 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraVideo: High-Quality UHD Video Dataset with Comprehensive Captions
Jun 16, 2025The quality of the video dataset (image quality, resolution, and fine-grained caption) greatly influences the performance of the video generation model. The growing demand for video applications sets higher requirements for high-quality video generation models. For example, the generation of movie-level Ultra-High Definition (UHD) videos and the creation of 4K short video content. However, the existing public datasets cannot support related research and applications. In this paper, we first propose a high-quality open-sourced UHD-4K (22.4\% of which are 8K) text-to-video dataset named UltraVideo, which contains a wide range of topics (more than 100 kinds), and each video has 9 structured captions with one summarized caption (average of 824 words). Specifically, we carefully design a highly automated curation process with four stages to obtain the final high-quality dataset: \textit{i)} collection of diverse and high-quality video clips. \textit{ii)} statistical data filtering. \textit{iii)} model-based data purification. \textit{iv)} generation of comprehensive, structured captions. In addition, we expand Wan to UltraWan-1K/-4K, which can natively generate high-quality 1K/4K videos with more consistent text controllability, demonstrating the effectiveness of our data curation.We believe that this work can make a significant contribution to future research on UHD video generation. UltraVideo dataset and UltraWan models are available at https://xzc-zju.github.io/projects/UltraVideo.
Omni-AdaVideoRAG: Omni-Contextual Adaptive Retrieval-Augmented for Efficient Long Video Understanding
Jun 16, 2025Multimodal Large Language Models (MLLMs) struggle with long videos due to fixed context windows and weak long-term dependency modeling. Existing Retrieval-Augmented Generation (RAG) methods for videos use static retrieval strategies, leading to inefficiencies for simple queries and information loss for complex tasks. To address this, we propose AdaVideoRAG, a novel framework that dynamically adapts retrieval granularity based on query complexity using a lightweight intent classifier. Our framework employs an Omni-Knowledge Indexing module to build hierarchical databases from text (captions, ASR, OCR), visual features, and semantic graphs, enabling optimal resource allocation across tasks. We also introduce the HiVU benchmark for comprehensive evaluation. Experiments demonstrate improved efficiency and accuracy for long-video understanding, with seamless integration into existing MLLMs. AdaVideoRAG establishes a new paradigm for adaptive retrieval in video analysis. Codes will be open-sourced at https://github.com/xzc-zju/AdaVideoRAG.
CyberV: Cybernetics for Test-time Scaling in Video Understanding
Jun 09, 2025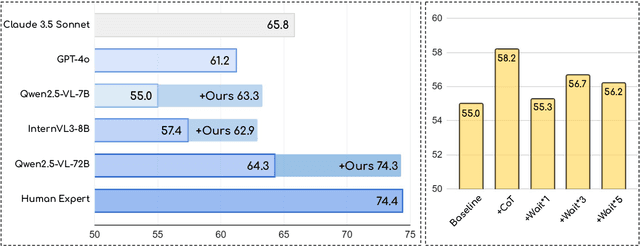
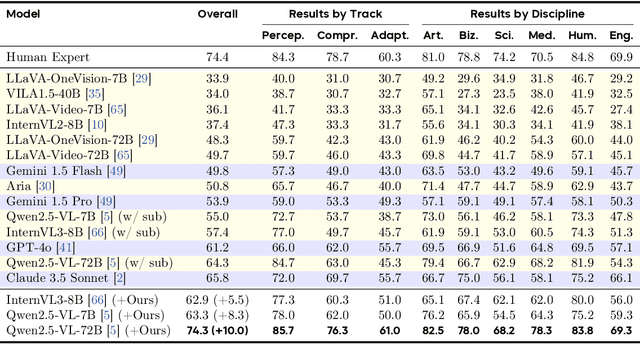
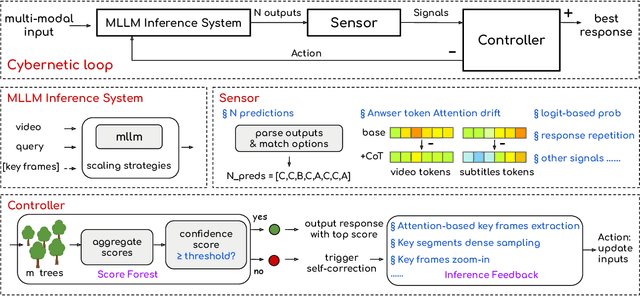
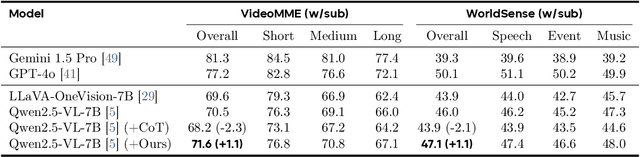
Current Multimodal Large Language Models (MLLMs) may struggle with understanding long or complex videos due to computational demands at test time, lack of robustness, and limited accuracy, primarily stemming from their feed-forward processing nature. These limitations could be more severe for models with fewer parameters. To address these limitations, we propose a novel framework inspired by cybernetic principles, redesigning video MLLMs as adaptive systems capable of self-monitoring, self-correction, and dynamic resource allocation during inference. Our approach, CyberV, introduces a cybernetic loop consisting of an MLLM Inference System, a Sensor, and a Controller. Specifically, the sensor monitors forward processes of the MLLM and collects intermediate interpretations, such as attention drift, then the controller determines when and how to trigger self-correction and generate feedback to guide the next round. This test-time adaptive scaling framework enhances frozen MLLMs without requiring retraining or additional components. Experiments demonstrate significant improvements: CyberV boosts Qwen2.5-VL-7B by 8.3% and InternVL3-8B by 5.5% on VideoMMMU, surpassing the competitive proprietary model GPT-4o. When applied to Qwen2.5-VL-72B, it yields a 10.0% improvement, achieving performance even comparable to human experts. Furthermore, our method demonstrates consistent gains on general-purpose benchmarks, such as VideoMME and WorldSense, highlighting its effectiveness and generalization capabilities in making MLLMs more robust and accurate for dynamic video understanding. The code is released at https://github.com/marinero4972/CyberV.
