 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2DEPT: Large Language Model-Driven Automated Algorithm Design via Evolutionary Program Trees
Apr 27, 2026Designing heuristics for combinatorial optimization problems (COPs) is a fundamental yet challenging task that traditionally requires extensive domain expertise. Recently, Large Language Model (LLM)-based Automated Heuristic Design (AHD) has shown promise in autonomously generating heuristic components with minimal human intervention. However, most existing LLM-based AHD methods enforce fixed algorithmic templates to ensure executability, which confines the search to component-level tuning and limits system-level algorithmic expressiveness. To enable open-ended solver synthesis beyond rigid templates, we propose Automated Algorithm Design via Evolutionary Program Trees (A2DEPT), which treats LLMs as system-level algorithm architects. A2DEPT explores the vast program space via a tree-structured evolutionary search with hybrid selection and hierarchical operators, enabling iterative refinement of complete algorithms. To make open-ended generation practical, we enforce executability with a lightweight program-maintenance loop that performs feedback-driven repair. In experiments, A2DEPT consistently outperforms representative LLM-based baselines on both standard and highly constrained benchmarks. On the standard benchmarks, it reduces the mean normalized optimality gap by 9.8% relative to the strongest competing AHD baseline.
DevPiolt: Operation Recommendation for IoT Devices at Xiaomi Home
Nov 18, 2025



Operation recommendation for IoT devices refers to generating personalized device operations for users based on their context, such as historical operations, environment information, and device status. This task is crucial for enhancing user satisfaction and corporate profits. Existing recommendation models struggle with complex operation logic, diverse user preferences, and sensitive to suboptimal suggestions, limiting their applicability to IoT device operations. To address these issues, we propose DevPiolt, a LLM-based recommendation model for IoT device operations. Specifically, we first equip the LLM with fundamental domain knowledge of IoT operations via continual pre-training and multi-task fine-tuning. Then, we employ direct preference optimization to align the fine-tuned LLM with specific user preferences. Finally, we design a confidence-based exposure control mechanism to avoid negative user experiences from low-quality recommendations. Extensive experiments show that DevPiolt significantly outperforms baselines on all datasets, with an average improvement of 69.5% across all metrics. DevPiolt has been practically deployed in Xiaomi Home app for one quarter, providing daily operation recommendations to 255,000 users. Online experiment results indicate a 21.6% increase in unique visitor device coverage and a 29.1% increase in page view acceptance rates.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025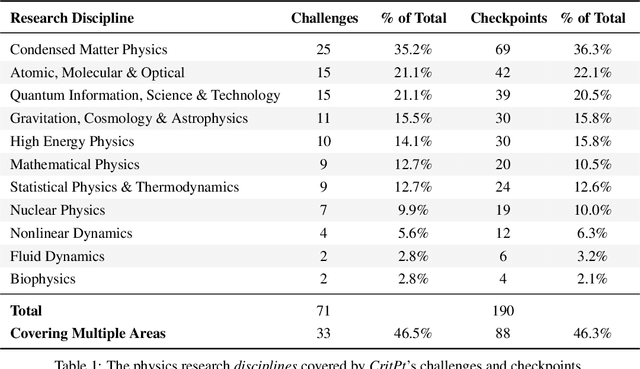



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
CreAgentive: An Agent Workflow Driven Multi-Category Creative Generation Engine
Sep 30, 2025We present CreAgentive, an agent workflow driven multi-category creative generation engine that addresses four key limitations of contemporary large language models in writing stories, drama and other categories of creatives: restricted genre diversity, insufficient output length, weak narrative coherence, and inability to enforce complex structural constructs. At its core, CreAgentive employs a Story Prototype, which is a genre-agnostic, knowledge graph-based narrative representation that decouples story logic from stylistic realization by encoding characters, events, and environments as semantic triples. CreAgentive engages a three-stage agent workflow that comprises: an Initialization Stage that constructs a user-specified narrative skeleton; a Generation Stage in which long- and short-term objectives guide multi-agent dialogues to instantiate the Story Prototype; a Writing Stage that leverages this prototype to produce multi-genre text with advanced structures such as retrospection and foreshadowing. This architecture reduces storage redundancy and overcomes the typical bottlenecks of long-form generation. In extensive experiments, CreAgentive generates thousands of chapters with stable quality and low cost (less than $1 per 100 chapters) using a general-purpose backbone model. To evaluate performance, we define a two-dimensional framework with 10 narrative indicators measuring both quality and length. Results show that CreAgentive consistently outperforms strong baselines and achieves robust performance across diverse genres, approaching the quality of human-authored novels.
