 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE Routing Testbed: Studying Expert Specialization and Routing Behavior at Small Scale
Apr 08, 2026Sparse Mixture-of-Experts (MoE) architectures are increasingly popular for frontier large language models (LLM) but they introduce training challenges due to routing complexity. Fully leveraging parameters of an MoE model requires all experts to be well-trained and to specialize in non-redundant ways. Assessing this, however, is complicated due to lack of established metrics and, importantly, many routing techniques exhibit similar performance at smaller sizes, which is often not reflective of their behavior at large scale. To address this challenge, we propose the MoE Routing Testbed, a setup that gives clearer visibility into routing dynamics at small scale while using realistic data. The testbed pairs a data mix with clearly distinguishable domains with a reference router that prescribes ideal routing based on these domains, providing a well-defined upper bound for comparison. This enables quantifiable measurement of expert specialization. To demonstrate the value of the testbed, we compare various MoE routing approaches and show that balancing scope is the crucial factor that allows specialization while maintaining high expert utilization. We confirm that this observation generalizes to models 35x larger.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Invariant Slot Attention: Object Discovery with Slot-Centric Reference Frames
Feb 09, 2023



Automatically discovering composable abstractions from raw perceptual data is a long-standing challenge in machine learning. Recent slot-based neural networks that learn about objects in a self-supervised manner have made exciting progress in this direction. However, they typically fall short at adequately capturing spatial symmetries present in the visual world, which leads to sample inefficiency, such as when entangling object appearance and pose. In this paper, we present a simple yet highly effective method for incorporating spatial symmetries via slot-centric reference frames. We incorporate equivariance to per-object pose transformations into the attention and generation mechanism of Slot Attention by translating, scaling, and rotating position encodings. These changes result in little computational overhead, are easy to implement, and can result in large gains in terms of data efficiency and overall improvements to object discovery. We evaluate our method on a wide range of synthetic object discovery benchmarks namely CLEVR, Tetrominoes, CLEVRTex, Objects Room and MultiShapeNet, and show promising improvements on the challenging real-world Waymo Open dataset.
SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos
Jun 15, 2022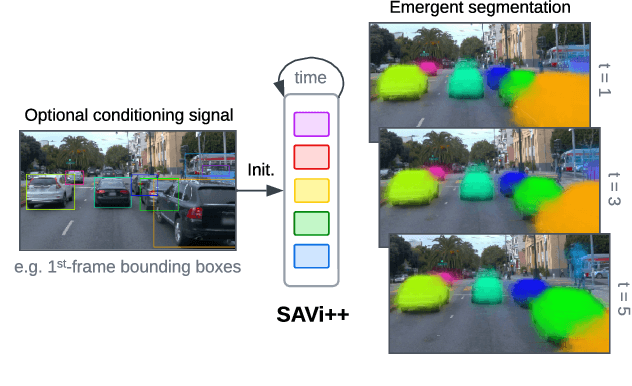
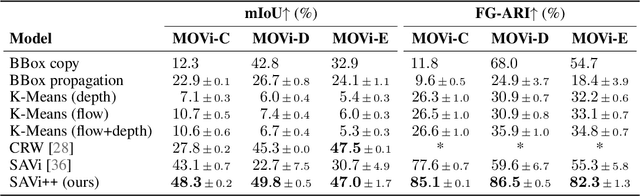
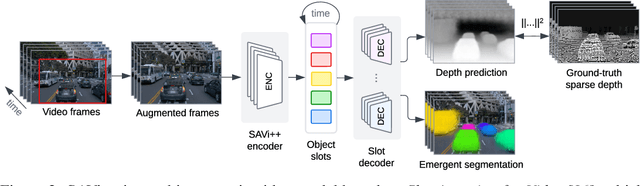

The visual world can be parsimoniously characterized in terms of distinct entities with sparse interactions. Discovering this compositional structure in dynamic visual scenes has proven challenging for end-to-end computer vision approaches unless explicit instance-level supervision is provided. Slot-based models leveraging motion cues have recently shown great promise in learning to represent, segment, and track objects without direct supervision, but they still fail to scale to complex real-world multi-object videos. In an effort to bridge this gap, we take inspiration from human development and hypothesize that information about scene geometry in the form of depth signals can facilitate object-centric learning. We introduce SAVi++, an object-centric video model which is trained to predict depth signals from a slot-based video representation. By further leveraging best practices for model scaling, we are able to train SAVi++ to segment complex dynamic scenes recorded with moving cameras, containing both static and moving objects of diverse appearance on naturalistic backgrounds, without the need for segmentation supervision. Finally, we demonstrate that by using sparse depth signals obtained from LiDAR, SAVi++ is able to learn emergent object segmentation and tracking from videos in the real-world Waymo Open dataset.
