 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Wang
Joint Sensing and Communication Optimization in Target-Mounted STARS-Assisted Vehicular Networks: A MADRL Approach
Nov 17, 2023
The utilization of integrated sensing and communication (ISAC) technology has the potential to enhance the communication performance of road side units (RSUs) through the active sensing of target vehicles. Furthermore, installing a simultaneous transmitting and reflecting surface (STARS) on the target vehicle can provide an extra boost to the reflection of the echo signal, thereby improving the communication quality for in-vehicle users. However, the design of this target-mounted STARS system exhibits significant challenges, such as limited information sharing and distributed STARS control. In this paper, we propose an end-to-end multi-agent deep reinforcement learning (MADRL) framework to tackle the challenges of joint sensing and communication optimization in the considered target-mounted STARS assisted vehicle networks. By deploying agents on both RSU and vehicle, the MADRL framework enables RSU and vehicle to perform beam prediction and STARS pre-configuration using their respective local information. To ensure efficient and stable learning for continuous decision-making, we employ the multi-agent soft actor critic (MASAC) algorithm and the multi-agent proximal policy optimization (MAPPO) algorithm on the proposed MADRL framework. Extensive experimental results confirm the effectiveness of our proposed MADRL framework in improving both sensing and communication performance through the utilization of target-mounted STARS. Finally, we conduct a comparative analysis and comparison of the two proposed algorithms under various environmental conditions.
From Scroll to Misbelief: Modeling the Unobservable Susceptibility to Misinformation on Social Media
Nov 16, 2023Susceptibility to misinformation describes the extent to believe unverifiable claims, which is hidden in people's mental process and infeasible to observe. Existing susceptibility studies heavily rely on the self-reported beliefs, making any downstream applications on susceptability hard to scale. To address these limitations, in this work, we propose a computational model to infer users' susceptibility levels given their activities. Since user's susceptibility is a key indicator for their reposting behavior, we utilize the supervision from the observable sharing behavior to infer the underlying susceptibility tendency. The evaluation shows that our model yields estimations that are highly aligned with human judgment on users' susceptibility level comparisons. Building upon such large-scale susceptibility labeling, we further conduct a comprehensive analysis of how different social factors relate to susceptibility. We find that political leanings and psychological factors are associated with susceptibility in varying degrees.
FollowBench: A Multi-level Fine-grained Constraints Following Benchmark for Large Language Models
Nov 14, 2023
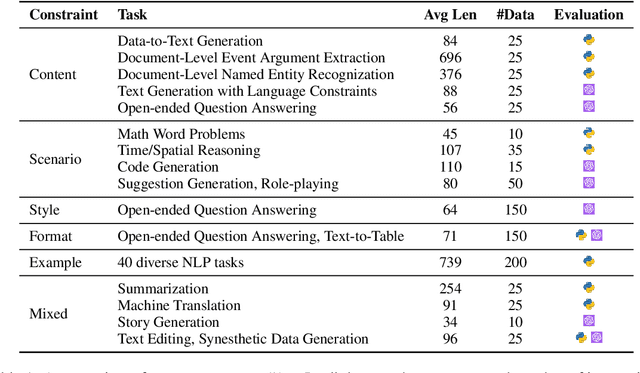
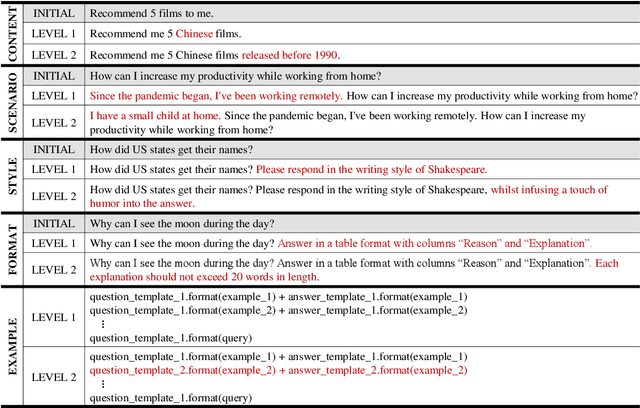
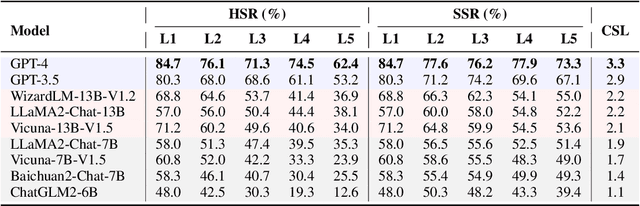
The ability to follow instructions is crucial for Large Language Models (LLMs) to handle various real-world applications. Existing benchmarks primarily focus on evaluating pure response quality, rather than assessing whether the response follows constraints stated in the instruction. To fill this research gap, in this paper, we propose FollowBench, a Multi-level Fine-grained Constraints Following Benchmark for LLMs. FollowBench comprehensively includes five different types (i.e., Content, Situation, Style, Format, and Example) of fine-grained constraints. To enable a precise constraint following estimation on diverse difficulties, we introduce a Multi-level mechanism that incrementally adds a single constraint to the initial instruction at each increased level. To assess whether LLMs' outputs have satisfied every individual constraint, we propose to prompt strong LLMs with constraint-evolution paths to handle challenging open-ended instructions. By evaluating ten closed-source and open-source popular LLMs on FollowBench, we highlight the weaknesses of LLMs in instruction following and point towards potential avenues for future work. The data and code are publicly available at https://github.com/YJiangcm/FollowBench.
