 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALo: Learning Posture-Aware Locomotion for Quadruped Robots
Mar 06, 2025



With the rapid development of embodied intelligence, locomotion control of quadruped robots on complex terrains has become a research hotspot. Unlike traditional locomotion control approaches focusing solely on velocity tracking, we pursue to balance the agility and robustness of quadruped robots on diverse and complex terrains. To this end, we propose an end-to-end deep reinforcement learning framework for posture-aware locomotion named PALo, which manages to handle simultaneous linear and angular velocity tracking and real-time adjustments of body height, pitch, and roll angles. In PALo, the locomotion control problem is formulated as a partially observable Markov decision process, and an asymmetric actor-critic architecture is adopted to overcome the sim-to-real challenge. Further, by incorporating customized training curricula, PALo achieves agile posture-aware locomotion control in simulated environments and successfully transfers to real-world settings without fine-tuning, allowing real-time control of the quadruped robot's locomotion and body posture across challenging terrains. Through in-depth experimental analysis, we identify the key components of PALo that contribute to its performance, further validating the effectiveness of the proposed method. The results of this study provide new possibilities for the low-level locomotion control of quadruped robots in higher dimensional command spaces and lay the foundation for future research on upper-level modules for embodied intelligence.
LoopSR: Looping Sim-and-Real for Lifelong Policy Adaptation of Legged Robots
Sep 26, 2024Reinforcement Learning (RL) has shown its remarkable and generalizable capability in legged locomotion through sim-to-real transfer. However, while adaptive methods like domain randomization are expected to make policy more robust to diverse environments, such comprehensiveness potentially detracts from the policy's performance in any specific environment according to the No Free Lunch theorem, leading to a suboptimal solution once deployed in the real world. To address this issue, we propose a lifelong policy adaptation framework named LoopSR, which utilizes a transformer-based encoder to project real-world trajectories into a latent space, and accordingly reconstruct the real-world environments back in simulation for further improvement. Autoencoder architecture and contrastive learning methods are adopted to better extract the characteristics of real-world dynamics. The simulation parameters for continual training are derived by combining predicted parameters from the decoder with retrieved parameters from the simulation trajectory dataset. By leveraging the continual training, LoopSR achieves superior data efficiency compared with strong baselines, with only a limited amount of data to yield eminent performance in both sim-to-sim and sim-to-real experiments.
World Model-based Perception for Visual Legged Locomotion
Sep 25, 2024



Legged locomotion over various terrains is challenging and requires precise perception of the robot and its surroundings from both proprioception and vision. However, learning directly from high-dimensional visual input is often data-inefficient and intricate. To address this issue, traditional methods attempt to learn a teacher policy with access to privileged information first and then learn a student policy to imitate the teacher's behavior with visual input. Despite some progress, this imitation framework prevents the student policy from achieving optimal performance due to the information gap between inputs. Furthermore, the learning process is unnatural since animals intuitively learn to traverse different terrains based on their understanding of the world without privileged knowledge. Inspired by this natural ability, we propose a simple yet effective method, World Model-based Perception (WMP), which builds a world model of the environment and learns a policy based on the world model. We illustrate that though completely trained in simulation, the world model can make accurate predictions of real-world trajectories, thus providing informative signals for the policy controller. Extensive simulated and real-world experiments demonstrate that WMP outperforms state-of-the-art baselines in traversability and robustness. Videos and Code are available at: https://wmp-loco.github.io/.
Adaptive Control Strategy for Quadruped Robots in Actuator Degradation Scenarios
Dec 29, 2023



Quadruped robots have strong adaptability to extreme environments but may also experience faults. Once these faults occur, robots must be repaired before returning to the task, reducing their practical feasibility. One prevalent concern among these faults is actuator degradation, stemming from factors like device aging or unexpected operational events. Traditionally, addressing this problem has relied heavily on intricate fault-tolerant design, which demands deep domain expertise from developers and lacks generalizability. Learning-based approaches offer effective ways to mitigate these limitations, but a research gap exists in effectively deploying such methods on real-world quadruped robots. This paper introduces a pioneering teacher-student framework rooted in reinforcement learning, named Actuator Degradation Adaptation Transformer (ADAPT), aimed at addressing this research gap. This framework produces a unified control strategy, enabling the robot to sustain its locomotion and perform tasks despite sudden joint actuator faults, relying exclusively on its internal sensors. Empirical evaluations on the Unitree A1 platform validate the deployability and effectiveness of Adapt on real-world quadruped robots, and affirm the robustness and practicality of our approach.
Privileged Knowledge Distillation for Sim-to-Real Policy Generalization
May 29, 2023



