 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeinan Zhang
Offline Pre-trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks
Dec 20, 2021
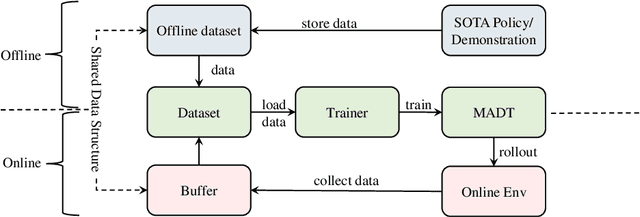
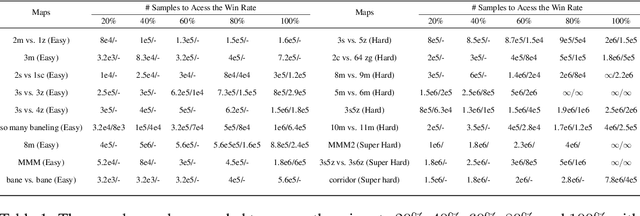
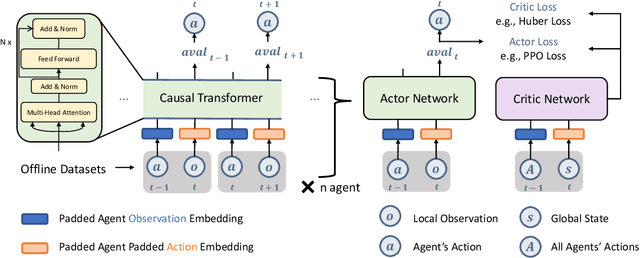
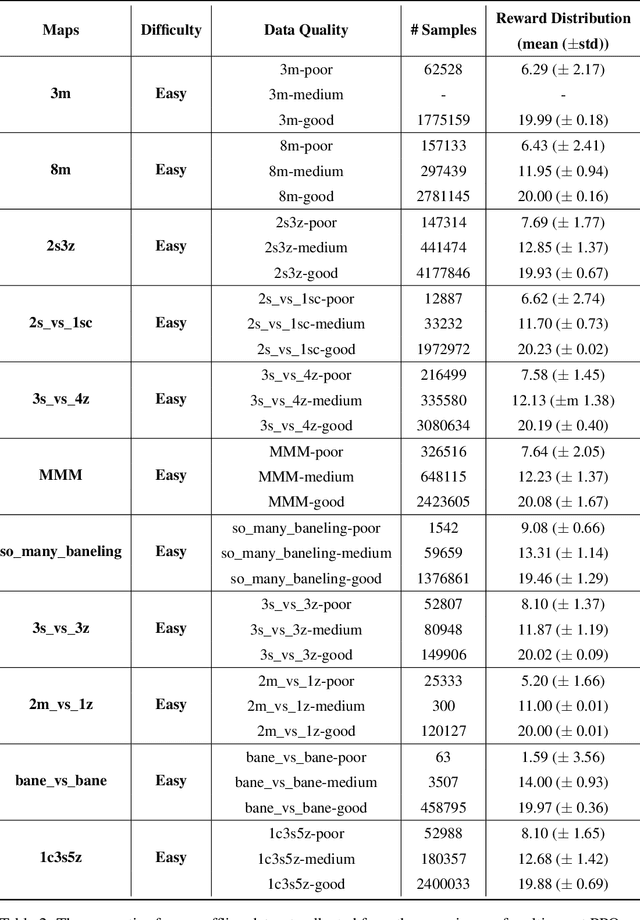
Offline reinforcement learning leverages previously-collected offline datasets to learn optimal policies with no necessity to access the real environment. Such a paradigm is also desirable for multi-agent reinforcement learning (MARL) tasks, given the increased interactions among agents and with the enviroment. Yet, in MARL, the paradigm of offline pre-training with online fine-tuning has not been studied, nor datasets or benchmarks for offline MARL research are available. In this paper, we facilitate the research by providing large-scale datasets, and use them to examine the usage of the Decision Transformer in the context of MARL. We investigate the generalisation of MARL offline pre-training in the following three aspects: 1) between single agents and multiple agents, 2) from offline pretraining to the online fine-tuning, and 3) to that of multiple downstream tasks with few-shot and zero-shot capabilities. We start by introducing the first offline MARL dataset with diverse quality levels based on the StarCraftII environment, and then propose the novel architecture of multi-agent decision transformer (MADT) for effective offline learning. MADT leverages transformer's modelling ability of sequence modelling and integrates it seamlessly with both offline and online MARL tasks. A crucial benefit of MADT is that it learns generalizable policies that can transfer between different types of agents under different task scenarios. On StarCraft II offline dataset, MADT outperforms the state-of-the-art offline RL baselines. When applied to online tasks, the pre-trained MADT significantly improves sample efficiency, and enjoys strong performance both few-short and zero-shot cases. To our best knowledge, this is the first work that studies and demonstrates the effectiveness of offline pre-trained models in terms of sample efficiency and generalisability enhancements in MARL.
