 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSRCodec: Unified and Low-Bitrate Single Codebook Codec with Sub-Band Reconstruction
Jan 06, 2026Neural Audio Codecs (NACs) can reduce transmission overhead by performing compact compression and reconstruction, which also aim to bridge the gap between continuous and discrete signals. Existing NACs can be divided into two categories: multi-codebook and single-codebook codecs. Multi-codebook codecs face challenges such as structural complexity and difficulty in adapting to downstream tasks, while single-codebook codecs, though structurally simpler, suffer from low-fidelity, ineffective modeling of unified audio, and an inability to support modeling of high-frequency audio. We propose the UniSRCodec, a single-codebook codec capable of supporting high sampling rate, low-bandwidth, high fidelity, and unified. We analyze the inefficiency of waveform-based compression and introduce the time and frequency compression method using the Mel-spectrogram, and cooperate with a Vocoder to recover the phase information of the original audio. Moreover, we propose a sub-band reconstruction technique to achieve high-quality compression across both low and high frequency bands. Subjective and objective experimental results demonstrate that UniSRCodec achieves state-of-the-art (SOTA) performance among cross-domain single-codebook codecs with only a token rate of 40, and its reconstruction quality is comparable to that of certain multi-codebook methods. Our demo page is available at https://wxzyd123.github.io/unisrcodec.
Unsupervised Text Style Transfer for Controllable Intensity
Jan 03, 2026Unsupervised Text Style Transfer (UTST) aims to build a system to transfer the stylistic properties of a given text without parallel text pairs. Compared with text transfer between style polarities, UTST for controllable intensity is more challenging due to the subtle differences in stylistic features across different intensity levels. Faced with the challenges posed by the lack of parallel data and the indistinguishability between adjacent intensity levels, we propose a SFT-then-PPO paradigm to fine-tune an LLM. We first fine-tune the LLM with synthesized parallel data. Then, we further train the LLM with PPO, where the rewards are elaborately designed for distinguishing the stylistic intensity in hierarchical levels. Both the global and local stylistic features are considered to formulate the reward functions. The experiments on two UTST benchmarks showcase that both rewards have their advantages and applying them to LLM fine-tuning can effectively improve the performance of an LLM backbone based on various evaluation metrics. Even for close levels of intensity, we can still observe the noticeable stylistic difference between the generated text.
HeteroHBA: A Generative Structure-Manipulating Backdoor Attack on Heterogeneous Graphs
Dec 31, 2025Heterogeneous graph neural networks (HGNNs) have achieved strong performance in many real-world applications, yet targeted backdoor poisoning on heterogeneous graphs remains less studied. We consider backdoor attacks for heterogeneous node classification, where an adversary injects a small set of trigger nodes and connections during training to force specific victim nodes to be misclassified into an attacker-chosen label at test time while preserving clean performance. We propose HeteroHBA, a generative backdoor framework that selects influential auxiliary neighbors for trigger attachment via saliency-based screening and synthesizes diverse trigger features and connection patterns to better match the local heterogeneous context. To improve stealthiness, we combine Adaptive Instance Normalization (AdaIN) with a Maximum Mean Discrepancy (MMD) loss to align the trigger feature distribution with benign statistics, thereby reducing detectability, and we optimize the attack with a bilevel objective that jointly promotes attack success and maintains clean accuracy. Experiments on multiple real-world heterogeneous graphs with representative HGNN architectures show that HeteroHBA consistently achieves higher attack success than prior backdoor baselines with comparable or smaller impact on clean accuracy; moreover, the attack remains effective under our heterogeneity-aware structural defense, CSD. These results highlight practical backdoor risks in heterogeneous graph learning and motivate the development of stronger defenses.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
World In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
Role-Based Fault Tolerance System for LLM RL Post-Training
Dec 27, 2025RL post-training for LLMs has been widely scaled to enhance reasoning and tool-using capabilities. However, RL post-training interleaves training and inference workloads, exposing the system to faults from both sides. Existing fault tolerance frameworks for LLMs target either training or inference, leaving the optimization potential in the asynchronous execution unexplored for RL. Our key insight is role-based fault isolation so the failure in one machine does not affect the others. We treat trainer, rollout, and other management roles in RL training as distinct distributed sub-tasks. Instead of restarting the entire RL task in ByteRobust, we recover only the failed role and reconnect it to living ones, thereby eliminating the full-restart overhead including rollout replay and initialization delay. We present RobustRL, the first comprehensive robust system to handle GPU machine errors for RL post-training Effective Training Time Ratio improvement. (1) \textit{Detect}. We implement role-aware monitoring to distinguish actual failures from role-specific behaviors to avoid the false positive and delayed detection. (2) \textit{Restart}. For trainers, we implement a non-disruptive recovery where rollouts persist state and continue trajectory generation, while the trainer is rapidly restored via rollout warm standbys. For rollout, we perform isolated machine replacement without interrupting the RL task. (3) \textit{Reconnect}. We replace static collective communication with dynamic, UCX-based (Unified Communication X) point-to-point communication, enabling immediate weight synchronization between recovered roles. In an RL training task on a 256-GPU cluster with Qwen3-8B-Math workload under 10\% failure injection frequency, RobustRL can achieve an ETTR of over 80\% compared with the 60\% in ByteRobust and achieves 8.4\%-17.4\% faster in end-to-end training time.
Generalization of Diffusion Models Arises with a Balanced Representation Space
Dec 24, 2025