DiffDecompose: Layer-Wise Decomposition of Alpha-Composited Images via Diffusion Transformers
May 30, 2025Diffusion models have recently motivated great success in many generation tasks like object removal. Nevertheless, existing image decomposition methods struggle to disentangle semi-transparent or transparent layer occlusions due to mask prior dependencies, static object assumptions, and the lack of datasets. In this paper, we delve into a novel task: Layer-Wise Decomposition of Alpha-Composited Images, aiming to recover constituent layers from single overlapped images under the condition of semi-transparent/transparent alpha layer non-linear occlusion. To address challenges in layer ambiguity, generalization, and data scarcity, we first introduce AlphaBlend, the first large-scale and high-quality dataset for transparent and semi-transparent layer decomposition, supporting six real-world subtasks (e.g., translucent flare removal, semi-transparent cell decomposition, glassware decomposition). Building on this dataset, we present DiffDecompose, a diffusion Transformer-based framework that learns the posterior over possible layer decompositions conditioned on the input image, semantic prompts, and blending type. Rather than regressing alpha mattes directly, DiffDecompose performs In-Context Decomposition, enabling the model to predict one or multiple layers without per-layer supervision, and introduces Layer Position Encoding Cloning to maintain pixel-level correspondence across layers. Extensive experiments on the proposed AlphaBlend dataset and public LOGO dataset verify the effectiveness of DiffDecompose. The code and dataset will be available upon paper acceptance. Our code will be available at: https://github.com/Wangzt1121/DiffDecompose.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025



Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.
Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
May 29, 2025Unified generation models aim to handle diverse tasks across modalities -- such as text generation, image generation, and vision-language reasoning -- within a single architecture and decoding paradigm. Autoregressive unified models suffer from slow inference due to sequential decoding, and non-autoregressive unified models suffer from weak generalization due to limited pretrained backbones. We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Unlike prior unified diffusion models trained from scratch, Muddit integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder, enabling flexible and high-quality multimodal generation under a unified architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency. The work highlights the potential of purely discrete diffusion, when equipped with strong visual priors, as a scalable and effective backbone for unified generation.
PixelThink: Towards Efficient Chain-of-Pixel Reasoning
May 29, 2025Existing reasoning segmentation approaches typically fine-tune multimodal large language models (MLLMs) using image-text pairs and corresponding mask labels. However, they exhibit limited generalization to out-of-distribution scenarios without an explicit reasoning process. Although recent efforts leverage reinforcement learning through group-relative policy optimization (GRPO) to enhance reasoning ability, they often suffer from overthinking - producing uniformly verbose reasoning chains irrespective of task complexity. This results in elevated computational costs and limited control over reasoning quality. To address this problem, we propose PixelThink, a simple yet effective scheme that integrates externally estimated task difficulty and internally measured model uncertainty to regulate reasoning generation within a reinforcement learning paradigm. The model learns to compress reasoning length in accordance with scene complexity and predictive confidence. To support comprehensive evaluation, we introduce ReasonSeg-Diff, an extended benchmark with annotated reasoning references and difficulty scores, along with a suite of metrics designed to assess segmentation accuracy, reasoning quality, and efficiency jointly. Experimental results demonstrate that the proposed approach improves both reasoning efficiency and overall segmentation performance. Our work contributes novel perspectives towards efficient and interpretable multimodal understanding. The code and model will be publicly available.