Offline Pre-trained Multi-Agent Decision Transformer: One Big Sequence Model Conquers All StarCraftII Tasks
Dec 06, 2021Offline reinforcement learning leverages static datasets to learn optimal policies with no necessity to access the environment. This technique is desirable for multi-agent learning tasks due to the expensiveness of agents' online interactions and the demanding number of samples during training. Yet, in multi-agent reinforcement learning (MARL), the paradigm of offline pre-training with online fine-tuning has never been studied, nor datasets or benchmarks for offline MARL research are available. In this paper, we try to answer the question of whether offline pre-training in MARL is able to learn generalisable policy representations that can help improve the performance of multiple downstream tasks. We start by introducing the first offline MARL dataset with diverse quality levels based on the StarCraftII environment, and then propose the novel architecture of multi-agent decision transformer (MADT) for effective offline learning. MADT leverages Transformer's modelling ability of temporal representations and integrates it with both offline and online MARL tasks. A crucial benefit of MADT is that it learns generalisable policies that can transfer between different types of agents under different task scenarios. When evaluated on StarCraft II offline dataset, MADT demonstrates superior performance than state-of-the-art offline RL baselines. When applied to online tasks, the pre-trained MADT significantly improves sample efficiency, and enjoys strong performance even in zero-shot cases. To our best knowledge, this is the first work that studies and demonstrates the effectiveness of offline pre-trained models in terms of sample efficiency and generalisability enhancements in MARL.
Towards Return Parity in Markov Decision Processes
Nov 19, 2021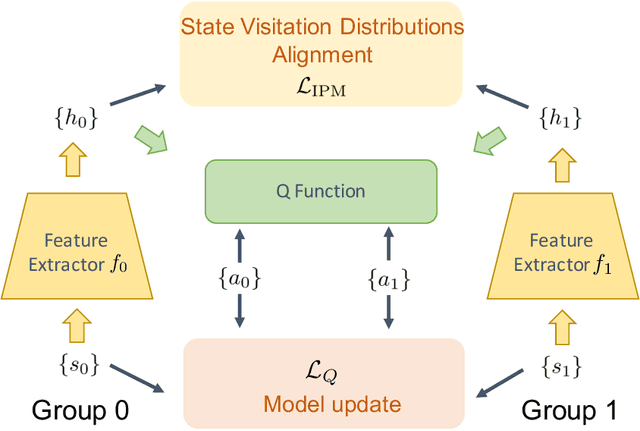

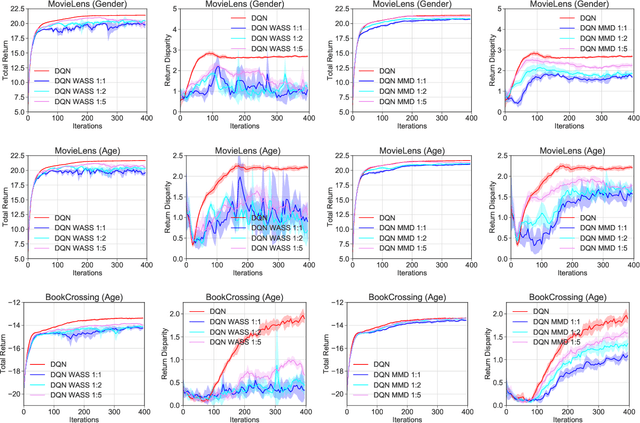
Algorithmic decisions made by machine learning models in high-stakes domains may have lasting impacts over time. Unfortunately, naive applications of standard fairness criterion in static settings over temporal domains may lead to delayed and adverse effects. To understand the dynamics of performance disparity, we study a fairness problem in Markov decision processes (MDPs). Specifically, we propose return parity, a fairness notion that requires MDPs from different demographic groups that share the same state and action spaces to achieve approximately the same expected time-discounted rewards. We first provide a decomposition theorem for return disparity, which decomposes the return disparity of any two MDPs into the distance between group-wise reward functions, the discrepancy of group policies, and the discrepancy between state visitation distributions induced by the group policies. Motivated by our decomposition theorem, we propose algorithms to mitigate return disparity via learning a shared group policy with state visitation distributional alignment using integral probability metrics. We conduct experiments to corroborate our results, showing that the proposed algorithm can successfully close the disparity gap while maintaining the performance of policies on two real-world recommender system benchmark datasets.