Diffusion models excel at generating high-quality, diverse samples, yet they risk memorizing training data when overfit to the training objective. We analyze the distinctions between memorization and generalization in diffusion models through the lens of representation learning. By investigating a two-layer ReLU denoising autoencoder (DAE), we prove that (i) memorization corresponds to the model storing raw training samples in the learned weights for encoding and decoding, yielding localized "spiky" representations, whereas (ii) generalization arises when the model captures local data statistics, producing "balanced" representations. Furthermore, we validate these theoretical findings on real-world unconditional and text-to-image diffusion models, demonstrating that the same representation structures emerge in deep generative models with significant practical implications. Building on these insights, we propose a representation-based method for detecting memorization and a training-free editing technique that allows precise control via representation steering. Together, our results highlight that learning good representations is central to novel and meaningful generative modeling.
How Much 3D Do Video Foundation Models Encode?
Dec 23, 2025Videos are continuous 2D projections of 3D worlds. After training on large video data, will global 3D understanding naturally emerge? We study this by quantifying the 3D understanding of existing Video Foundation Models (VidFMs) pretrained on vast video data. We propose the first model-agnostic framework that measures the 3D awareness of various VidFMs by estimating multiple 3D properties from their features via shallow read-outs. Our study presents meaningful findings regarding the 3D awareness of VidFMs on multiple axes. In particular, we show that state-of-the-art video generation models exhibit a strong understanding of 3D objects and scenes, despite not being trained on any 3D data. Such understanding can even surpass that of large expert models specifically trained for 3D tasks. Our findings, together with the 3D benchmarking of major VidFMs, provide valuable observations for building scalable 3D models.
DK-STN: A Domain Knowledge Embedded Spatio-Temporal Network Model for MJO Forecast
Dec 22, 2025
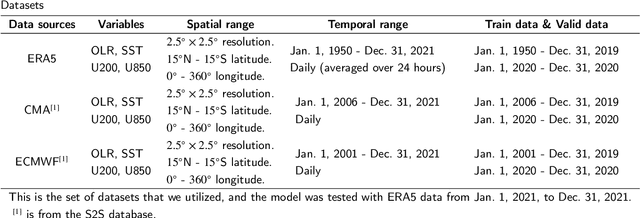
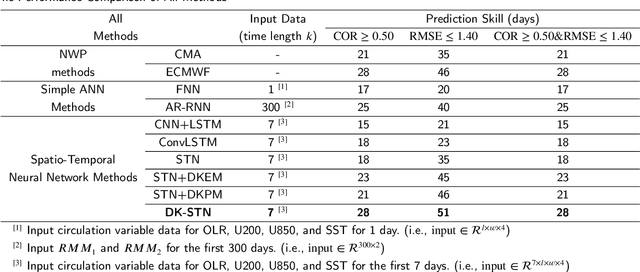

Understanding and predicting the Madden-Julian Oscillation (MJO) is fundamental for precipitation forecasting and disaster prevention. To date, long-term and accurate MJO prediction has remained a challenge for researchers. Conventional MJO prediction methods using Numerical Weather Prediction (NWP) are resource-intensive, time-consuming, and highly unstable (most NWP methods are sensitive to seasons, with better MJO forecast results in winter). While existing Artificial Neural Network (ANN) methods save resources and speed forecasting, their accuracy never reaches the 28 days predicted by the state-of-the-art NWP method, i.e., the operational forecasts from ECMWF, since neural networks cannot handle climate data effectively. In this paper, we present a Domain Knowledge Embedded Spatio-Temporal Network (DK-STN), a stable neural network model for accurate and efficient MJO forecasting. It combines the benefits of NWP and ANN methods and successfully improves the forecast accuracy of ANN methods while maintaining a high level of efficiency and stability. We begin with a spatial-temporal network (STN) and embed domain knowledge in it using two key methods: (i) applying a domain knowledge enhancement method and (ii) integrating a domain knowledge processing method into network training. We evaluated DK-STN with the 5th generation of ECMWF reanalysis (ERA5) data and compared it with ECMWF. Given 7 days of climate data as input, DK-STN can generate reliable forecasts for the following 28 days in 1-2 seconds, with an error of only 2-3 days in different seasons. DK-STN significantly exceeds ECMWF in that its forecast accuracy is equivalent to ECMWF's, while its efficiency and stability are significantly superior.
Kinematics-Aware Diffusion Policy with Consistent 3D Observation and Action Space for Whole-Arm Robotic Manipulation
Dec 19, 2025



Whole-body control of robotic manipulators with awareness of full-arm kinematics is crucial for many manipulation scenarios involving body collision avoidance or body-object interactions, which makes it insufficient to consider only the end-effector poses in policy learning. The typical approach for whole-arm manipulation is to learn actions in the robot's joint space. However, the unalignment between the joint space and actual task space (i.e., 3D space) increases the complexity of policy learning, as generalization in task space requires the policy to intrinsically understand the non-linear arm kinematics, which is difficult to learn from limited demonstrations. To address this issue, this letter proposes a kinematics-aware imitation learning framework with consistent task, observation, and action spaces, all represented in the same 3D space. Specifically, we represent both robot states and actions using a set of 3D points on the arm body, naturally aligned with the 3D point cloud observations. This spatially consistent representation improves the policy's sample efficiency and spatial generalizability while enabling full-body control. Built upon the diffusion policy, we further incorporate kinematics priors into the diffusion processes to guarantee the kinematic feasibility of output actions. The joint angle commands are finally calculated through an optimization-based whole-body inverse kinematics solver for execution. Simulation and real-world experimental results demonstrate higher success rates and stronger spatial generalizability of our approach compared to existing methods in body-aware manipulation policy learning.