So-Fake: Benchmarking and Explaining Social Media Image Forgery Detection
May 24, 2025



Recent advances in AI-powered generative models have enabled the creation of increasingly realistic synthetic images, posing significant risks to information integrity and public trust on social media platforms. While robust detection frameworks and diverse, large-scale datasets are essential to mitigate these risks, existing academic efforts remain limited in scope: current datasets lack the diversity, scale, and realism required for social media contexts, while detection methods struggle with generalization to unseen generative technologies. To bridge this gap, we introduce So-Fake-Set, a comprehensive social media-oriented dataset with over 2 million high-quality images, diverse generative sources, and photorealistic imagery synthesized using 35 state-of-the-art generative models. To rigorously evaluate cross-domain robustness, we establish a novel and large-scale (100K) out-of-domain benchmark (So-Fake-OOD) featuring synthetic imagery from commercial models explicitly excluded from the training distribution, creating a realistic testbed for evaluating real-world performance. Leveraging these resources, we present So-Fake-R1, an advanced vision-language framework that employs reinforcement learning for highly accurate forgery detection, precise localization, and explainable inference through interpretable visual rationales. Extensive experiments show that So-Fake-R1 outperforms the second-best method, with a 1.3% gain in detection accuracy and a 4.5% increase in localization IoU. By integrating a scalable dataset, a challenging OOD benchmark, and an advanced detection framework, this work establishes a new foundation for social media-centric forgery detection research. The code, models, and datasets will be released publicly.
Conditional Panoramic Image Generation via Masked Autoregressive Modeling
May 22, 2025



Recent progress in panoramic image generation has underscored two critical limitations in existing approaches. First, most methods are built upon diffusion models, which are inherently ill-suited for equirectangular projection (ERP) panoramas due to the violation of the identically and independently distributed (i.i.d.) Gaussian noise assumption caused by their spherical mapping. Second, these methods often treat text-conditioned generation (text-to-panorama) and image-conditioned generation (panorama outpainting) as separate tasks, relying on distinct architectures and task-specific data. In this work, we propose a unified framework, Panoramic AutoRegressive model (PAR), which leverages masked autoregressive modeling to address these challenges. PAR avoids the i.i.d. assumption constraint and integrates text and image conditioning into a cohesive architecture, enabling seamless generation across tasks. To address the inherent discontinuity in existing generative models, we introduce circular padding to enhance spatial coherence and propose a consistency alignment strategy to improve generation quality. Extensive experiments demonstrate competitive performance in text-to-image generation and panorama outpainting tasks while showcasing promising scalability and generalization capabilities.
BusterX: MLLM-Powered AI-Generated Video Forgery Detection and Explanation
May 19, 2025



Advances in AI generative models facilitate super-realistic video synthesis, amplifying misinformation risks via social media and eroding trust in digital content. Several research works have explored new deepfake detection methods on AI-generated images to alleviate these risks. However, with the fast development of video generation models, such as Sora and WanX, there is currently a lack of large-scale, high-quality AI-generated video datasets for forgery detection. In addition, existing detection approaches predominantly treat the task as binary classification, lacking explainability in model decision-making and failing to provide actionable insights or guidance for the public. To address these challenges, we propose \textbf{GenBuster-200K}, a large-scale AI-generated video dataset featuring 200K high-resolution video clips, diverse latest generative techniques, and real-world scenes. We further introduce \textbf{BusterX}, a novel AI-generated video detection and explanation framework leveraging multimodal large language model (MLLM) and reinforcement learning for authenticity determination and explainable rationale. To our knowledge, GenBuster-200K is the {\it \textbf{first}} large-scale, high-quality AI-generated video dataset that incorporates the latest generative techniques for real-world scenarios. BusterX is the {\it \textbf{first}} framework to integrate MLLM with reinforcement learning for explainable AI-generated video detection. Extensive comparisons with state-of-the-art methods and ablation studies validate the effectiveness and generalizability of BusterX. The code, models, and datasets will be released.