On Effective Scheduling of Model-based Reinforcement Learning
Nov 16, 2021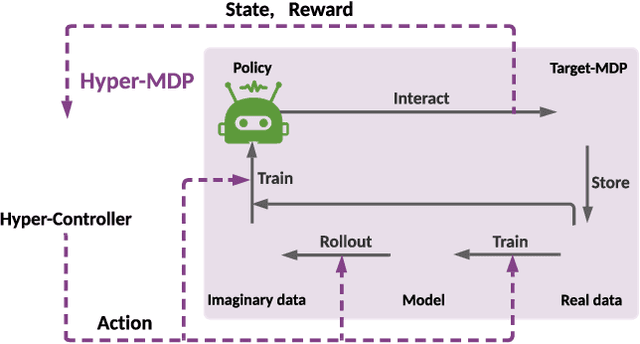
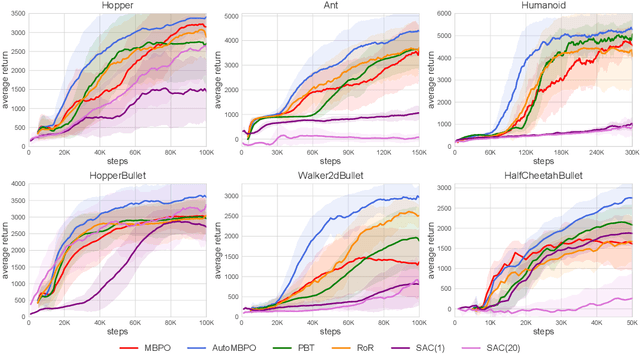

Model-based reinforcement learning has attracted wide attention due to its superior sample efficiency. Despite its impressive success so far, it is still unclear how to appropriately schedule the important hyperparameters to achieve adequate performance, such as the real data ratio for policy optimization in Dyna-style model-based algorithms. In this paper, we first theoretically analyze the role of real data in policy training, which suggests that gradually increasing the ratio of real data yields better performance. Inspired by the analysis, we propose a framework named AutoMBPO to automatically schedule the real data ratio as well as other hyperparameters in training model-based policy optimization (MBPO) algorithm, a representative running case of model-based methods. On several continuous control tasks, the MBPO instance trained with hyperparameters scheduled by AutoMBPO can significantly surpass the original one, and the real data ratio schedule found by AutoMBPO shows consistency with our theoretical analysis.
QA4PRF: A Question Answering based Framework for Pseudo Relevance Feedback
Nov 16, 2021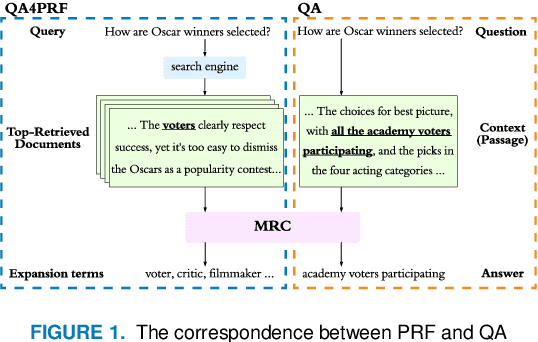

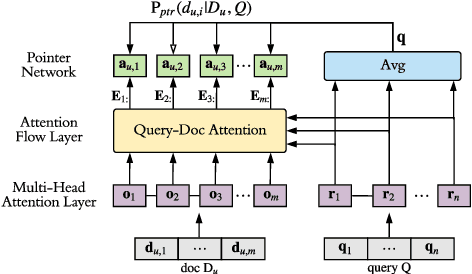

Pseudo relevance feedback (PRF) automatically performs query expansion based on top-retrieved documents to better represent the user's information need so as to improve the search results. Previous PRF methods mainly select expansion terms with high occurrence frequency in top-retrieved documents or with high semantic similarity with the original query. However, existing PRF methods hardly try to understand the content of documents, which is very important in performing effective query expansion to reveal the user's information need. In this paper, we propose a QA-based framework for PRF called QA4PRF to utilize contextual information in documents. In such a framework, we formulate PRF as a QA task, where the query and each top-retrieved document play the roles of question and context in the corresponding QA system, while the objective is to find some proper terms to expand the original query by utilizing contextual information, which are similar answers in QA task. Besides, an attention-based pointer network is built on understanding the content of top-retrieved documents and selecting the terms to represent the original query better. We also show that incorporating the traditional supervised learning methods, such as LambdaRank, to integrate PRF information will further improve the performance of QA4PRF. Extensive experiments on three real-world datasets demonstrate that QA4PRF significantly outperforms the state-of-the-art methods.