Enhancing Few-shot CLIP with Semantic-Aware Fine-Tuning
Nov 09, 2023Learning generalized representations from limited training samples is crucial for applying deep neural networks in low-resource scenarios. Recently, methods based on Contrastive Language-Image Pre-training (CLIP) have exhibited promising performance in few-shot adaptation tasks. To avoid catastrophic forgetting and overfitting caused by few-shot fine-tuning, existing works usually freeze the parameters of CLIP pre-trained on large-scale datasets, overlooking the possibility that some parameters might not be suitable for downstream tasks. To this end, we revisit CLIP's visual encoder with a specific focus on its distinctive attention pooling layer, which performs a spatial weighted-sum of the dense feature maps. Given that dense feature maps contain meaningful semantic information, and different semantics hold varying importance for diverse downstream tasks (such as prioritizing semantics like ears and eyes in pet classification tasks rather than side mirrors), using the same weighted-sum operation for dense features across different few-shot tasks might not be appropriate. Hence, we propose fine-tuning the parameters of the attention pooling layer during the training process to encourage the model to focus on task-specific semantics. In the inference process, we perform residual blending between the features pooled by the fine-tuned and the original attention pooling layers to incorporate both the few-shot knowledge and the pre-trained CLIP's prior knowledge. We term this method as Semantic-Aware FinE-tuning (SAFE). SAFE is effective in enhancing the conventional few-shot CLIP and is compatible with the existing adapter approach (termed SAFE-A).
Robust Best-arm Identification in Linear Bandits
Nov 08, 2023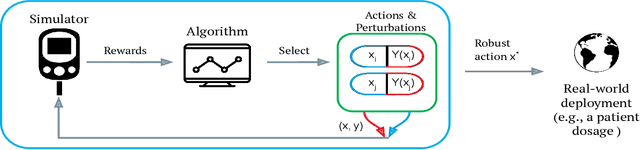

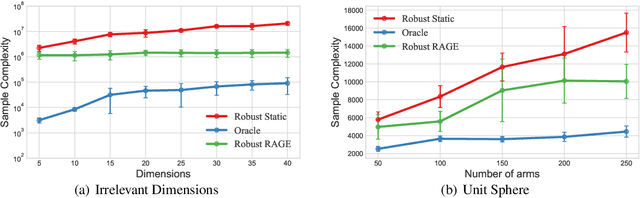

We study the robust best-arm identification problem (RBAI) in the case of linear rewards. The primary objective is to identify a near-optimal robust arm, which involves selecting arms at every round and assessing their robustness by exploring potential adversarial actions. This approach is particularly relevant when utilizing a simulator and seeking to identify a robust solution for real-world transfer. To this end, we present an instance-dependent lower bound for the robust best-arm identification problem with linear rewards. Furthermore, we propose both static and adaptive bandit algorithms that achieve sample complexity that matches the lower bound. In synthetic experiments, our algorithms effectively identify the best robust arm and perform similarly to the oracle strategy. As an application, we examine diabetes care and the process of learning insulin dose recommendations that are robust with respect to inaccuracies in standard calculators. Our algorithms prove to be effective in identifying robust dosage values across various age ranges of patients.
