 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocFusion: A Unified Framework for Document Parsing Tasks
Dec 17, 2024



Document parsing is essential for analyzing complex document structures and extracting fine-grained information, supporting numerous downstream applications. However, existing methods often require integrating multiple independent models to handle various parsing tasks, leading to high complexity and maintenance overhead. To address this, we propose DocFusion, a lightweight generative model with only 0.28B parameters. It unifies task representations and achieves collaborative training through an improved objective function. Experiments reveal and leverage the mutually beneficial interaction among recognition tasks, and integrating recognition data significantly enhances detection performance. The final results demonstrate that DocFusion achieves state-of-the-art (SOTA) performance across four key tasks.
Blockchain Data Analysis in the Era of Large-Language Models
Dec 09, 2024



Blockchain data analysis is essential for deriving insights, tracking transactions, identifying patterns, and ensuring the integrity and security of decentralized networks. It plays a key role in various areas, such as fraud detection, regulatory compliance, smart contract auditing, and decentralized finance (DeFi) risk management. However, existing blockchain data analysis tools face challenges, including data scarcity, the lack of generalizability, and the lack of reasoning capability. We believe large language models (LLMs) can mitigate these challenges; however, we have not seen papers discussing LLM integration in blockchain data analysis in a comprehensive and systematic way. This paper systematically explores potential techniques and design patterns in LLM-integrated blockchain data analysis. We also outline prospective research opportunities and challenges, emphasizing the need for further exploration in this promising field. This paper aims to benefit a diverse audience spanning academia, industry, and policy-making, offering valuable insights into the integration of LLMs in blockchain data analysis.
Object Detection using Event Camera: A MoE Heat Conduction based Detector and A New Benchmark Dataset
Dec 09, 2024



Object detection in event streams has emerged as a cutting-edge research area, demonstrating superior performance in low-light conditions, scenarios with motion blur, and rapid movements. Current detectors leverage spiking neural networks, Transformers, or convolutional neural networks as their core architectures, each with its own set of limitations including restricted performance, high computational overhead, or limited local receptive fields. This paper introduces a novel MoE (Mixture of Experts) heat conduction-based object detection algorithm that strikingly balances accuracy and computational efficiency. Initially, we employ a stem network for event data embedding, followed by processing through our innovative MoE-HCO blocks. Each block integrates various expert modules to mimic heat conduction within event streams. Subsequently, an IoU-based query selection module is utilized for efficient token extraction, which is then channeled into a detection head for the final object detection process. Furthermore, we are pleased to introduce EvDET200K, a novel benchmark dataset for event-based object detection. Captured with a high-definition Prophesee EVK4-HD event camera, this dataset encompasses 10 distinct categories, 200,000 bounding boxes, and 10,054 samples, each spanning 2 to 5 seconds. We also provide comprehensive results from over 15 state-of-the-art detectors, offering a solid foundation for future research and comparison. The source code of this paper will be released on: https://github.com/Event-AHU/OpenEvDET
PaliGemma 2: A Family of Versatile VLMs for Transfer
Dec 04, 2024



PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model. We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning. The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution. We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024



Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
Nimbus: Secure and Efficient Two-Party Inference for Transformers
Nov 24, 2024