Learning Logic Rules for Document-level Relation Extraction
Nov 09, 2021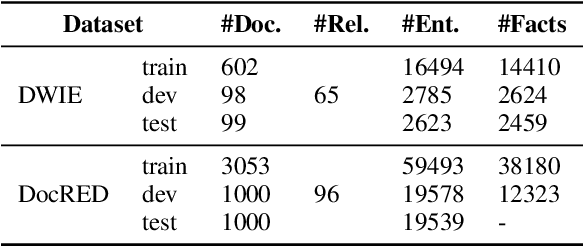

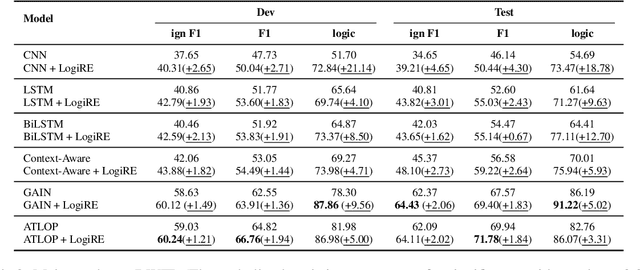

Document-level relation extraction aims to identify relations between entities in a whole document. Prior efforts to capture long-range dependencies have relied heavily on implicitly powerful representations learned through (graph) neural networks, which makes the model less transparent. To tackle this challenge, in this paper, we propose LogiRE, a novel probabilistic model for document-level relation extraction by learning logic rules. LogiRE treats logic rules as latent variables and consists of two modules: a rule generator and a relation extractor. The rule generator is to generate logic rules potentially contributing to final predictions, and the relation extractor outputs final predictions based on the generated logic rules. Those two modules can be efficiently optimized with the expectation-maximization (EM) algorithm. By introducing logic rules into neural networks, LogiRE can explicitly capture long-range dependencies as well as enjoy better interpretation. Empirical results show that LogiRE significantly outperforms several strong baselines in terms of relation performance (1.8 F1 score) and logical consistency (over 3.3 logic score). Our code is available at https://github.com/rudongyu/LogiRE.
AIM: Automatic Interaction Machine for Click-Through Rate Prediction
Nov 05, 2021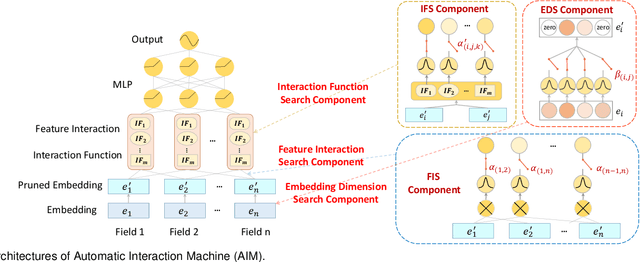
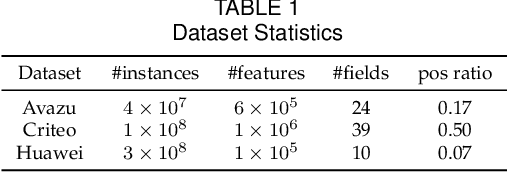
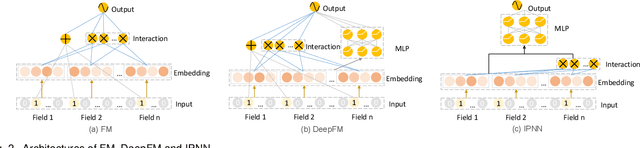
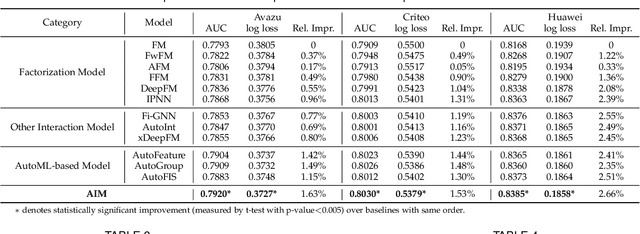
Feature embedding learning and feature interaction modeling are two crucial components of deep models for Click-Through Rate (CTR) prediction. Most existing deep CTR models suffer from the following three problems. First, feature interactions are either manually designed or simply enumerated. Second, all the feature interactions are modeled with an identical interaction function. Third, in most existing models, different features share the same embedding size which leads to memory inefficiency. To address these three issues mentioned above, we propose Automatic Interaction Machine (AIM) with three core components, namely, Feature Interaction Search (FIS), Interaction Function Search (IFS) and Embedding Dimension Search (EDS), to select significant feature interactions, appropriate interaction functions and necessary embedding dimensions automatically in a unified framework. Specifically, FIS component automatically identifies different orders of essential feature interactions with useless ones pruned; IFS component selects appropriate interaction functions for each individual feature interaction in a learnable way; EDS component automatically searches proper embedding size for each feature. Offline experiments on three large-scale datasets validate the superior performance of AIM. A three-week online A/B test in the recommendation service of a mainstream app market shows that AIM improves DeepFM model by 4.4% in terms of CTR.
