 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generators are Generalist Vision Learners
Apr 22, 2026Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.
PaliGemma 2: A Family of Versatile VLMs for Transfer
Dec 04, 2024



PaliGemma 2 is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. We combine the SigLIP-So400m vision encoder that was also used by PaliGemma with the whole range of Gemma 2 models, from the 2B one all the way up to the 27B model. We train these models at three resolutions (224px, 448px, and 896px) in multiple stages to equip them with broad knowledge for transfer via fine-tuning. The resulting family of base models covering different model sizes and resolutions allows us to investigate factors impacting transfer performance (such as learning rate) and to analyze the interplay between the type of task, model size, and resolution. We further increase the number and breadth of transfer tasks beyond the scope of PaliGemma including different OCR-related tasks such as table structure recognition, molecular structure recognition, music score recognition, as well as long fine-grained captioning and radiography report generation, on which PaliGemma 2 obtains state-of-the-art results.
Evaluating Durability: Benchmark Insights into Multimodal Watermarking
Jun 06, 2024



With the development of large models, watermarks are increasingly employed to assert copyright, verify authenticity, or monitor content distribution. As applications become more multimodal, the utility of watermarking techniques becomes even more critical. The effectiveness and reliability of these watermarks largely depend on their robustness to various disturbances. However, the robustness of these watermarks in real-world scenarios, particularly under perturbations and corruption, is not well understood. To highlight the significance of robustness in watermarking techniques, our study evaluated the robustness of watermarked content generated by image and text generation models against common real-world image corruptions and text perturbations. Our results could pave the way for the development of more robust watermarking techniques in the future. Our project website can be found at \url{https://mmwatermark-robustness.github.io/}.
Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis
Oct 25, 2023



We propose Hierarchical Text Spotter (HTS), a novel method for the joint task of word-level text spotting and geometric layout analysis. HTS can recognize text in an image and identify its 4-level hierarchical structure: characters, words, lines, and paragraphs. The proposed HTS is characterized by two novel components: (1) a Unified-Detector-Polygon (UDP) that produces Bezier Curve polygons of text lines and an affinity matrix for paragraph grouping between detected lines; (2) a Line-to-Character-to-Word (L2C2W) recognizer that splits lines into characters and further merges them back into words. HTS achieves state-of-the-art results on multiple word-level text spotting benchmark datasets as well as geometric layout analysis tasks.
ICDAR 2023 Competition on Hierarchical Text Detection and Recognition
May 16, 2023



We organize a competition on hierarchical text detection and recognition. The competition is aimed to promote research into deep learning models and systems that can jointly perform text detection and recognition and geometric layout analysis. We present details of the proposed competition organization, including tasks, datasets, evaluations, and schedule. During the competition period (from January 2nd 2023 to April 1st 2023), at least 50 submissions from more than 20 teams were made in the 2 proposed tasks. Considering the number of teams and submissions, we conclude that the HierText competition has been successfully held. In this report, we will also present the competition results and insights from them.
FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction
May 04, 2023



