 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Exploratory Direct Preference Optimization for Multimodal Large Language Models
May 06, 2026Direct Preference Optimization (DPO) has proven to be an effective solution for mitigating hallucination in Multimodal Large Language Models (MLLMs) by learning from preference pairs. One of its key challenges lies in how to transfer the sequence-level preference into fine-grained supervision on visual fidelity. To safeguard vision-related tokens that are prone to hallucination, existing methods typically allocate training emphasis according to the model's self-assessed visual sensitivity signals. However, such sensitivity, estimated by a model still under training, introduces self-referential bias: reinforcing already well-learned visual cues while neglecting hard-to-perceive but critical details, thereby limiting deeper alignment. In this work, we propose an Uncertainty-aware Exploratory Direct Preference Optimization (UE-DPO) method for MLLMs, which enables the model to uncover its cognitive deficiencies and actively explore for self-correction, guided by token-level epistemic uncertainty. Specifically, we first quantify the uncertainty from the model's failure to ground token predictions in the given image. Then, based on an uncertainty-aware exploration intensity, we encourage more learning pressure on visually deficient tokens in preferred samples, and alleviate the over-penalization of beneficial knowledge in dispreferred samples. Further, we provide a theoretical justification for our method, and extensive experiments demonstrate its effectiveness and robustness.
SLOT: Sample-specific Language Model Optimization at Test-time
May 18, 2025We propose SLOT (Sample-specific Language Model Optimization at Test-time), a novel and parameter-efficient test-time inference approach that enhances a language model's ability to more accurately respond to individual prompts. Existing Large Language Models (LLMs) often struggle with complex instructions, leading to poor performances on those not well represented among general samples. To address this, SLOT conducts few optimization steps at test-time to update a light-weight sample-specific parameter vector. It is added to the final hidden layer before the output head, and enables efficient adaptation by caching the last layer features during per-sample optimization. By minimizing the cross-entropy loss on the input prompt only, SLOT helps the model better aligned with and follow each given instruction. In experiments, we demonstrate that our method outperforms the compared models across multiple benchmarks and LLMs. For example, Qwen2.5-7B with SLOT achieves an accuracy gain of 8.6% on GSM8K from 57.54% to 66.19%, while DeepSeek-R1-Distill-Llama-70B with SLOT achieves a SOTA accuracy of 68.69% on GPQA among 70B-level models. Our code is available at https://github.com/maple-research-lab/SLOT.
FM-TS: Flow Matching for Time Series Generation
Nov 12, 2024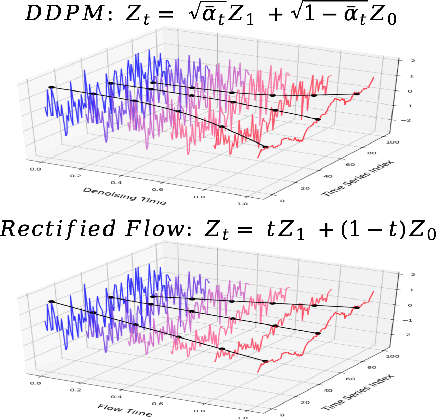
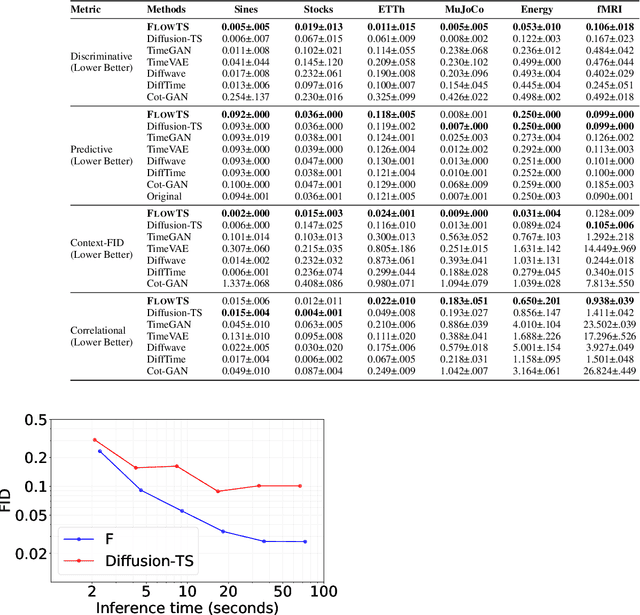
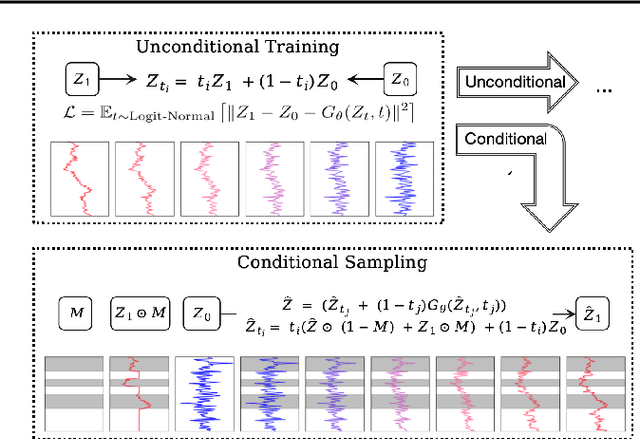
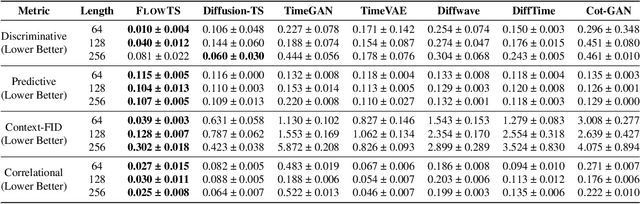
Time series generation has emerged as an essential tool for analyzing temporal data across numerous fields. While diffusion models have recently gained significant attention in generating high-quality time series, they tend to be computationally demanding and reliant on complex stochastic processes. To address these limitations, we introduce FM-TS, a rectified Flow Matching-based framework for Time Series generation, which simplifies the time series generation process by directly optimizing continuous trajectories. This approach avoids the need for iterative sampling or complex noise schedules typically required in diffusion-based models. FM-TS is more efficient in terms of training and inference. Moreover, FM-TS is highly adaptive, supporting both conditional and unconditional time series generation. Notably, through our novel inference design, the model trained in an unconditional setting can seamlessly generalize to conditional tasks without the need for retraining. Extensive benchmarking across both settings demonstrates that FM-TS consistently delivers superior performance compared to existing approaches while being more efficient in terms of training and inference. For instance, in terms of discriminative score, FM-TS achieves 0.005, 0.019, 0.011, 0.005, 0.053, and 0.106 on the Sines, Stocks, ETTh, MuJoCo, Energy, and fMRI unconditional time series datasets, respectively, significantly outperforming the second-best method which achieves 0.006, 0.067, 0.061, 0.008, 0.122, and 0.167 on the same datasets. We have achieved superior performance in solar forecasting and MuJoCo imputation tasks, significantly enhanced by our innovative $t$ power sampling method. The code is available at https://github.com/UNITES-Lab/FMTS.