Curriculum Offline Imitation Learning
Nov 03, 2021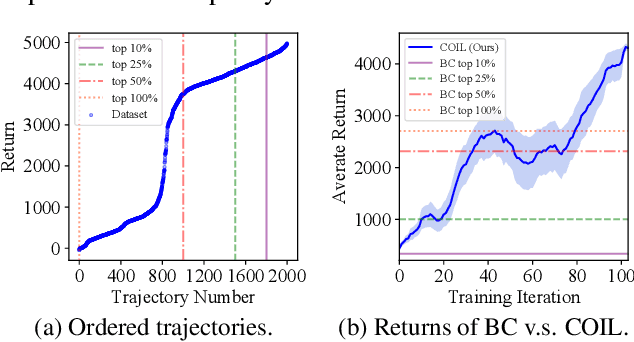
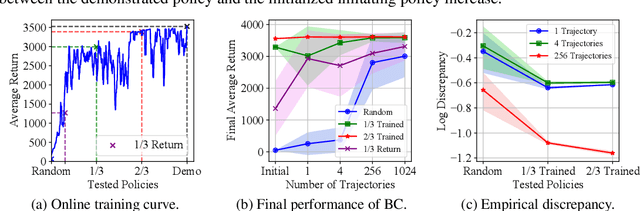
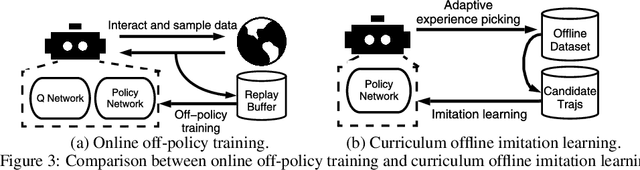

Offline reinforcement learning (RL) tasks require the agent to learn from a pre-collected dataset with no further interactions with the environment. Despite the potential to surpass the behavioral policies, RL-based methods are generally impractical due to the training instability and bootstrapping the extrapolation errors, which always require careful hyperparameter tuning via online evaluation. In contrast, offline imitation learning (IL) has no such issues since it learns the policy directly without estimating the value function by bootstrapping. However, IL is usually limited in the capability of the behavioral policy and tends to learn a mediocre behavior from the dataset collected by the mixture of policies. In this paper, we aim to take advantage of IL but mitigate such a drawback. Observing that behavior cloning is able to imitate neighboring policies with less data, we propose \textit{Curriculum Offline Imitation Learning (COIL)}, which utilizes an experience picking strategy for imitating from adaptive neighboring policies with a higher return, and improves the current policy along curriculum stages. On continuous control benchmarks, we compare COIL against both imitation-based and RL-based methods, showing that it not only avoids just learning a mediocre behavior on mixed datasets but is also even competitive with state-of-the-art offline RL methods.
