 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Jun 04, 2026Despite generating increasingly photorealistic images, text-to-image (T2I) models still exhibit localized, subtle, and structurally complex failures. Diagnosing these failures requires instance-level feedback that answers where a defect occurs, what type it is, why it is defective, and its importance to overall image quality. While recent dense-feedback methods move beyond scalar supervision, their heatmap-centric representations still formulate diagnosis as pixel-field regression, making it difficult to localize variable-cardinality defects and bind semantic reasons to individual failures. To address this representation bottleneck, we propose Structured Defect Grounding (SDG), which casts T2I diagnosis as structured set prediction by modeling each defect as a (location, type, reason, importance) tuple. To make this formulation trainable and measurable, we introduce SDG-30K, a 30K-image dataset with box-grounded annotations across four modern T2I generators, together with a dedicated evaluation protocol, SDG-Eval. Building on this structured representation, we further present a diagnosis-to-alignment framework in which a Vision-Language Model (VLM) serves as the SDG detector, and BoxFlow-GRPO converts predicted defect sets into box-derived, importance-weighted spatial rewards for diffusion model alignment. Extensive experiments show that our SDG detector outperforms leading proprietary VLMs on structured defect grounding, while SDG-guided rewards consistently improve T2I alignment and support localized image refinement. These results establish SDG as a unified, instance-level interface for diagnosing, evaluating, and enhancing modern generative models.
MagicID: Flexible ID Fidelity Generation System
Aug 20, 2024



Portrait Fidelity Generation is a prominent research area in generative models, with a primary focus on enhancing both controllability and fidelity. Current methods face challenges in generating high-fidelity portrait results when faces occupy a small portion of the image with a low resolution, especially in multi-person group photo settings. To tackle these issues, we propose a systematic solution called MagicID, based on a self-constructed million-level multi-modal dataset named IDZoom. MagicID consists of Multi-Mode Fusion training strategy (MMF) and DDIM Inversion based ID Restoration inference framework (DIIR). During training, MMF iteratively uses the skeleton and landmark modalities from IDZoom as conditional guidance. By introducing the Clone Face Tuning in training stage and Mask Guided Multi-ID Cross Attention (MGMICA) in inference stage, explicit constraints on face positional features are achieved for multi-ID group photo generation. The DIIR aims to address the issue of artifacts. The DDIM Inversion is used in conjunction with face landmarks, global and local face features to achieve face restoration while keeping the background unchanged. Additionally, DIIR is plug-and-play and can be applied to any diffusion-based portrait generation method. To validate the effectiveness of MagicID, we conducted extensive comparative and ablation experiments. The experimental results demonstrate that MagicID has significant advantages in both subjective and objective metrics, and achieves controllable generation in multi-person scenarios.
Vid2Act: Activate Offline Videos for Visual RL
Jun 07, 2023Pretraining RL models on offline video datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in tasks, dynamics, and behaviors across domains. A recent model, APV, sidesteps the accompanied action records in offline datasets and instead focuses on pretraining a task-irrelevant, action-free world model within the source domains. We present Vid2Act, a model-based RL method that learns to transfer valuable action-conditioned dynamics and potentially useful action demonstrations from offline to online settings. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the domain relevance for both dynamics representation transfer and policy transfer. Specifically, we train the world models to generate a set of time-varying task similarities using a domain-selective knowledge distillation loss. These similarities serve two purposes: (i) adaptively transferring the most useful source knowledge to facilitate dynamics learning, and (ii) learning to replay the most relevant source actions to guide the target policy. We demonstrate the advantages of Vid2Act over the action-free visual RL pretraining method in both Meta-World and DeepMind Control Suite.
MMDR: A Result Feature Fusion Object Detection Approach for Autonomous System
Apr 19, 2023



Object detection has been extensively utilized in autonomous systems in recent years, encompassing both 2D and 3D object detection. Recent research in this field has primarily centered around multimodal approaches for addressing this issue.In this paper, a multimodal fusion approach based on result feature-level fusion is proposed. This method utilizes the outcome features generated from single modality sources, and fuses them for downstream tasks.Based on this method, a new post-fusing network is proposed for multimodal object detection, which leverages the single modality outcomes as features. The proposed approach, called Multi-Modal Detector based on Result features (MMDR), is designed to work for both 2D and 3D object detection tasks. Compared to previous multimodal models, the proposed approach in this paper performs feature fusion at a later stage, enabling better representation of the deep-level features of single modality sources. Additionally, the MMDR model incorporates shallow global features during the feature fusion stage, endowing the model with the ability to perceive background information and the overall input, thereby avoiding issues such as missed detections.