An efficient tangent based topologically distinctive path finding for grid maps
Nov 01, 2023
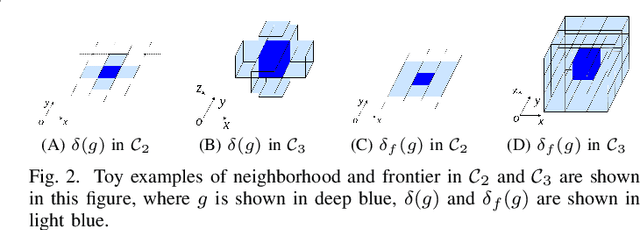
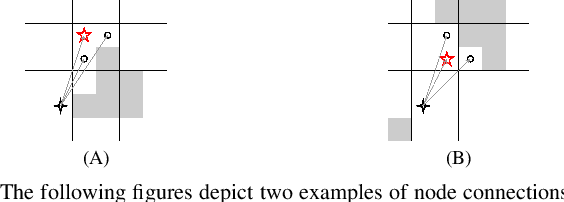
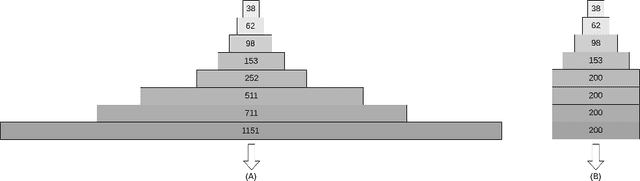
Conventional local planners frequently become trapped in a locally optimal trajectory, primarily due to their inability to traverse obstacles. Having a larger number of topologically distinctive paths increases the likelihood of finding the optimal trajectory. It is crucial to generate a substantial number of topologically distinctive paths in real-time. Accordingly, we propose an efficient path planning approach based on tangent graphs to yield multiple topologically distinctive paths. Diverging from existing algorithms, our method eliminates the necessity of distinguishing whether two paths belong to the same topology; instead, it generates multiple topologically distinctive paths based on the locally shortest property of tangents. Additionally, we introduce a priority constraint for the queue during graph search, thereby averting the exponential expansion of queue size. To illustrate the advantages of our method, we conducted a comparative analysis with various typical algorithms using a widely recognized public dataset\footnote{https://movingai.com/benchmarks/grids.html}. The results indicate that, on average, our method generates 320 topologically distinctive paths within a mere 100 milliseconds. This outcome underscores a significant enhancement in efficiency when compared to existing methods. To foster further research within the community, we have made the source code of our proposed algorithm publicly accessible\footnote{https://joeyao-bit.github.io/posts/2023/09/07/}. We anticipate that this framework will significantly contribute to the development of more efficient topologically distinctive path planning, along with related trajectory optimization and motion planning endeavors.
Zero-Shot Medical Information Retrieval via Knowledge Graph Embedding
Oct 31, 2023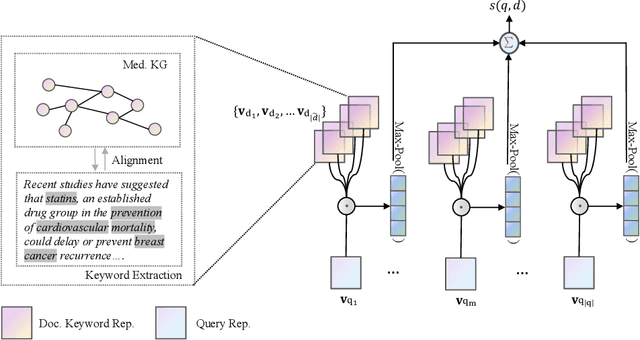
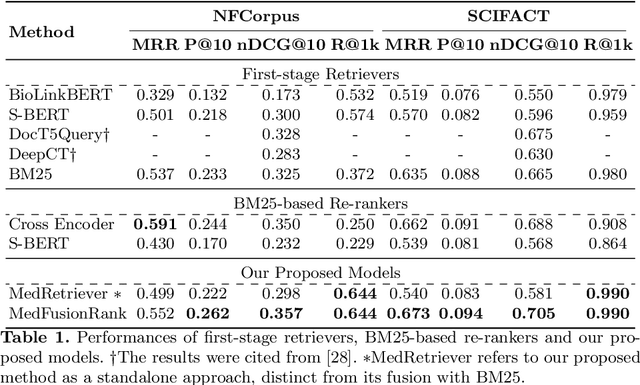

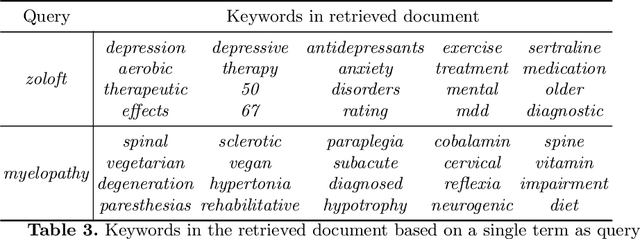
In the era of the Internet of Things (IoT), the retrieval of relevant medical information has become essential for efficient clinical decision-making. This paper introduces MedFusionRank, a novel approach to zero-shot medical information retrieval (MIR) that combines the strengths of pre-trained language models and statistical methods while addressing their limitations. The proposed approach leverages a pre-trained BERT-style model to extract compact yet informative keywords. These keywords are then enriched with domain knowledge by linking them to conceptual entities within a medical knowledge graph. Experimental evaluations on medical datasets demonstrate MedFusion Rank's superior performance over existing methods, with promising results with a variety of evaluation metrics. MedFusionRank demonstrates efficacy in retrieving relevant information, even from short or single-term queries.