The recent advent of self-supervised pre-training techniques has led to a surge in the use of multimodal learning in form document understanding. However, existing approaches that extend the mask language modeling to other modalities require careful multi-task tuning, complex reconstruction target designs, or additional pre-training data. In FormNetV2, we introduce a centralized multimodal graph contrastive learning strategy to unify self-supervised pre-training for all modalities in one loss. The graph contrastive objective maximizes the agreement of multimodal representations, providing a natural interplay for all modalities without special customization. In addition, we extract image features within the bounding box that joins a pair of tokens connected by a graph edge, capturing more targeted visual cues without loading a sophisticated and separately pre-trained image embedder. FormNetV2 establishes new state-of-the-art performance on FUNSD, CORD, SROIE and Payment benchmarks with a more compact model size.
Towards End-to-End Unified Scene Text Detection and Layout Analysis
Mar 28, 2022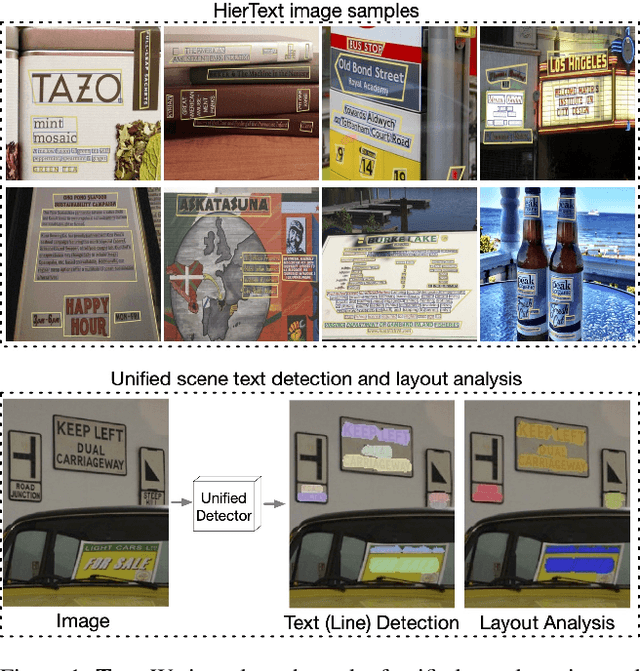
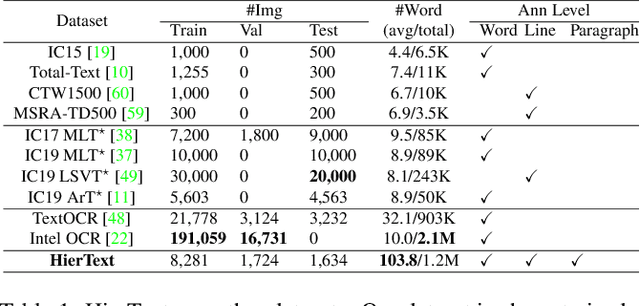
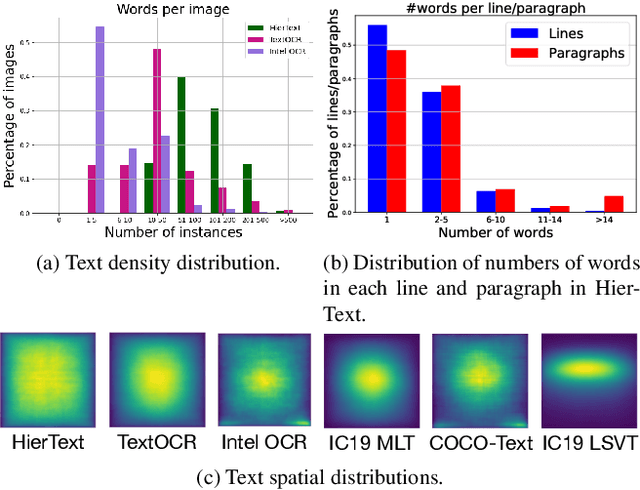