Conditional Object-Centric Learning from Video
Nov 24, 2021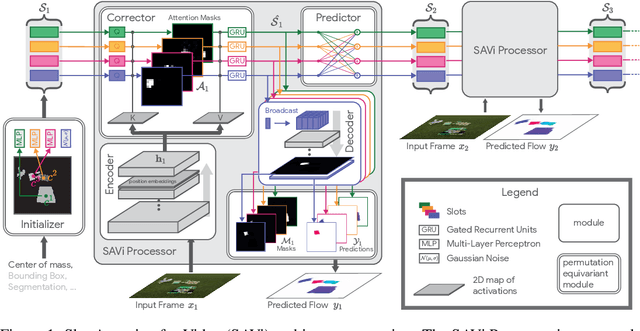

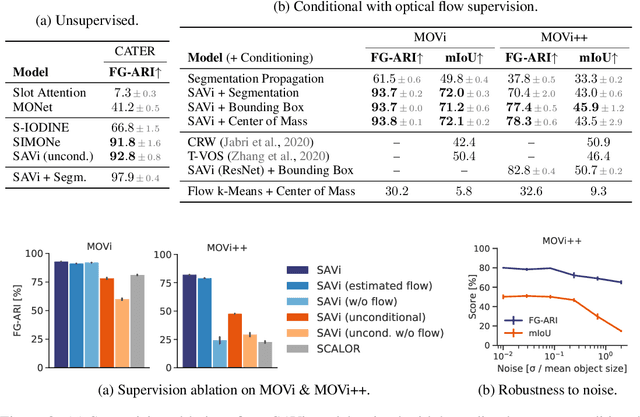

Object-centric representations are a promising path toward more systematic generalization by providing flexible abstractions upon which compositional world models can be built. Recent work on simple 2D and 3D datasets has shown that models with object-centric inductive biases can learn to segment and represent meaningful objects from the statistical structure of the data alone without the need for any supervision. However, such fully-unsupervised methods still fail to scale to diverse realistic data, despite the use of increasingly complex inductive biases such as priors for the size of objects or the 3D geometry of the scene. In this paper, we instead take a weakly-supervised approach and focus on how 1) using the temporal dynamics of video data in the form of optical flow and 2) conditioning the model on simple object location cues can be used to enable segmenting and tracking objects in significantly more realistic synthetic data. We introduce a sequential extension to Slot Attention which we train to predict optical flow for realistic looking synthetic scenes and show that conditioning the initial state of this model on a small set of hints, such as center of mass of objects in the first frame, is sufficient to significantly improve instance segmentation. These benefits generalize beyond the training distribution to novel objects, novel backgrounds, and to longer video sequences. We also find that such initial-state-conditioning can be used during inference as a flexible interface to query the model for specific objects or parts of objects, which could pave the way for a range of weakly-supervised approaches and allow more effective interaction with trained models.