Learn to Relax with Large Language Models: Solving Nonlinear Combinatorial Optimization Problems via Bidirectional Coevolution
Sep 16, 2025



Nonlinear Combinatorial Optimization Problems (NCOPs) present a formidable computational hurdle in practice, as their nonconvex nature gives rise to multi-modal solution spaces that defy efficient optimization. Traditional constraint relaxation approaches rely heavily on expert-driven, iterative design processes that lack systematic automation and scalable adaptability. While recent Large Language Model (LLM)-based optimization methods show promise for autonomous problem-solving, they predominantly function as passive constraint validators rather than proactive strategy architects, failing to handle the sophisticated constraint interactions inherent to NCOPs.To address these limitations, we introduce the first end-to-end \textbf{Auto}mated \textbf{C}onstraint \textbf{O}ptimization (AutoCO) method, which revolutionizes NCOPs resolution through learning to relax with LLMs.Specifically, we leverage structured LLM reasoning to generate constraint relaxation strategies, which are dynamically evolving with algorithmic principles and executable code through a unified triple-representation scheme. We further establish a novel bidirectional (global-local) coevolution mechanism that synergistically integrates Evolutionary Algorithms for intensive local refinement with Monte Carlo Tree Search for systematic global strategy space exploration, ensuring optimal balance between intensification and diversification in fragmented solution spaces. Finally, comprehensive experiments on three challenging NCOP benchmarks validate AutoCO's consistent effectiveness and superior performance over the baselines.
A Scenario-Driven Cognitive Approach to Next-Generation AI Memory
Sep 16, 2025



As artificial intelligence advances toward artificial general intelligence (AGI), the need for robust and human-like memory systems has become increasingly evident. Current memory architectures often suffer from limited adaptability, insufficient multimodal integration, and an inability to support continuous learning. To address these limitations, we propose a scenario-driven methodology that extracts essential functional requirements from representative cognitive scenarios, leading to a unified set of design principles for next-generation AI memory systems. Based on this approach, we introduce the \textbf{COgnitive Layered Memory Architecture (COLMA)}, a novel framework that integrates cognitive scenarios, memory processes, and storage mechanisms into a cohesive design. COLMA provides a structured foundation for developing AI systems capable of lifelong learning and human-like reasoning, thereby contributing to the pragmatic development of AGI.
A Comprehensive Survey on Underwater Acoustic Target Positioning and Tracking: Progress, Challenges, and Perspectives
Jun 17, 2025Underwater target tracking technology plays a pivotal role in marine resource exploration, environmental monitoring, and national defense security. Given that acoustic waves represent an effective medium for long-distance transmission in aquatic environments, underwater acoustic target tracking has become a prominent research area of underwater communications and networking. Existing literature reviews often offer a narrow perspective or inadequately address the paradigm shifts driven by emerging technologies like deep learning and reinforcement learning. To address these gaps, this work presents a systematic survey of this field and introduces an innovative multidimensional taxonomy framework based on target scale, sensor perception modes, and sensor collaboration patterns. Within this framework, we comprehensively survey the literature (more than 180 publications) over the period 2016-2025, spanning from the theoretical foundations to diverse algorithmic approaches in underwater acoustic target tracking. Particularly, we emphasize the transformative potential and recent advancements of machine learning techniques, including deep learning and reinforcement learning, in enhancing the performance and adaptability of underwater tracking systems. Finally, this survey concludes by identifying key challenges in the field and proposing future avenues based on emerging technologies such as federated learning, blockchain, embodied intelligence, and large models.