Scene text detection and document layout analysis have long been treated as two separate tasks in different image domains. In this paper, we bring them together and introduce the task of unified scene text detection and layout analysis. The first hierarchical scene text dataset is introduced to enable this novel research task. We also propose a novel method that is able to simultaneously detect scene text and form text clusters in a unified way. Comprehensive experiments show that our unified model achieves better performance than multiple well-designed baseline methods. Additionally, this model achieves state-of-the-art results on multiple scene text detection datasets without the need of complex post-processing. Dataset and code: https://github.com/google-research-datasets/hiertext.
UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World
Mar 24, 2020
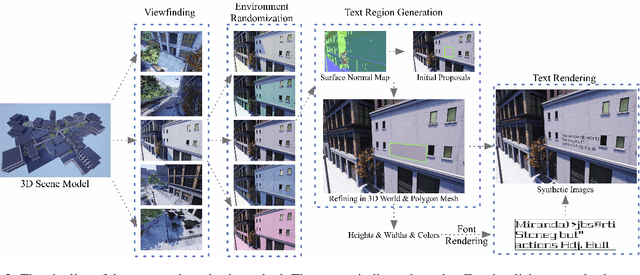
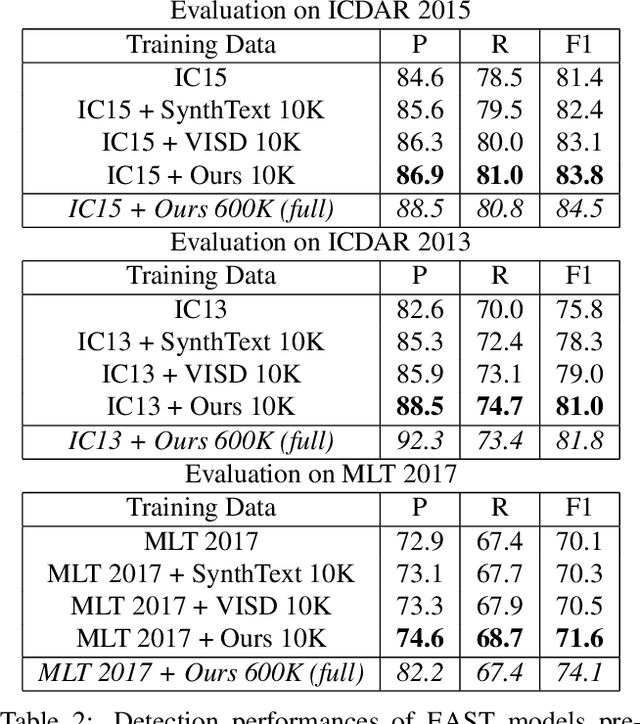

Synthetic data has been a critical tool for training scene text detection and recognition models. On the one hand, synthetic word images have proven to be a successful substitute for real images in training scene text recognizers. On the other hand, however, scene text detectors still heavily rely on a large amount of manually annotated real-world images, which are expensive. In this paper, we introduce UnrealText, an efficient image synthesis method that renders realistic images via a 3D graphics engine. 3D synthetic engine provides realistic appearance by rendering scene and text as a whole, and allows for better text region proposals with access to precise scene information, e.g. normal and even object meshes. The comprehensive experiments verify its effectiveness on both scene text detection and recognition. We also generate a multilingual version for future research into multilingual scene text detection and recognition. The code and the generated datasets are released at: https://github.com/Jyouhou/UnrealText/ .
A New Perspective for Flexible Feature Gathering in Scene Text Recognition Via Character Anchor Pooling
Feb 10, 2020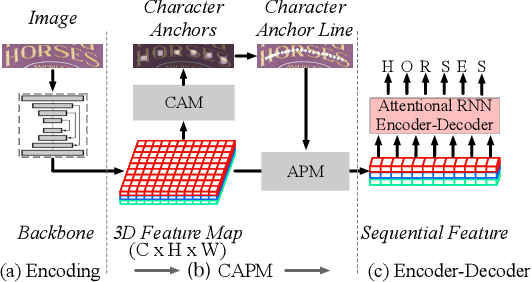
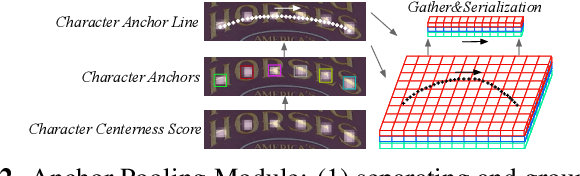