Obstacle-Transformer: A Trajectory Prediction Network Based on Surrounding Trajectories
Apr 16, 2023



Recurrent Neural Network, Long Short-Term Memory, and Transformer have made great progress in predicting the trajectories of moving objects. Although the trajectory element with the surrounding scene features has been merged to improve performance, there still exist some problems to be solved. One is that the time series processing models will increase the inference time with the increase of the number of prediction sequences. Another lies in which the features can not be extracted from the scene's image and point cloud in some situations. Therefore, this paper proposes an Obstacle-Transformer to predict trajectory in a constant inference time. An ``obstacle'' is designed by the surrounding trajectory rather than images or point clouds, making Obstacle-Transformer more applicable in a wider range of scenarios. Experiments are conducted on ETH and UCY data sets to verify the performance of our model.
* 8 pages, 4 figures
Improving Masked Autoencoders by Learning Where to Mask
Mar 12, 2023



Masked image modeling is a promising self-supervised learning method for visual data. It is typically built upon image patches with random masks, which largely ignores the variation of information density between them. The question is: Is there a better masking strategy than random sampling and how can we learn it? We empirically study this problem and initially find that introducing object-centric priors in mask sampling can significantly improve the learned representations. Inspired by this observation, we present AutoMAE, a fully differentiable framework that uses Gumbel-Softmax to interlink an adversarially-trained mask generator and a mask-guided image modeling process. In this way, our approach can adaptively find patches with higher information density for different images, and further strike a balance between the information gain obtained from image reconstruction and its practical training difficulty. In our experiments, AutoMAE is shown to provide effective pretraining models on standard self-supervised benchmarks and downstream tasks.
Predictive Experience Replay for Continual Visual Control and Forecasting
Mar 12, 2023



Learning physical dynamics in a series of non-stationary environments is a challenging but essential task for model-based reinforcement learning (MBRL) with visual inputs. It requires the agent to consistently adapt to novel tasks without forgetting previous knowledge. In this paper, we present a new continual learning approach for visual dynamics modeling and explore its efficacy in visual control and forecasting. The key assumption is that an ideal world model can provide a non-forgetting environment simulator, which enables the agent to optimize the policy in a multi-task learning manner based on the imagined trajectories from the world model. To this end, we first propose the