Transformer models have gained significant attention due to their power in machine learning tasks. Their extensive deployment has raised concerns about the potential leakage of sensitive information during inference. However, when being applied to Transformers, existing approaches based on secure two-party computation (2PC) bring about efficiency limitations in two folds: (1) resource-intensive matrix multiplications in linear layers, and (2) complex non-linear activation functions like $\mathsf{GELU}$ and $\mathsf{Softmax}$. This work presents a new two-party inference framework $\mathsf{Nimbus}$ for Transformer models. For the linear layer, we propose a new 2PC paradigm along with an encoding approach to securely compute matrix multiplications based on an outer-product insight, which achieves $2.9\times \sim 12.5\times$ performance improvements compared to the state-of-the-art (SOTA) protocol. For the non-linear layer, through a new observation of utilizing the input distribution, we propose an approach of low-degree polynomial approximation for $\mathsf{GELU}$ and $\mathsf{Softmax}$, which improves the performance of the SOTA polynomial approximation by $2.9\times \sim 4.0\times$, where the average accuracy loss of our approach is 0.08\% compared to the non-2PC inference without privacy. Compared with the SOTA two-party inference, $\mathsf{Nimbus}$ improves the end-to-end performance of \bert{} inference by $2.7\times \sim 4.7\times$ across different network settings.
FM-TS: Flow Matching for Time Series Generation
Nov 12, 2024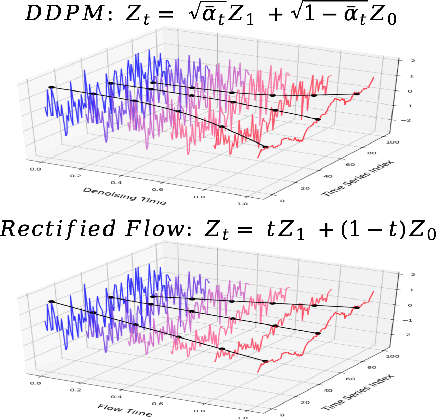
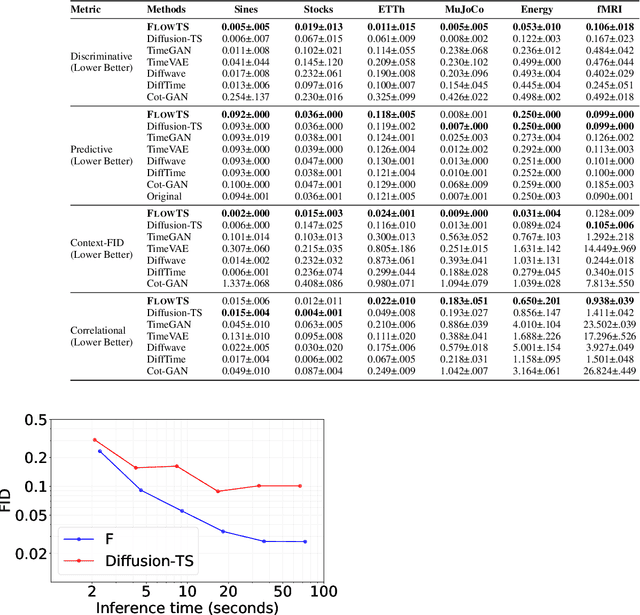
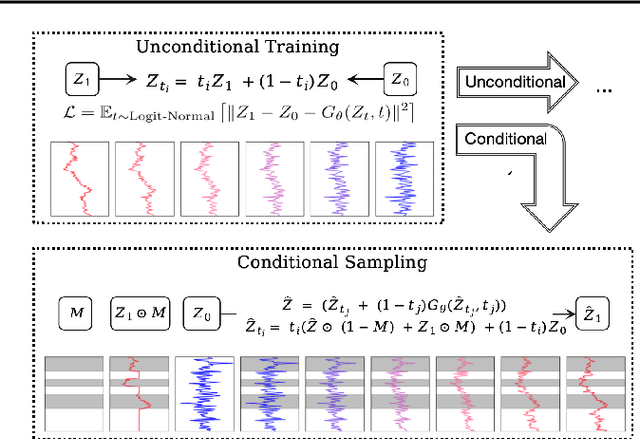
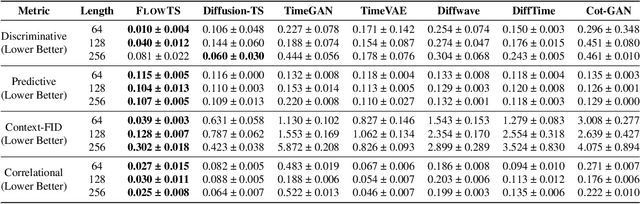
Time series generation has emerged as an essential tool for analyzing temporal data across numerous fields. While diffusion models have recently gained significant attention in generating high-quality time series, they tend to be computationally demanding and reliant on complex stochastic processes. To address these limitations, we introduce FM-TS, a rectified Flow Matching-based framework for Time Series generation, which simplifies the time series generation process by directly optimizing continuous trajectories. This approach avoids the need for iterative sampling or complex noise schedules typically required in diffusion-based models. FM-TS is more efficient in terms of training and inference. Moreover, FM-TS is highly adaptive, supporting both conditional and unconditional time series generation. Notably, through our novel inference design, the model trained in an unconditional setting can seamlessly generalize to conditional tasks without the need for retraining. Extensive benchmarking across both settings demonstrates that FM-TS consistently delivers superior performance compared to existing approaches while being more efficient in terms of training and inference. For instance, in terms of discriminative score, FM-TS achieves 0.005, 0.019, 0.011, 0.005, 0.053, and 0.106 on the Sines, Stocks, ETTh, MuJoCo, Energy, and fMRI unconditional time series datasets, respectively, significantly outperforming the second-best method which achieves 0.006, 0.067, 0.061, 0.008, 0.122, and 0.167 on the same datasets. We have achieved superior performance in solar forecasting and MuJoCo imputation tasks, significantly enhanced by our innovative $t$ power sampling method. The code is available at https://github.com/UNITES-Lab/FMTS.
A Data-driven Crowd Simulation Framework Integrating Physics-informed Machine Learning with Navigation Potential Fields
Oct 21, 2024



