and heading. By benchmarking state-of-the-art object detectors on the Waymo Open Dataset, SI reveals interesting properties of object stability that have not been previously discovered by other metrics. To help models improve their stability, we further introduce a general and effective training strategy, called Prediction Consistency Learning (PCL). PCL essentially encourages the prediction consistency of the same objects under different timestamps and augmentations, leading to enhanced detection stability. Furthermore, we examine the effectiveness of PCL with the widely-used CenterPoint, and achieve a remarkable SI of 86.00 for vehicle class, surpassing the baseline by 5.48. We hope our work could serve as a reliable baseline and draw the community's attention to this crucial issue in 3D object detection. Codes will be made publicly available.
Exploring Key Factors for Long-Term Vessel Incident Risk Prediction
May 30, 2024



Factor analysis acts a pivotal role in enhancing maritime safety. Most previous studies conduct factor analysis within the framework of incident-related label prediction, where the developed models can be categorized into short-term and long-term prediction models. The long-term models offer a more strategic approach, enabling more proactive risk management, compared to the short-term ones. Nevertheless, few studies have devoted to rigorously identifying the key factors for the long-term prediction and undertaking comprehensive factor analysis. Hence, this study aims to delve into the key factors for predicting the incident risk levels in the subsequent year given a specific datestamp. The majority of candidate factors potentially contributing to the incident risk are collected from vessels' historical safety performance data spanning up to five years. An improved embedded feature selection, which integrates Random Forest classifier with a feature filtering process is proposed to identify key risk-contributing factors from the candidate pool. The results demonstrate superior performance of the proposed method in incident prediction and factor interpretability. Comprehensive analysis is conducted upon the key factors, which could help maritime stakeholders formulate management strategies for incident prevenion.
Small, Versatile and Mighty: A Range-View Perception Framework
Mar 01, 2024



Despite its compactness and information integrity, the range view representation of LiDAR data rarely occurs as the first choice for 3D perception tasks. In this work, we further push the envelop of the range-view representation with a novel multi-task framework, achieving unprecedented 3D detection performances. Our proposed Small, Versatile, and Mighty (SVM) network utilizes a pure convolutional architecture to fully unleash the efficiency and multi-tasking potentials of the range view representation. To boost detection performances, we first propose a range-view specific Perspective Centric Label Assignment (PCLA) strategy, and a novel View Adaptive Regression (VAR) module to further refine hard-to-predict box properties. In addition, our framework seamlessly integrates semantic segmentation and panoptic segmentation tasks for the LiDAR point cloud, without extra modules. Among range-view-based methods, our model achieves new state-of-the-art detection performances on the Waymo Open Dataset. Especially, over 10 mAP improvement over convolutional counterparts can be obtained on the vehicle class. Our presented results for other tasks further reveal the multi-task capabilities of the proposed small but mighty framework.
Curricular Object Manipulation in LiDAR-based Object Detection
Apr 09, 2023



This paper explores the potential of curriculum learning in LiDAR-based 3D object detection by proposing a curricular object manipulation (COM) framework. The framework embeds the curricular training strategy into both the loss design and the augmentation process. For the loss design, we propose the COMLoss to dynamically predict object-level difficulties and emphasize objects of different difficulties based on training stages. On top of the widely-used augmentation technique called GT-Aug in LiDAR detection tasks, we propose a novel COMAug strategy which first clusters objects in ground-truth database based on well-designed heuristics. Group-level difficulties rather than individual ones are then predicted and updated during training for stable results. Model performance and generalization capabilities can be improved by sampling and augmenting progressively more difficult objects into the training samples. Extensive experiments and ablation studies reveal the superior and generality of the proposed framework. The code is available at https://github.com/ZZY816/COM.
Towards Privacy-Preserving, Real-Time and Lossless Feature Matching
Jul 30, 2022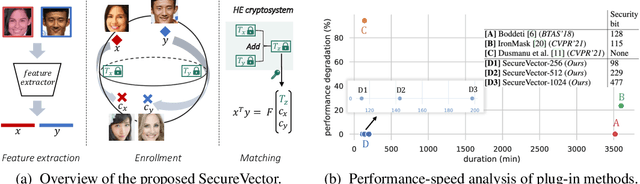
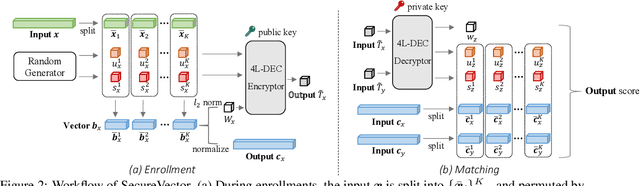

