 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorHub: Scalable and Elastic Weight Transfer for LLM RL Training
Apr 10, 2026Modern LLM reinforcement learning (RL) workloads require a highly efficient weight transfer system to scale training across heterogeneous computational resources. However, existing weight transfer approaches either fail to provide flexibility for dynamically scaling clusters or incur fundamental data movement overhead, resulting in poor performance. We introduce Reference-Oriented Storage (ROS), a new storage abstraction for RL weight transfer that exploits the highly replicated model weights in place. ROS presents the illusion that certain versions of the model weights are stored and can be fetched on demand. Underneath, ROS does not physically store any copies of the weights; instead, it tracks the workers that hold these weights on GPUs for inference. Upon request, ROS directly uses them to serve reads. We build TensorHub, a production-quality system that extends the ROS idea with topology-optimized transfer, strong consistency, and fault tolerance. Evaluation shows that TensorHub fully saturates RDMA bandwidth and adapts to three distinct rollout workloads with minimal engineering effort. Specifically, TensorHub reduces total GPU stall time by up to 6.7x for standalone rollouts, accelerates weight update for elastic rollout by 4.8x, and cuts cross-datacenter rollout stall time by 19x. TensorHub has been deployed in production to support cutting-edge RL training.
Role-Based Fault Tolerance System for LLM RL Post-Training
Dec 27, 2025RL post-training for LLMs has been widely scaled to enhance reasoning and tool-using capabilities. However, RL post-training interleaves training and inference workloads, exposing the system to faults from both sides. Existing fault tolerance frameworks for LLMs target either training or inference, leaving the optimization potential in the asynchronous execution unexplored for RL. Our key insight is role-based fault isolation so the failure in one machine does not affect the others. We treat trainer, rollout, and other management roles in RL training as distinct distributed sub-tasks. Instead of restarting the entire RL task in ByteRobust, we recover only the failed role and reconnect it to living ones, thereby eliminating the full-restart overhead including rollout replay and initialization delay. We present RobustRL, the first comprehensive robust system to handle GPU machine errors for RL post-training Effective Training Time Ratio improvement. (1) \textit{Detect}. We implement role-aware monitoring to distinguish actual failures from role-specific behaviors to avoid the false positive and delayed detection. (2) \textit{Restart}. For trainers, we implement a non-disruptive recovery where rollouts persist state and continue trajectory generation, while the trainer is rapidly restored via rollout warm standbys. For rollout, we perform isolated machine replacement without interrupting the RL task. (3) \textit{Reconnect}. We replace static collective communication with dynamic, UCX-based (Unified Communication X) point-to-point communication, enabling immediate weight synchronization between recovered roles. In an RL training task on a 256-GPU cluster with Qwen3-8B-Math workload under 10\% failure injection frequency, RobustRL can achieve an ETTR of over 80\% compared with the 60\% in ByteRobust and achieves 8.4\%-17.4\% faster in end-to-end training time.
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Apr 15, 2025While reasoning models (e.g., DeepSeek R1) trained with reinforcement learning (RL), excel in textual reasoning, they struggle in scenarios requiring structured problem-solving, such as geometric reasoning, concise computation, or complex equation solving-areas where computational tools like code interpreters (CI) demonstrate distinct advantages. To bridge this gap, we propose ReTool, which enhances long-form reasoning with tool-integrated learning, including two key features: (1) dynamic interleaving of real-time code execution within natural language reasoning processes, and (2) an automated RL paradigm that allows policy rollouts with multi-turn real-time code execution and teaches the model in learning when and how to invoke tools based on outcome feedback. ReTool employs a systematic training framework, beginning with synthetic cold-start data generation to produce code-augmented long-form reasoning traces for fine-tuning base models. Subsequent RL training leverages task outcomes as rewards to iteratively refine the model's tool use strategy, enabling autonomous discovery of optimal tool invocation patterns without human priors. Experiments on the challenging MATH Olympiad benchmark AIME demonstrate ReTool's superiority: Our 32B model achieves 67% accuracy with 400 training steps, outperforming text-based RL baseline (40% accuracy, 1080 steps) in efficiency and performance. Remarkably, ReTool-32B attains 72.5% accuracy in extended settings, surpassing OpenAI's o1-preview by 27.9%. Further analysis reveals emergent behaviors such as code self-correction, signaling an ''aha moment'' in which the model autonomously masters adaptive tool use. These findings highlight the promise of outcome-driven tool integration for advancing complex mathematical reasoning and offer new insights into hybrid neuro-symbolic systems.
PASS3D: Precise and Accelerated Semantic Segmentation for 3D Point Cloud
Sep 04, 2019

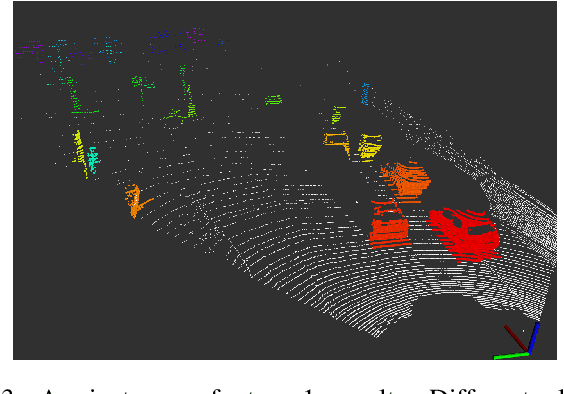

In this paper, we propose PASS3D to achieve point-wise semantic segmentation for 3D point cloud. Our framework combines the efficiency of traditional geometric methods with robustness of deep learning methods, consisting of two stages: At stage-1, our accelerated cluster proposal algorithm will generate refined cluster proposals by segmenting point clouds without ground, capable of generating less redundant proposals with higher recall in an extremely short time; stage-2 we will amplify and further process these proposals by a neural network to estimate semantic label for each point and meanwhile propose a novel data augmentation method to enhance the network's recognition capability for all categories especially for non-rigid objects. Evaluated on KITTI raw dataset, PASS3D stands out against the state-of-the-art on some results, making itself competent to 3D perception in autonomous driving system. Our source code will be open-sourced. A video demonstration is available at https://www.youtube.com/watch?v=cukEqDuP_Qw.