 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPI-proxy: An Intercepting Proxy for Red-Teaming Web-Browsing AI Agents Against Indirect Prompt Injection
May 12, 2026Web-browsing AI agents are increasingly deployed in enterprise settings under strict whitelists of approved domains, yet adversaries can still influence them by embedding hidden instructions in the HTML pages those domains serve. Existing red-teaming resources fall short of this scenario: prompt-injection benchmarks ship pre-built adversarial pages that whitelisted agents cannot reach, and generic LLM scanners probe the model API rather than its retrieved content. We present IPI-proxy, an open-source toolkit for red-teaming web-browsing agents against indirect prompt injection (IPI). At its core is an intercepting proxy that rewrites real HTTP responses from whitelisted domains in flight, embedding payloads drawn from a unified library of 820 deduplicated attack strings extracted from six published benchmarks (BIPIA, InjecAgent, AgentDojo, Tensor Trust, WASP, and LLMail-Inject). A YAML-driven test harness independently parameterizes the payload set, the embedding technique (HTML comment, invisible CSS, or LLM-generated semantic prose), and the HTML insertion point (6 locations from \icode{head\_meta} to \icode{script\_comment}), enabling parameter-sweep evaluation without mock pages or sandboxed environments. A companion exfiltration tracker logs successful callbacks. This paper describes the threat model, situates IPI-proxy among contemporary IPI benchmarks and red-teaming tools, and details its architecture, design decisions, and configuration interface. By bridging static benchmarks and live deployment, IPI-proxy gives AI security teams a reproducible substrate for measuring and hardening web-browsing agents against indirect prompt injection on the same retrieval surface attackers exploit in production.
Knowledge-Free Correlated Agreement for Incentivizing Federated Learning
May 06, 2026We introduce Knowledge-Free Correlated Agreement (KFCA) to reward client contributions in federated learning (FL) without relying on ground truth, a public test set, or distribution knowledge. Under categorical reports and an honest majority, KFCA is strictly truthful, addressing the label-flipping vulnerability of Correlated Agreement (CA). We evaluate KFCA on federated LLM adapter tuning and a real-world PCB inspection task, showing efficient real-time reward computation suitable for decentralized and blockchain-based incentive designs.
AI Identity: Standards, Gaps, and Research Directions for AI Agents
Apr 25, 2026AI agents are now running real transactions, workflows, and sub-agent chains across organizational boundaries without continuous human supervision. This creates a problem no current infrastructure is equipped to solve: how do you identify, verify, and hold accountable an entity with no body, no persistent memory, and no legal standing? We define AI Identity as the continuous relationship between what an AI agent is declared to be and what it is observed to do, bounded by the confidence that those two things correspond at any given moment. Through a structured survey of industry trends, emerging standards, and technical literature, we conduct a gap analysis across the full agent identity lifecycle and make three contributions: (1) a structural comparison of human and AI identity across four dimensions (substrate, persistence, verifiability, and legal standing) showing that the asymmetry is fundamental and that extending human frameworks to agents without structural modification produces systematic failures; (2) an evaluation of current technical and regulatory documents against the identity requirements of autonomous agents, finding that none adequately address the challenge of governing nondeterministic, boundary-crossing entities; and (3) identification of five critical gaps (semantic intent verification, recursive delegation accountability, agent identity integrity, governance opacity and enforcement, and operational sustainability) that no current technology or regulatory instrument resolves. These gaps are structural; more engineering effort alone will not close them. Foundational research on AI identity is the central conclusion of this report.
MCPThreatHive: Automated Threat Intelligence for Model Context Protocol Ecosystems
Apr 15, 2026The rapid proliferation of Model Context Protocol (MCP)-based agentic systems has introduced a new category of security threats that existing frameworks are inadequately equipped to address. We present MCPThreatHive, an open-source platform that automates the end-to-end lifecycle of MCP threat intelligence: from continuous, multi-source data collection through AI-driven threat extraction and classification, to structured knowledge graph storage and interactive visualization. The platform operationalizes the MCP-38 threat taxonomy, a curated set of 38 MCP-specific threat patterns mapped to STRIDE, OWASP Top 10 for LLM Applications, and OWASP Top 10 for Agentic Applications. A composite risk scoring model provides quantitative prioritization. Through a comparative analysis of representative existing MCP security tools, we identify three critical coverage gaps that MCPThreatHive addresses: incomplete compositional attack modeling, absence of continuous threat intelligence, and lack of unified multi-framework classification.