Reinforcement Learning (RL) has recently achieved remarkable success in robotic control. However, most RL methods operate in simulated environments where privileged knowledge (e.g., dynamics, surroundings, terrains) is readily available. Conversely, in real-world scenarios, robot agents usually rely solely on local states (e.g., proprioceptive feedback of robot joints) to select actions, leading to a significant sim-to-real gap. Existing methods address this gap by either gradually reducing the reliance on privileged knowledge or performing a two-stage policy imitation. However, we argue that these methods are limited in their ability to fully leverage the privileged knowledge, resulting in suboptimal performance. In this paper, we propose a novel single-stage privileged knowledge distillation method called the Historical Information Bottleneck (HIB) to narrow the sim-to-real gap. In particular, HIB learns a privileged knowledge representation from historical trajectories by capturing the underlying changeable dynamic information. Theoretical analysis shows that the learned privileged knowledge representation helps reduce the value discrepancy between the oracle and learned policies. Empirical experiments on both simulated and real-world tasks demonstrate that HIB yields improved generalizability compared to previous methods.
Multi-embodiment Legged Robot Control as a Sequence Modeling Problem
Dec 18, 2022



Robots are traditionally bounded by a fixed embodiment during their operational lifetime, which limits their ability to adapt to their surroundings. Co-optimizing control and morphology of a robot, however, is often inefficient due to the complex interplay between the controller and morphology. In this paper, we propose a learning-based control method that can inherently take morphology into consideration such that once the control policy is trained in the simulator, it can be easily deployed to robots with different embodiments in the real world. In particular, we present the Embodiment-aware Transformer (EAT), an architecture that casts this control problem as conditional sequence modeling. EAT outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired robot embodiment, past states, and actions, our EAT model can generate future actions that best fit the current robot embodiment. Experimental results show that EAT can outperform all other alternatives in embodiment-varying tasks, and succeed in an example of real-world evolution tasks: stepping down a stair through updating the morphology alone. We hope that EAT will inspire a new push toward real-world evolution across many domains, where algorithms like EAT can blaze a trail by bridging the field of evolutionary robotics and big data sequence modeling.
Sim-to-Real Transfer for Quadrupedal Locomotion via Terrain Transformer
Dec 15, 2022Deep reinforcement learning has recently emerged as an appealing alternative for legged locomotion over multiple terrains by training a policy in physical simulation and then transferring it to the real world (i.e., sim-to-real transfer). Despite considerable progress, the capacity and scalability of traditional neural networks are still limited, which may hinder their applications in more complex environments. In contrast, the Transformer architecture has shown its superiority in a wide range of large-scale sequence modeling tasks, including natural language processing and decision-making problems. In this paper, we propose Terrain Transformer (TERT), a high-capacity Transformer model for quadrupedal locomotion control on various terrains. Furthermore, to better leverage Transformer in sim-to-real scenarios, we present a novel two-stage training framework consisting of an offline pretraining stage and an online correction stage, which can naturally integrate Transformer with privileged training. Extensive experiments in simulation demonstrate that TERT outperforms state-of-the-art baselines on different terrains in terms of return, energy consumption and control smoothness. In further real-world validation, TERT successfully traverses nine challenging terrains, including sand pit and stair down, which can not be accomplished by strong baselines.
A Survey on Model-based Reinforcement Learning
Jun 19, 2022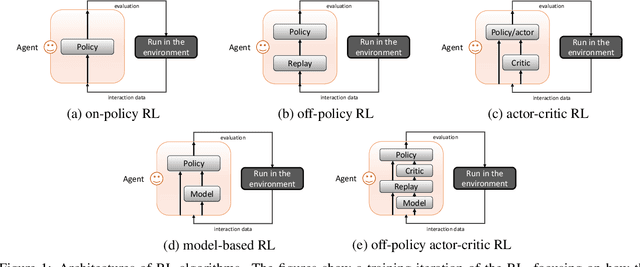
Reinforcement learning (RL) solves sequential decision-making problems via a trial-and-error process interacting with the environment. While RL achieves outstanding success in playing complex video games that allow huge trial-and-error, making errors is always undesired in the real world. To improve the sample efficiency and thus reduce the errors, model-based reinforcement learning (MBRL) is believed to be a promising direction, which builds environment models in which the trial-and-errors can take place without real costs. In this survey, we take a review of MBRL with a focus on the recent progress in deep RL. For non-tabular environments, there is always a generalization error between the learned environment model and the real environment. As such, it is of great importance to analyze the discrepancy between policy training in the environment model and that in the real environment, which in turn guides the algorithm design for better model learning, model usage, and policy training. Besides, we also discuss the recent advances of model-based techniques in other forms of RL, including offline RL, goal-conditioned RL, multi-agent RL, and meta-RL. Moreover, we discuss the applicability and advantages of MBRL in real-world tasks. Finally, we end this survey by discussing the promising prospects for the future development of MBRL. We think that MBRL has great potential and advantages in real-world applications that were overlooked, and we hope this survey could attract more research on MBRL.
On Effective Scheduling of Model-based Reinforcement Learning
Nov 16, 2021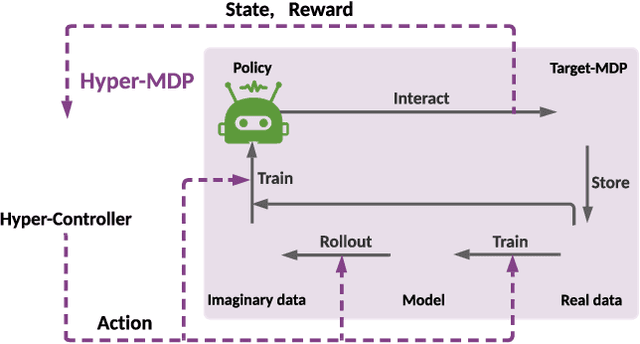
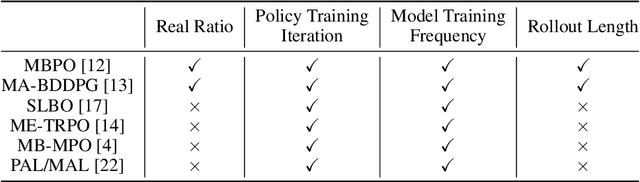
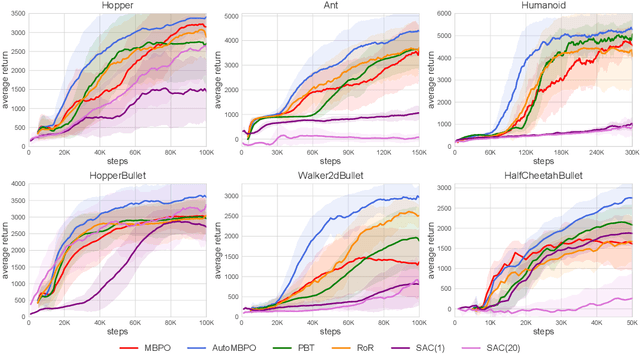