Addressing the Real-world Class Imbalance Problem in Dermatology
Oct 09, 2020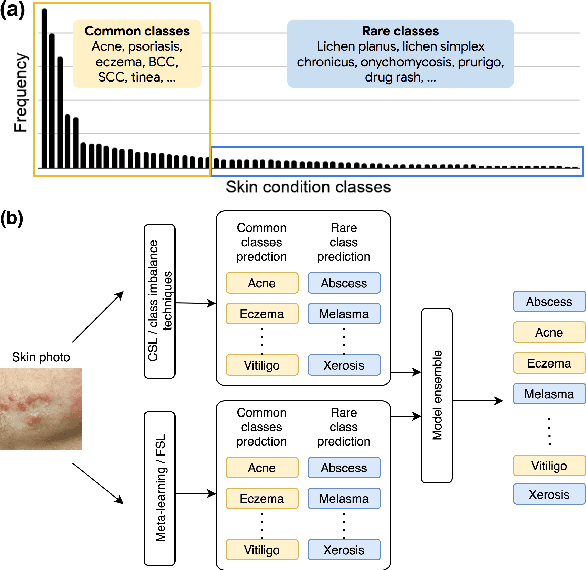
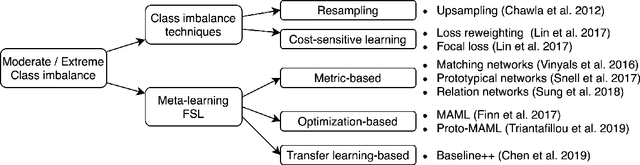
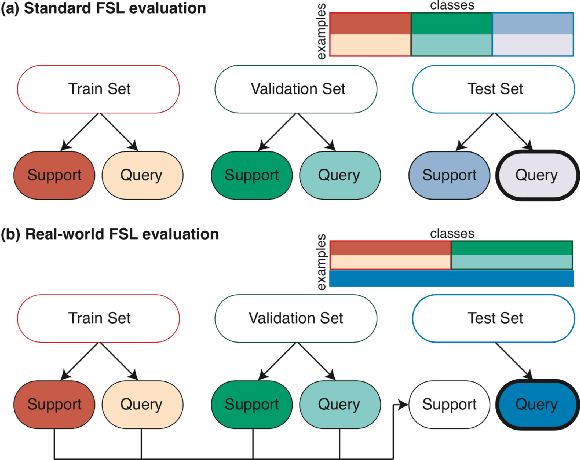
Class imbalance is a common problem in medical diagnosis, causing a standard classifier to be biased towards the common classes and perform poorly on the rare classes. This is especially true for dermatology, a specialty with thousands of skin conditions but many of which have rare prevalence in the real world. Motivated by recent advances, we explore few-shot learning methods as well as conventional class imbalance techniques for the skin condition recognition problem and propose an evaluation setup to fairly assess the real-world utility of such approaches. When compared to conventional class imbalance techniques, we find that few-shot learning methods are not as performant as those conventional methods, but combining the two approaches using a novel ensemble leads to improvement in model performance, especially for rare classes. We conclude that the ensemble can be useful to address the class imbalance problem, yet progress here can further be accelerated by the use of real-world evaluation setups for benchmarking new methods.
Revisiting Spatial Invariance with Low-Rank Local Connectivity
Feb 07, 2020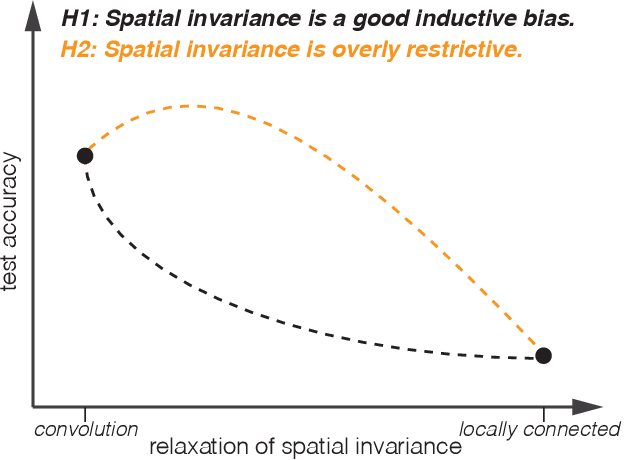
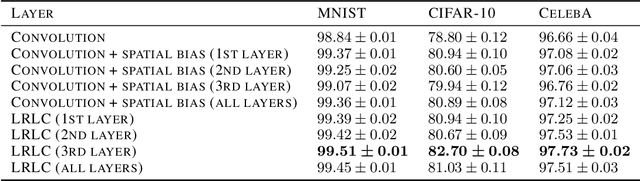

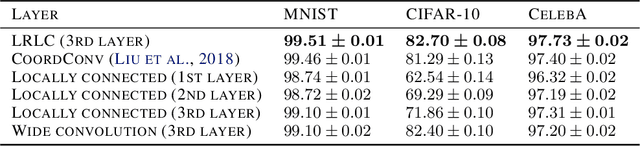
Convolutional neural networks are among the most successful architectures in deep learning. This success is at least partially attributable to the efficacy of spatial invariance as an inductive bias. Locally connected layers, which differ from convolutional layers in their lack of spatial invariance, usually perform poorly in practice. However, these observations still leave open the possibility