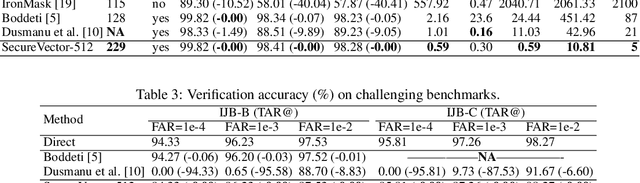
Most visual retrieval applications store feature vectors for downstream matching tasks. These vectors, from where user information can be spied out, will cause privacy leakage if not carefully protected. To mitigate privacy risks, current works primarily utilize non-invertible transformations or fully cryptographic algorithms. However, transformation-based methods usually fail to achieve satisfying matching performances while cryptosystems suffer from heavy computational overheads. In addition, secure levels of current methods should be improved to confront potential adversary attacks. To address these issues, this paper proposes a plug-in module called SecureVector that protects features by random permutations, 4L-DEC converting and existing homomorphic encryption techniques. For the first time, SecureVector achieves real-time and lossless feature matching among sanitized features, along with much higher security levels than current state-of-the-arts. Extensive experiments on face recognition, person re-identification, image retrieval, and privacy analyses demonstrate the effectiveness of our method. Given limited public projects in this field, codes of our method and implemented baselines are made open-source in https://github.com/IrvingMeng/SecureVector.
Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters
Jan 29, 2022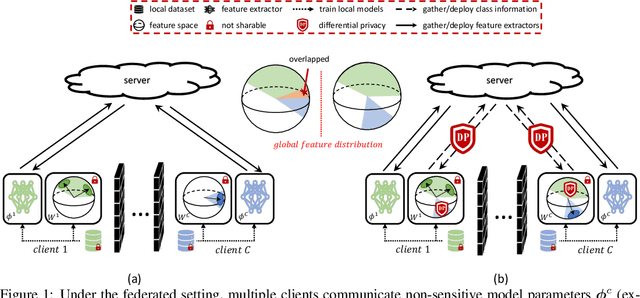
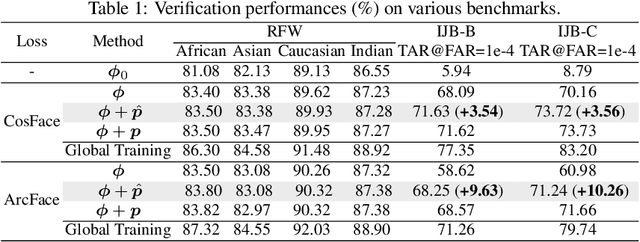
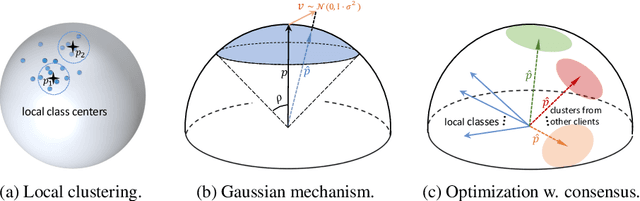
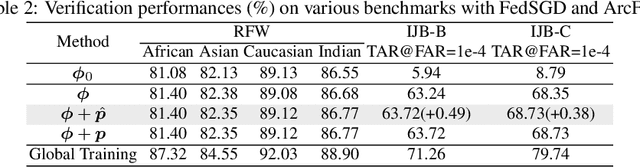
The growing public concerns on data privacy in face recognition can be greatly addressed by the federated learning (FL) paradigm. However, conventional FL methods perform poorly due to the uniqueness of the task: broadcasting class centers among clients is crucial for recognition performances but leads to privacy leakage. To resolve the privacy-utility paradox, this work proposes PrivacyFace, a framework largely improves the federated learning face recognition via communicating auxiliary and privacy-agnostic information among clients. PrivacyFace mainly consists of two components: First, a practical Differentially Private Local Clustering (DPLC) mechanism is proposed to distill sanitized clusters from local class centers. Second, a consensus-aware recognition loss subsequently encourages global consensuses among clients, which ergo results in more discriminative features. The proposed framework is mathematically proved to be differentially private, introducing a lightweight overhead as well as yielding prominent performance boosts (\textit{e.g.}, +9.63\% and +10.26\% for TAR@FAR=1e-4 on IJB-B and IJB-C respectively). Extensive experiments and ablation studies on a large-scale dataset have demonstrated the efficacy and practicability of our method.