mixture world model that learns task-specific dynamics priors with a mixture of Gaussians, and then introduce a new training strategy to overcome catastrophic forgetting, which we call predictive experience replay. Finally, we extend these methods to continual RL and further address the value estimation problems with the exploratory-conservative behavior learning approach. Our model remarkably outperforms the naive combinations of existing continual learning and visual RL algorithms on DeepMind Control and Meta-World benchmarks with continual visual control tasks. It is also shown to effectively alleviate the forgetting of spatiotemporal dynamics in video prediction datasets with evolving domains.
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
Sep 21, 2022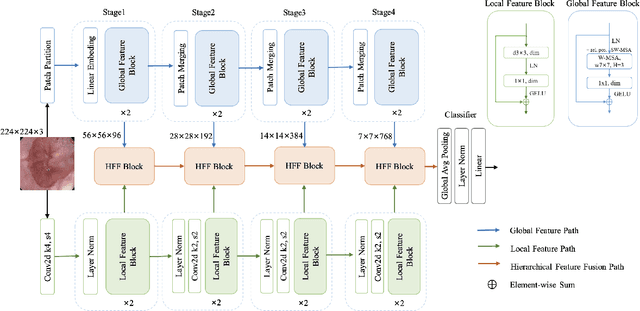
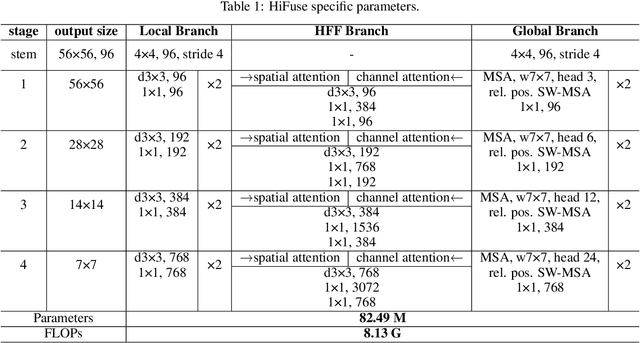
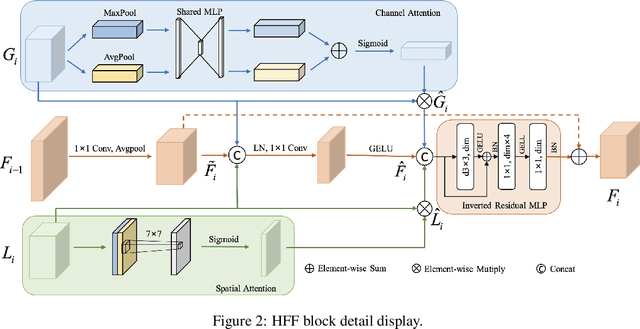
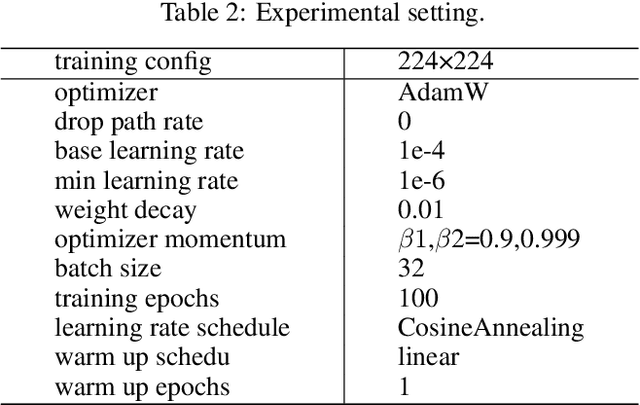
Medical image classification has developed rapidly under the impetus of the convolutional neural network (CNN). Due to the fixed size of the receptive field of the convolution kernel, it is difficult to capture the global features of medical images. Although the self-attention-based Transformer can model long-range dependencies, it has high computational complexity and lacks local inductive bias. Much research has demonstrated that global and local features are crucial for image classification. However, medical images have a lot of noisy, scattered features, intra-class variation, and inter-class similarities. This paper proposes a three-branch hierarchical multi-scale feature fusion network structure termed as HiFuse for medical image classification as a new method. It can fuse the advantages of Transformer and CNN from multi-scale hierarchies without destroying the respective modeling so as to improve the classification accuracy of various medical images. A parallel hierarchy of local and global feature blocks is designed to efficiently extract local features and global representations at various semantic scales, with the flexibility to model at different scales and linear computational complexity relevant to image size. Moreover, an adaptive hierarchical feature fusion block (HFF block) is designed to utilize the features obtained at different hierarchical levels comprehensively. The HFF block contains spatial attention, channel attention, residual inverted MLP, and shortcut to adaptively fuse semantic information between various scale features of each branch. The accuracy of our proposed model on the ISIC2018 dataset is 7.6% higher than baseline, 21.5% on the Covid-19 dataset, and 10.4% on the Kvasir dataset. Compared with other advanced models, the HiFuse model performs the best. Our code is open-source and available from https://github.com/huoxiangzuo/HiFuse.
Continual Predictive Learning from Videos
Apr 12, 2022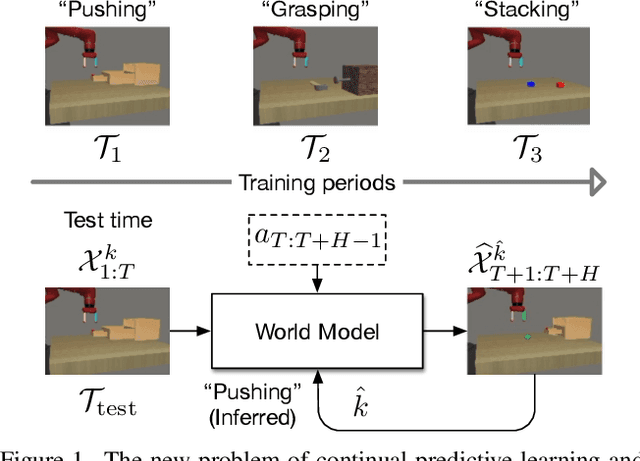
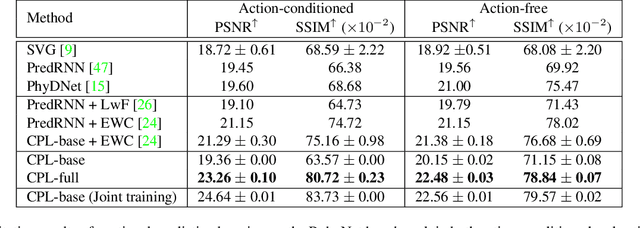