that some degree of relaxation of spatial invariance may yield a better inductive bias than either convolution or local connectivity. To test this hypothesis, we design a method to relax the spatial invariance of a network layer in a controlled manner. In particular, we create a \textit{low-rank} locally connected layer, where the filter bank applied at each position is constructed as a linear combination of basis set of filter banks. By varying the number of filter banks in the basis set, we can control the degree of departure from spatial invariance. In our experiments, we find that relaxing spatial invariance improves classification accuracy over both convolution and locally connected layers across MNIST, CIFAR-10, and CelebA datasets. These results suggest that spatial invariance in convolution layers may be overly restrictive.
Saccader: Improving Accuracy of Hard Attention Models for Vision
Sep 11, 2019
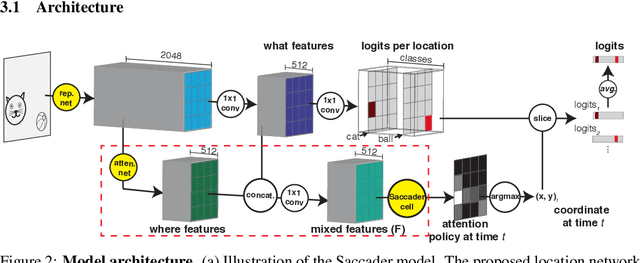
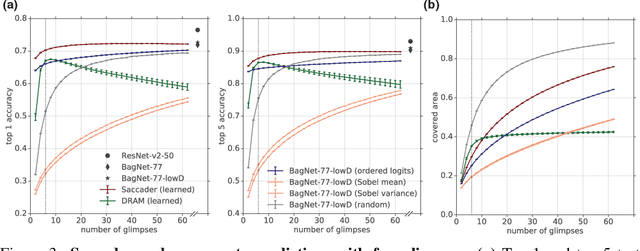

Although deep convolutional neural networks achieve state-of-the-art performance across nearly all image classification tasks, their decisions are difficult to interpret. One approach that offers some level of interpretability by design is \textit{hard attention}, which uses only relevant portions of the image. However, training hard attention models with only class label supervision is challenging, and hard attention has proved difficult to scale to complex datasets. Here, we propose a novel hard attention model, which we term Saccader. Key to Saccader is a pretraining step that requires only class labels and provides initial attention locations for policy gradient optimization. Our best models narrow the gap to common ImageNet baselines, achieving $75\%$ top-1 and $91\%$ top-5 while attending to less than one-third of the image.