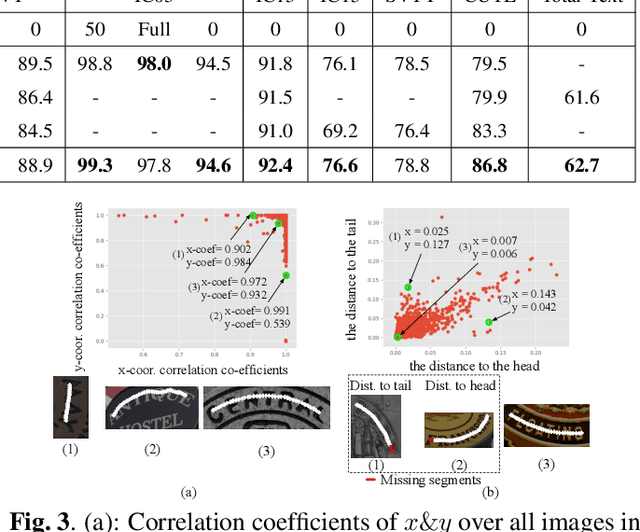
Irregular scene text recognition has attracted much attention from the research community, mainly due to the complexity of shapes of text in natural scene. However, recent methods either rely on shape-sensitive modules such as bounding box regression, or discard sequence learning. To tackle these issues, we propose a pair of coupling modules, termed as Character Anchoring Module (CAM) and Anchor Pooling Module (APM), to extract high-level semantics from two-dimensional space to form feature sequences. The proposed CAM localizes the text in a shape-insensitive way by design by anchoring characters individually. APM then interpolates and gathers features flexibly along the character anchors which enables sequence learning. The complementary modules realize a harmonic unification of spatial information and sequence learning. With the proposed modules, our recognition system surpasses previous state-of-the-art scores on irregular and perspective text datasets, including, ICDAR 2015, CUTE, and Total-Text, while paralleling state-of-the-art performance on regular text datasets.
Alchemy: Techniques for Rectification Based Irregular Scene Text Recognition
Aug 30, 2019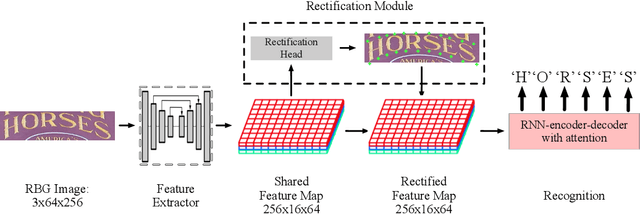
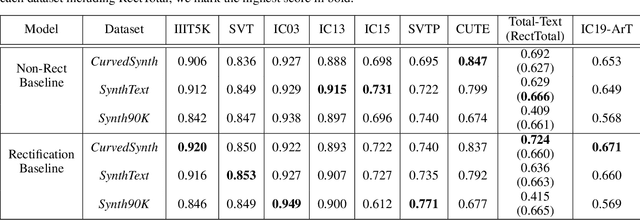

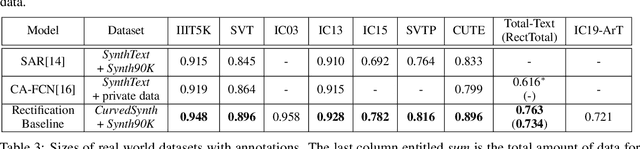
Reading text from natural images is challenging due to the great variety in text font, color, size, complex background and etc.. The perspective distortion and non-linear spatial arrangement of characters make it further difficult. While rectification based method is intuitively grounded and has pushed the envelope by far, its potential is far from being well exploited. In this paper, we present a bag of tricks that prove to significantly improve the performance of rectification based method. On curved text dataset, our method achieves an accuracy of 89.6% on CUTE-80 and 76.3% on Total-Text, an improvement over previous state-of-the-art by 6.3% and 14.7% respectively. Furthermore, our combination of tricks helps us win the ICDAR 2019 Arbitrary-Shaped Text Challenge (Latin script), achieving an accuracy of 74.3% on the held-out test set. We release our code as well as data samples for further exploration at https://github.com/Jyouhou/ICDAR2019-ArT-Recognition-Alchemy