Bootstrapping Imitation Learning for Long-horizon Manipulation via Hierarchical Data Collection Space
May 23, 2025Imitation learning (IL) with human demonstrations is a promising method for robotic manipulation tasks. While minimal demonstrations enable robotic action execution, achieving high success rates and generalization requires high cost, e.g., continuously adding data or incrementally conducting human-in-loop processes with complex hardware/software systems. In this paper, we rethink the state/action space of the data collection pipeline as well as the underlying factors responsible for the prediction of non-robust actions. To this end, we introduce a Hierarchical Data Collection Space (HD-Space) for robotic imitation learning, a simple data collection scheme, endowing the model to train with proactive and high-quality data. Specifically, We segment the fine manipulation task into multiple key atomic tasks from a high-level perspective and design atomic state/action spaces for human demonstrations, aiming to generate robust IL data. We conduct empirical evaluations across two simulated and five real-world long-horizon manipulation tasks and demonstrate that IL policy training with HD-Space-based data can achieve significantly enhanced policy performance. HD-Space allows the use of a small amount of demonstration data to train a more powerful policy, particularly for long-horizon manipulation tasks. We aim for HD-Space to offer insights into optimizing data quality and guiding data scaling. project page: https://hd-space-robotics.github.io.
Towards Autonomous UAV Visual Object Search in City Space: Benchmark and Agentic Methodology
May 14, 2025Aerial Visual Object Search (AVOS) tasks in urban environments require Unmanned Aerial Vehicles (UAVs) to autonomously search for and identify target objects using visual and textual cues without external guidance. Existing approaches struggle in complex urban environments due to redundant semantic processing, similar object distinction, and the exploration-exploitation dilemma. To bridge this gap and support the AVOS task, we introduce CityAVOS, the first benchmark dataset for autonomous search of common urban objects. This dataset comprises 2,420 tasks across six object categories with varying difficulty levels, enabling comprehensive evaluation of UAV agents' search capabilities. To solve the AVOS tasks, we also propose PRPSearcher (Perception-Reasoning-Planning Searcher), a novel agentic method powered by multi-modal large language models (MLLMs) that mimics human three-tier cognition. Specifically, PRPSearcher constructs three specialized maps: an object-centric dynamic semantic map enhancing spatial perception, a 3D cognitive map based on semantic attraction values for target reasoning, and a 3D uncertainty map for balanced exploration-exploitation search. Also, our approach incorporates a denoising mechanism to mitigate interference from similar objects and utilizes an Inspiration Promote Thought (IPT) prompting mechanism for adaptive action planning. Experimental results on CityAVOS demonstrate that PRPSearcher surpasses existing baselines in both success rate and search efficiency (on average: +37.69% SR, +28.96% SPL, -30.69% MSS, and -46.40% NE). While promising, the performance gap compared to humans highlights the need for better semantic reasoning and spatial exploration capabilities in AVOS tasks. This work establishes a foundation for future advances in embodied target search. Dataset and source code are available at https://anonymous.4open.science/r/CityAVOS-3DF8.
DLW-CI: A Dynamic Likelihood-Weighted Cooperative Infotaxis Approach for Multi-Source Search in Urban Environments Using Consumer Drone Networks
Apr 19, 2025Consumer-grade drones equipped with low-cost sensors have emerged as a cornerstone of Autonomous Intelligent Systems (AISs) for environmental monitoring and hazardous substance detection in urban environments. However, existing research primarily addresses single-source search problems, overlooking the complexities of real-world urban scenarios where both the location and quantity of hazardous sources remain unknown. To address this issue, we propose the Dynamic Likelihood-Weighted Cooperative Infotaxis (DLW-CI) approach for consumer drone networks. Our approach enhances multi-drone collaboration in AISs by combining infotaxis (a cognitive search strategy) with optimized source term estimation and an innovative cooperative mechanism. Specifically, we introduce a novel source term estimation method that utilizes multiple parallel particle filters, with each filter dedicated to estimating the parameters of a potentially unknown source within the search scene. Furthermore, we develop a cooperative mechanism based on dynamic likelihood weights to prevent multiple drones from simultaneously estimating and searching for the same source, thus optimizing the energy efficiency and search coverage of the consumer AIS. Experimental results demonstrate that the DLW-CI approach significantly outperforms baseline methods regarding success rate, accuracy, and root mean square error, particularly in scenarios with relatively few sources, regardless of the presence of obstacles. Also, the effectiveness of the proposed approach is verified in a diffusion scenario generated by the computational fluid dynamics (CFD) model. Research findings indicate that our approach could improve source estimation accuracy and search efficiency by consumer drone-based AISs, making a valuable contribution to environmental safety monitoring applications within smart city infrastructure.