Traditional rule-based physical models are limited by their reliance on singular physical formulas and parameters, making it difficult to effectively tackle the intricate tasks associated with crowd simulation. Recent research has introduced deep learning methods to tackle these issues, but most current approaches focus primarily on generating pedestrian trajectories, often lacking interpretability and failing to provide real-time dynamic simulations.To address the aforementioned issues, we propose a novel data-driven crowd simulation framework that integrates Physics-informed Machine Learning (PIML) with navigation potential fields. Our approach leverages the strengths of both physical models and PIML. Specifically, we design an innovative Physics-informed Spatio-temporal Graph Convolutional Network (PI-STGCN) as a data-driven module to predict pedestrian movement trends based on crowd spatio-temporal data. Additionally, we construct a physical model of navigation potential fields based on flow field theory to guide pedestrian movements, thereby reinforcing physical constraints during the simulation. In our framework, navigation potential fields are dynamically computed and updated based on the movement trends predicted by the PI-STGCN, while the updated crowd dynamics, guided by these fields, subsequently feed back into the PI-STGCN. Comparative experiments on two publicly available large-scale real-world datasets across five scenes demonstrate that our proposed framework outperforms existing rule-based methods in accuracy and fidelity. The similarity between simulated and actual pedestrian trajectories increases by 10.8%, while the average error is reduced by 4%. Moreover, our framework exhibits greater adaptability and better interpretability compared to methods that rely solely on deep learning for trajectory generation.
Anderson Acceleration in Nonsmooth Problems: Local Convergence via Active Manifold Identification
Oct 15, 2024



Anderson acceleration is an effective technique for enhancing the efficiency of fixed-point iterations; however, analyzing its convergence in nonsmooth settings presents significant challenges. In this paper, we investigate a class of nonsmooth optimization algorithms characterized by the active manifold identification property. This class includes a diverse array of methods such as the proximal point method, proximal gradient method, proximal linear method, proximal coordinate descent method, Douglas-Rachford splitting (or the alternating direction method of multipliers), and the iteratively reweighted $\ell_1$ method, among others. Under the assumption that the optimization problem possesses an active manifold at a stationary point, we establish a local R-linear convergence rate for the Anderson-accelerated algorithm. Our extensive numerical experiments further highlight the robust performance of the proposed Anderson-accelerated methods.
Multi-modal Fusion based Q-distribution Prediction for Controlled Nuclear Fusion
Oct 11, 2024



Q-distribution prediction is a crucial research direction in controlled nuclear fusion, with deep learning emerging as a key approach to solving prediction challenges. In this paper, we leverage deep learning techniques to tackle the complexities of Q-distribution prediction. Specifically, we explore multimodal fusion methods in computer vision, integrating 2D line image data with the original 1D data to form a bimodal input. Additionally, we employ the Transformer's attention mechanism for feature extraction and the interactive fusion of bimodal information. Extensive experiments validate the effectiveness of our approach, significantly reducing prediction errors in Q-distribution.