Boosting Decision-Based Black-Box Adversarial Attack with Gradient Priors
Oct 29, 2023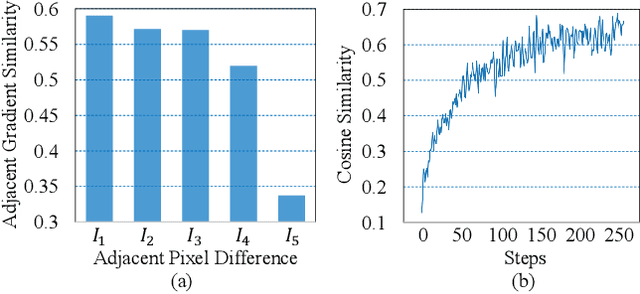
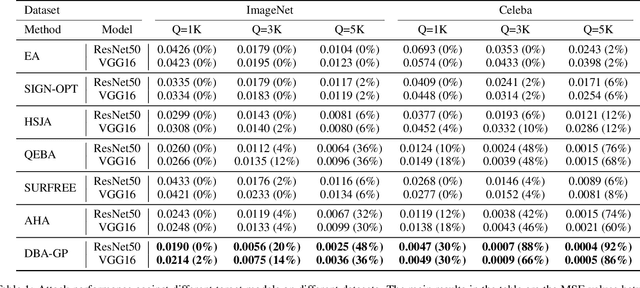
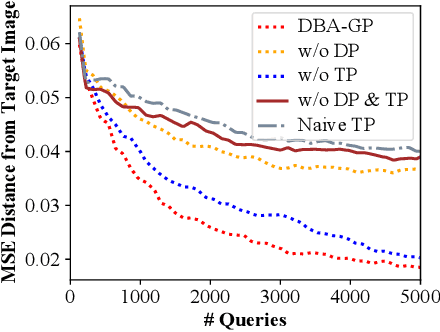
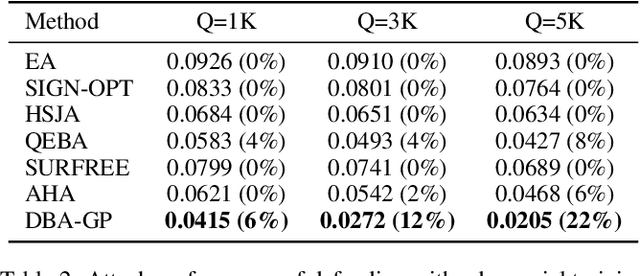
Decision-based methods have shown to be effective in black-box adversarial attacks, as they can obtain satisfactory performance and only require to access the final model prediction. Gradient estimation is a critical step in black-box adversarial attacks, as it will directly affect the query efficiency. Recent works have attempted to utilize gradient priors to facilitate score-based methods to obtain better results. However, these gradient priors still suffer from the edge gradient discrepancy issue and the successive iteration gradient direction issue, thus are difficult to simply extend to decision-based methods. In this paper, we propose a novel Decision-based Black-box Attack framework with Gradient Priors (DBA-GP), which seamlessly integrates the data-dependent gradient prior and time-dependent prior into the gradient estimation procedure. First, by leveraging the joint bilateral filter to deal with each random perturbation, DBA-GP can guarantee that the generated perturbations in edge locations are hardly smoothed, i.e., alleviating the edge gradient discrepancy, thus remaining the characteristics of the original image as much as possible. Second, by utilizing a new gradient updating strategy to automatically adjust the successive iteration gradient direction, DBA-GP can accelerate the convergence speed, thus improving the query efficiency. Extensive experiments have demonstrated that the proposed method outperforms other strong baselines significantly.