Adversarial Reprogramming of Neural Networks
Jun 28, 2018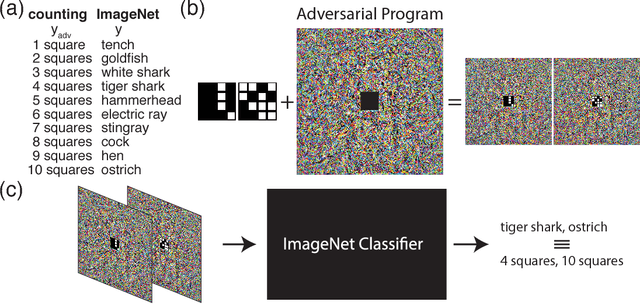
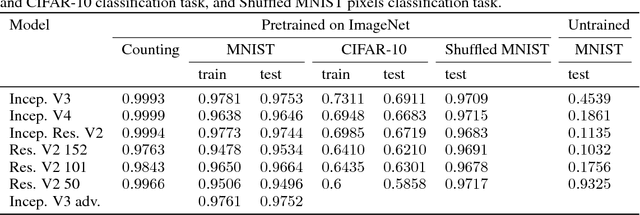


Deep neural networks are susceptible to adversarial attacks. In computer vision, well-crafted perturbations to images can cause neural networks to make mistakes such as identifying a panda as a gibbon or confusing a cat with a computer. Previous adversarial examples have been designed to degrade performance of models or cause machine learning models to produce specific outputs chosen ahead of time by the attacker. We introduce adversarial attacks that instead reprogram the target model to perform a task chosen by the attacker---without the attacker needing to specify or compute the desired output for each test-time input. This attack is accomplished by optimizing for a single adversarial perturbation, of unrestricted magnitude, that can be added to all test-time inputs to a machine learning model in order to cause the model to perform a task chosen by the adversary when processing these inputs---even if the model was not trained to do this task. These perturbations can be thus considered a program for the new task. We demonstrate adversarial reprogramming on six ImageNet classification models, repurposing these models to perform a counting task, as well as two classification tasks: classification of MNIST and CIFAR-10 examples presented within the input to the ImageNet model.
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
May 22, 2018
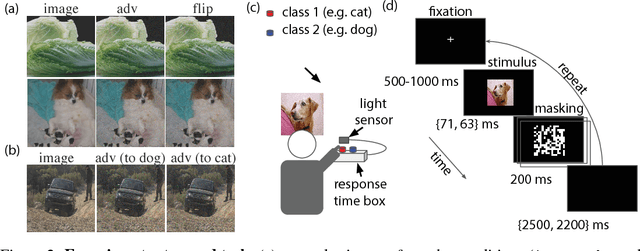
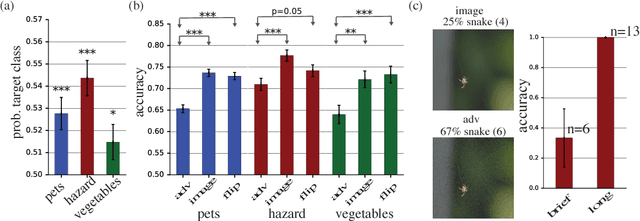
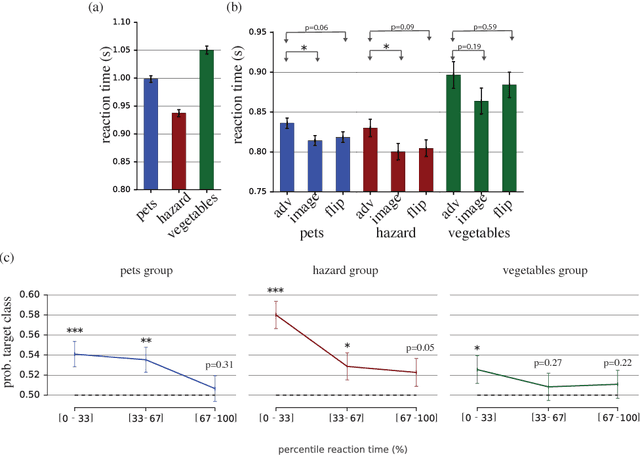
Machine learning models are vulnerable to adversarial examples: small changes to images can cause computer vision models to make mistakes such as identifying a school bus as an ostrich. However, it is still an open question whether humans are prone to similar mistakes. Here, we address this question by leveraging recent techniques that transfer adversarial examples from computer vision models with known parameters and architecture to other models with unknown parameters and architecture, and by matching the initial processing of the human visual system. We find that adversarial examples that strongly transfer across computer vision models influence the classifications made by time-limited human observers.