MCP-38: A Comprehensive Threat Taxonomy for Model Context Protocol Systems (v1.0)
Mar 18, 2026The Model Context Protocol (MCP) introduces a structurally distinct attack surface that existing threat frameworks, designed for traditional software systems or generic LLM deployments, do not adequately cover. This paper presents MCP-38, a protocol-specific threat taxonomy consisting of 38 threat categories (MCP-01 through MCP-38). The taxonomy was derived through a systematic four-phase methodology: protocol decomposition, multi-framework cross-mapping, real-world incident synthesis, and remediation-surface categorization. Each category is mapped to STRIDE, OWASP Top 10 for LLM Applications (2025, LLM01--LLM10), and the OWASP Top 10 for Agentic Applications (2026, ASI01--ASI10). MCP-38 addresses critical threats arising from MCP's semantic attack surface (tool description poisoning, indirect prompt injection, parasitic tool chaining, and dynamic trust violations), none of which are adequately captured by prior work. MCP-38 provides the definitional and empirical foundation for automated threat intelligence platforms.
Comparing Uncertainty Measurement and Mitigation Methods for Large Language Models: A Systematic Review
Apr 25, 2025



Large Language Models (LLMs) have been transformative across many domains. However, hallucination -- confidently outputting incorrect information -- remains one of the leading challenges for LLMs. This raises the question of how to accurately assess and quantify the uncertainty of LLMs. Extensive literature on traditional models has explored Uncertainty Quantification (UQ) to measure uncertainty and employed calibration techniques to address the misalignment between uncertainty and accuracy. While some of these methods have been adapted for LLMs, the literature lacks an in-depth analysis of their effectiveness and does not offer a comprehensive benchmark to enable insightful comparison among existing solutions. In this work, we fill this gap via a systematic survey of representative prior works on UQ and calibration for LLMs and introduce a rigorous benchmark. Using two widely used reliability datasets, we empirically evaluate six related methods, which justify the significant findings of our review. Finally, we provide outlooks for key future directions and outline open challenges. To the best of our knowledge, this survey is the first dedicated study to review the calibration methods and relevant metrics for LLMs.
Blockchain Data Analysis in the Era of Large-Language Models
Dec 09, 2024



Blockchain data analysis is essential for deriving insights, tracking transactions, identifying patterns, and ensuring the integrity and security of decentralized networks. It plays a key role in various areas, such as fraud detection, regulatory compliance, smart contract auditing, and decentralized finance (DeFi) risk management. However, existing blockchain data analysis tools face challenges, including data scarcity, the lack of generalizability, and the lack of reasoning capability. We believe large language models (LLMs) can mitigate these challenges; however, we have not seen papers discussing LLM integration in blockchain data analysis in a comprehensive and systematic way. This paper systematically explores potential techniques and design patterns in LLM-integrated blockchain data analysis. We also outline prospective research opportunities and challenges, emphasizing the need for further exploration in this promising field. This paper aims to benefit a diverse audience spanning academia, industry, and policy-making, offering valuable insights into the integration of LLMs in blockchain data analysis.
Identifying the Key Attributes in an Unlabeled Event Log for Automated Process Discovery
Jan 27, 2023



Process mining discovers and analyzes a process model from historical event logs. The prior art methods use the attributes of case-id, activity, and timestamp hidden in an event log as clues to discover a process model. However, a user needs to manually specify them, and this can be an exhaustive task. In this paper, we propose a two-stage key attribute identification method to avoid such a manual investigation, and thus this is toward fully automated process discovery. One of the challenging tasks is how to avoid exhaustive computation due to combinatorial explosion. For this, we narrow down candidates for each key attribute by using supervised machine learning in the first stage and identify the best combination of the in the second stage. Our computational complexity can be reduced from $\mathcal{O}(N^3)$ to $\mathcal{O}(k^3)$ where $N$ and $k$ are the numbers of columns and candidates we keep in the first stage, and usually $k$ is much smaller than $N$. We evaluated our method with 14 open datasets and showed that our method could identify the key attributes even with $k = 2$ for about 20 seconds for many datasets.