Model-based reinforcement learning has attracted wide attention due to its superior sample efficiency. Despite its impressive success so far, it is still unclear how to appropriately schedule the important hyperparameters to achieve adequate performance, such as the real data ratio for policy optimization in Dyna-style model-based algorithms. In this paper, we first theoretically analyze the role of real data in policy training, which suggests that gradually increasing the ratio of real data yields better performance. Inspired by the analysis, we propose a framework named AutoMBPO to automatically schedule the real data ratio as well as other hyperparameters in training model-based policy optimization (MBPO) algorithm, a representative running case of model-based methods. On several continuous control tasks, the MBPO instance trained with hyperparameters scheduled by AutoMBPO can significantly surpass the original one, and the real data ratio schedule found by AutoMBPO shows consistency with our theoretical analysis.
Bidirectional Model-based Policy Optimization
Jul 04, 2020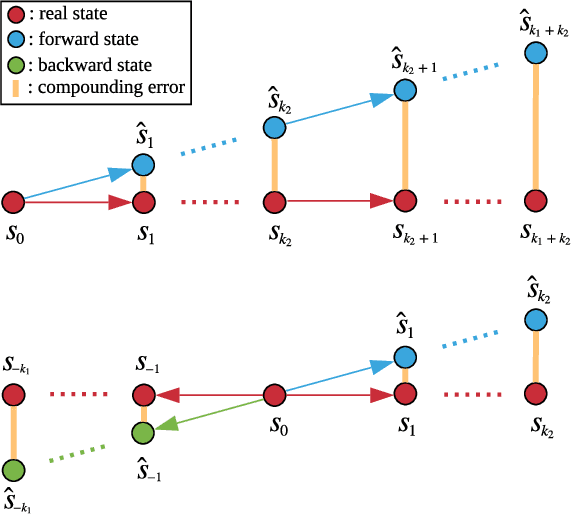

Model-based reinforcement learning approaches leverage a forward dynamics model to support planning and decision making, which, however, may fail catastrophically if the model is inaccurate. Although there are several existing methods dedicated to combating the model error, the potential of the single forward model is still limited. In this paper, we propose to additionally construct a backward dynamics model to reduce the reliance on accuracy in forward model predictions. We develop a novel method, called Bidirectional Model-based Policy Optimization (BMPO) to utilize both the forward model and backward model to generate short branched rollouts for policy optimization. Furthermore, we theoretically derive a tighter bound of return discrepancy, which shows the superiority of BMPO against the one using merely the forward model. Extensive experiments demonstrate that BMPO outperforms state-of-the-art model-based methods in terms of sample efficiency and asymptotic performance.