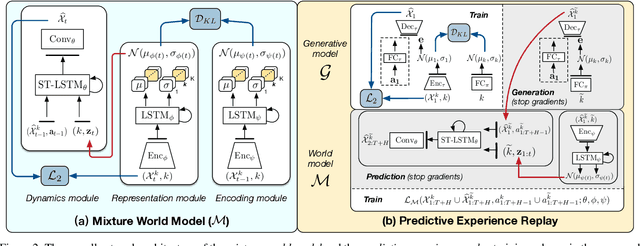
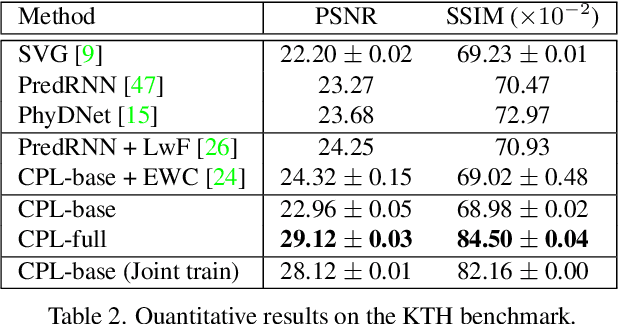
Predictive learning ideally builds the world model of physical processes in one or more given environments. Typical setups assume that we can collect data from all environments at all times. In practice, however, different prediction tasks may arrive sequentially so that the environments may change persistently throughout the training procedure. Can we develop predictive learning algorithms that can deal with more realistic, non-stationary physical environments? In this paper, we study a new continual learning problem in the context of video prediction, and observe that most existing methods suffer from severe catastrophic forgetting in this setup. To tackle this problem, we propose the continual predictive learning (CPL) approach, which learns a mixture world model via predictive experience replay and performs test-time adaptation with non-parametric task inference. We construct two new benchmarks based on RoboNet and KTH, in which different tasks correspond to different physical robotic environments or human actions. Our approach is shown to effectively mitigate forgetting and remarkably outperform the na\"ive combinations of previous art in video prediction and continual learning.
Fully Context-Aware Image Inpainting with a Learned Semantic Pyramid
Dec 08, 2021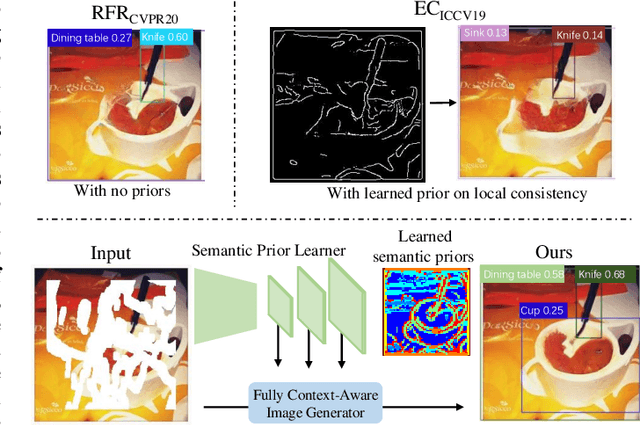

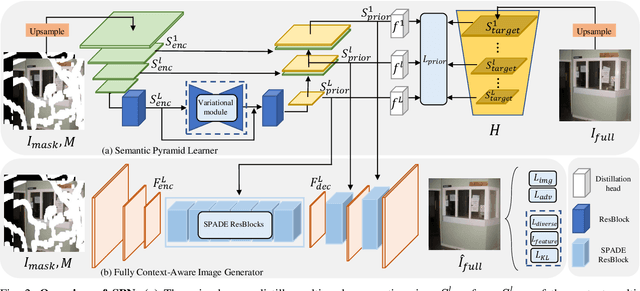
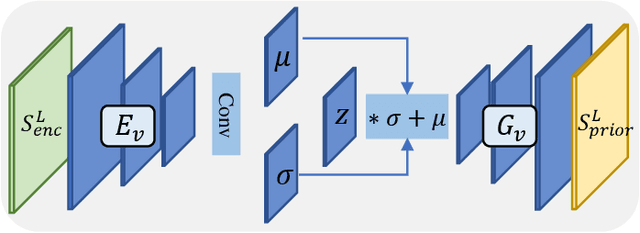
Restoring reasonable and realistic content for arbitrary missing regions in images is an important yet challenging task. Although recent image inpainting models have made significant progress in generating vivid visual details, they can still lead to texture blurring or structural distortions due to contextual ambiguity when dealing with more complex scenes. To address this issue, we propose the Semantic Pyramid Network (SPN) motivated by the idea that learning multi-scale semantic priors from specific pretext tasks can greatly benefit the recovery of locally missing content in images. SPN consists of two components. First, it distills semantic priors from a pretext model into a multi-scale feature pyramid, achieving a consistent understanding of the global context and local structures. Within the prior learner, we present an optional module for variational inference to realize probabilistic image inpainting driven by various learned priors. The second component of SPN is a fully context-aware image generator, which adaptively and progressively refines low-level visual representations at multiple scales with the (stochastic) prior pyramid. We train the prior learner and the image generator as a unified model without any post-processing. Our approach achieves the state of the art on multiple datasets, including Places2, Paris StreetView, CelebA, and CelebA-HQ, under both deterministic and probabilistic inpainting setups.