Decentral and Incentivized Federated Learning Frameworks: A Systematic Literature Review
May 18, 2022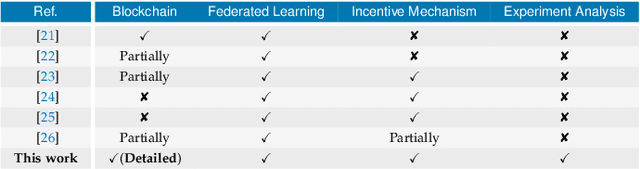
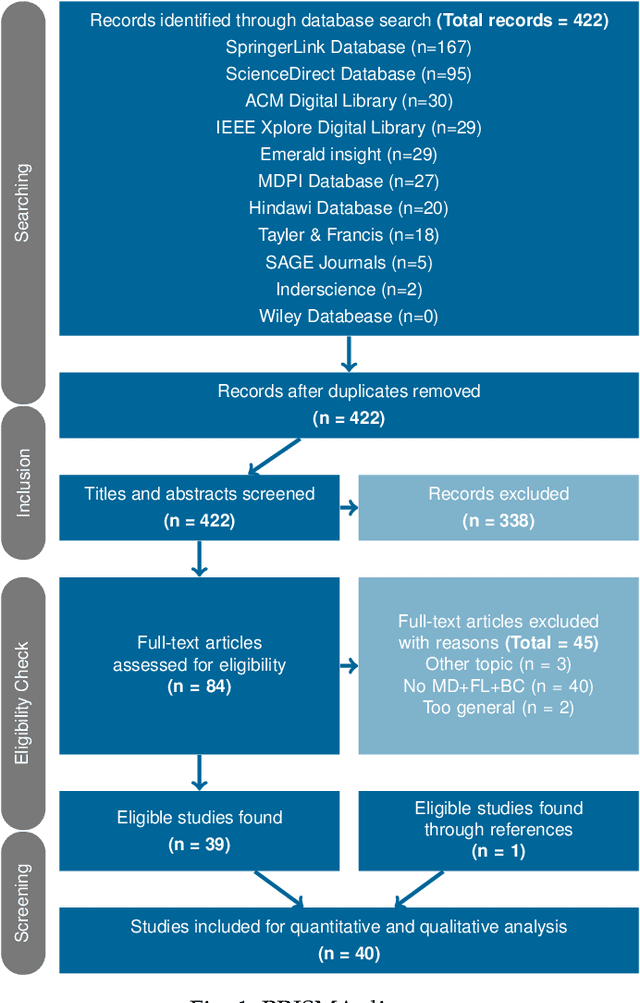
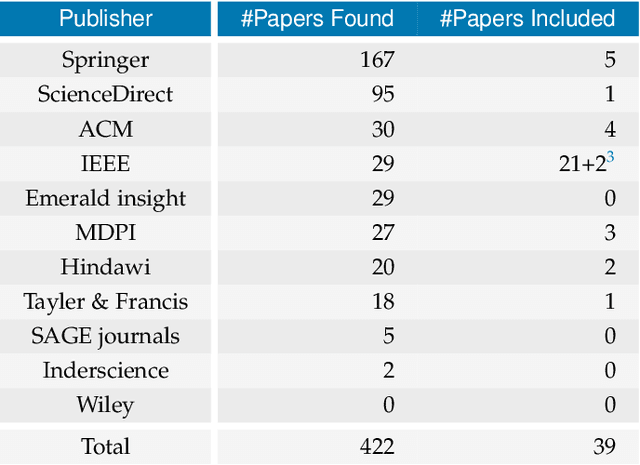
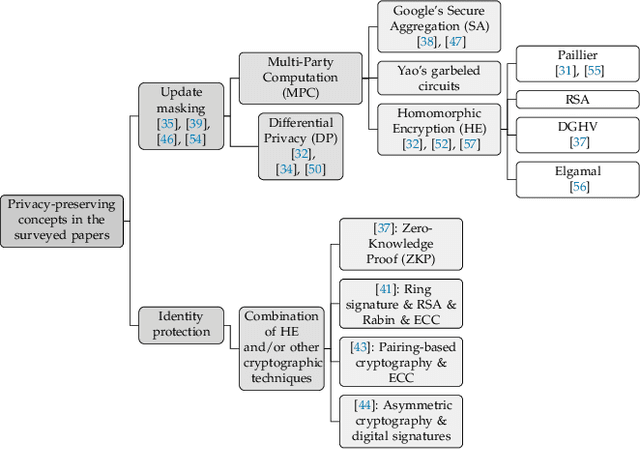
The advent of Federated Learning (FL) has ignited a new paradigm for parallel and confidential decentralized Machine Learning (ML) with the potential of utilizing the computational power of a vast number of IoT, mobile and edge devices without data leaving the respective device, ensuring privacy by design. Yet, in order to scale this new paradigm beyond small groups of already entrusted entities towards mass adoption, the Federated Learning Framework (FLF) has to become (i) truly decentralized and (ii) participants have to be incentivized. This is the first systematic literature review analyzing holistic FLFs in the domain of both, decentralized and incentivized federated learning. 422 publications were retrieved, by querying 12 major scientific databases. Finally, 40 articles remained after a systematic review and filtering process for in-depth examination. Although having massive potential to direct the future of a more distributed and secure AI, none of the analyzed FLF is production-ready. The approaches vary heavily in terms of use-cases, system design, solved issues and thoroughness. We are the first to provide a systematic approach to classify and quantify differences between FLF, exposing limitations of current works and derive future directions for research in this novel domain.