Context-aware Reranking with Utility Maximization for Recommendation
Oct 18, 2021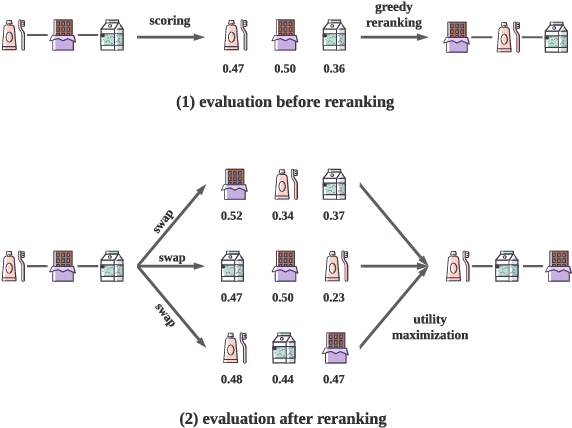
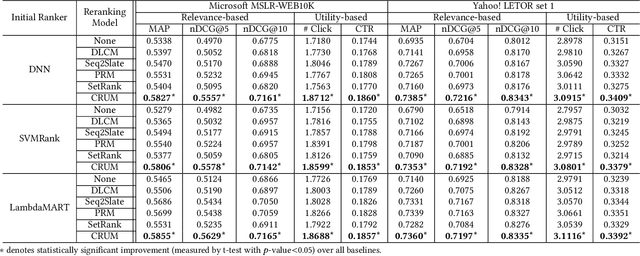
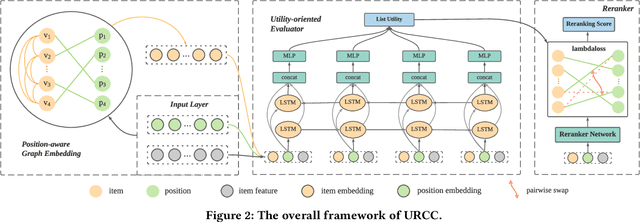
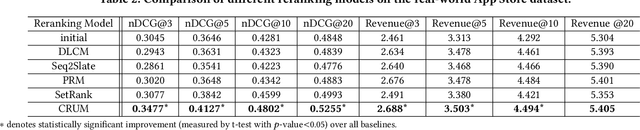
As a critical task for large-scale commercial recommender systems, reranking has shown the potential of improving recommendation results by uncovering mutual influence among items. Reranking rearranges items in the initial ranking lists from the previous ranking stage to better meet users' demands. However, rather than considering the context of initial lists as most existing methods do, an ideal reranking algorithm should consider the counterfactual context -- the position and the alignment of the items in the reranked lists. In this work, we propose a novel pairwise reranking framework, Context-aware Reranking with Utility Maximization for recommendation (CRUM), which maximizes the overall utility after reranking efficiently. Specifically, we first design a utility-oriented evaluator, which applies Bi-LSTM and graph attention mechanism to estimate the listwise utility via the counterfactual context modeling. Then, under the guidance of the evaluator, we propose a pairwise reranker model to find the most suitable position for each item by swapping misplaced item pairs. Extensive experiments on two benchmark datasets and a proprietary real-world dataset demonstrate that CRUM significantly outperforms the state-of-the-art models in terms of both relevance-based metrics and utility-based metrics.
Why Propagate Alone? Parallel Use of Labels and Features on Graphs
Oct 14, 2021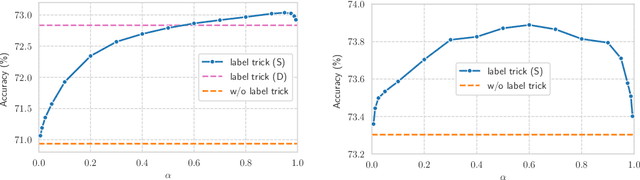



Graph neural networks (GNNs) and label propagation represent two interrelated modeling strategies designed to exploit graph structure in tasks such as node property prediction. The former is typically based on stacked message-passing layers that share neighborhood information to transform node features into predictive embeddings. In contrast, the latter involves spreading label information to unlabeled nodes via a parameter-free diffusion process, but operates independently of the node features. Given then that the material difference is merely whether features or labels are smoothed across the graph, it is natural to consider combinations of the two for improving performance. In this regard, it has recently been proposed to use a randomly-selected portion of the training labels as GNN inputs, concatenated with the original node features for making predictions on the remaining labels. This so-called label trick accommodates the parallel use of features and labels, and is foundational to many of the top-ranking submissions on the Open Graph Benchmark (OGB) leaderboard. And yet despite its wide-spread adoption, thus far there has been little attempt to carefully unpack exactly what statistical properties the label trick introduces into the training pipeline, intended or otherwise. To this end, we prove that under certain simplifying assumptions, the stochastic label trick can be reduced to an interpretable, deterministic training objective composed of two factors. The first is a data-fitting term that naturally resolves potential label leakage issues, while the second serves as a regularization factor conditioned on graph structure that adapts to graph size and connectivity. Later, we leverage this perspective to motivate a broader range of label trick use cases, and provide experiments to verify the efficacy of these extensions.