 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhys-3D: Physics-Constrained Real-Time Crowd Tracking and Counting on Railway Platforms
Feb 26, 2026Accurate, real-time crowd counting on railway platforms is essential for safety and capacity management. We propose to use a single camera mounted in a train, scanning the platform while arriving. While hardware constraints are simple, counting remains challenging due to dense occlusions, camera motion, and perspective distortions during train arrivals. Most existing tracking-by-detection approaches assume static cameras or ignore physical consistency in motion modeling, leading to unreliable counting under dynamic conditions. We propose a physics-constrained tracking framework that unifies detection, appearance, and 3D motion reasoning in a real-time pipeline. Our approach integrates a transfer-learned YOLOv11m detector with EfficientNet-B0 appearance encoding within DeepSORT, while introducing a physics-constrained Kalman model (Phys-3D) that enforces physically plausible 3D motion dynamics through pinhole geometry. To address counting brittleness under occlusions, we implement a virtual counting band with persistence. On our platform benchmark, MOT-RailwayPlatformCrowdHead Dataset(MOT-RPCH), our method reduces counting error to 2.97%, demonstrating robust performance despite motion and occlusions. Our results show that incorporating first-principles geometry and motion priors enables reliable crowd counting in safety-critical transportation scenarios, facilitating effective train scheduling and platform safety management.
* published at VISAPP 2026
GLASS: A Generative Recommender for Long-sequence Modeling via SID-Tier and Semantic Search
Feb 05, 2026Leveraging long-term user behavioral patterns is a key trajectory for enhancing the accuracy of modern recommender systems. While generative recommender systems have emerged as a transformative paradigm, they face hurdles in effectively modeling extensive historical sequences. To address this challenge, we propose GLASS, a novel framework that integrates long-term user interests into the generative process via SID-Tier and Semantic Search. We first introduce SID-Tier, a module that maps long-term interactions into a unified interest vector to enhance the prediction of the initial SID token. Unlike traditional retrieval models that struggle with massive item spaces, SID-Tier leverages the compact nature of the semantic codebook to incorporate cross features between the user's long-term history and candidate semantic codes. Furthermore, we present semantic hard search, which utilizes generated coarse-grained semantic ID as dynamic keys to extract relevant historical behaviors, which are then fused via an adaptive gated fusion module to recalibrate the trajectory of subsequent fine-grained tokens. To address the inherent data sparsity in semantic hard search, we propose two strategies: semantic neighbor augmentation and codebook resizing. Extensive experiments on two large-scale real-world datasets, TAOBAO-MM and KuaiRec, demonstrate that GLASS outperforms state-of-the-art baselines, achieving significant gains in recommendation quality. Our codes are made publicly available to facilitate further research in generative recommendation.
Did Models Sufficient Learn? Attribution-Guided Training via Subset-Selected Counterfactual Augmentation
Nov 15, 2025In current visual model training, models often rely on only limited sufficient causes for their predictions, which makes them sensitive to distribution shifts or the absence of key features. Attribution methods can accurately identify a model's critical regions. However, masking these areas to create counterfactuals often causes the model to misclassify the target, while humans can still easily recognize it. This divergence highlights that the model's learned dependencies may not be sufficiently causal. To address this issue, we propose Subset-Selected Counterfactual Augmentation (SS-CA), which integrates counterfactual explanations directly into the training process for targeted intervention. Building on the subset-selection-based LIMA attribution method, we develop Counterfactual LIMA to identify minimal spatial region sets whose removal can selectively alter model predictions. Leveraging these attributions, we introduce a data augmentation strategy that replaces the identified regions with natural background, and we train the model jointly on both augmented and original samples to mitigate incomplete causal learning. Extensive experiments across multiple ImageNet variants show that SS-CA improves generalization on in-distribution (ID) test data and achieves superior performance on out-of-distribution (OOD) benchmarks such as ImageNet-R and ImageNet-S. Under perturbations including noise, models trained with SS-CA also exhibit enhanced generalization, demonstrating that our approach effectively uses interpretability insights to correct model deficiencies and improve both performance and robustness.
RECAP: Reproducing Copyrighted Data from LLMs Training with an Agentic Pipeline
Oct 29, 2025If we cannot inspect the training data of a large language model (LLM), how can we ever know what it has seen? We believe the most compelling evidence arises when the model itself freely reproduces the target content. As such, we propose RECAP, an agentic pipeline designed to elicit and verify memorized training data from LLM outputs. At the heart of RECAP is a feedback-driven loop, where an initial extraction attempt is evaluated by a secondary language model, which compares the output against a reference passage and identifies discrepancies. These are then translated into minimal correction hints, which are fed back into the target model to guide subsequent generations. In addition, to address alignment-induced refusals, RECAP includes a jailbreaking module that detects and overcomes such barriers. We evaluate RECAP on EchoTrace, a new benchmark spanning over 30 full books, and the results show that RECAP leads to substantial gains over single-iteration approaches. For instance, with GPT-4.1, the average ROUGE-L score for the copyrighted text extraction improved from 0.38 to 0.47 - a nearly 24% increase.
Modeling e-Learners' Cognitive and Metacognitive Strategy in Comparative Question Solving
Jun 04, 2019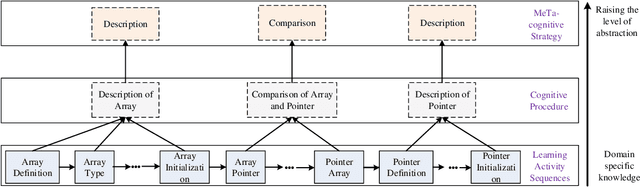
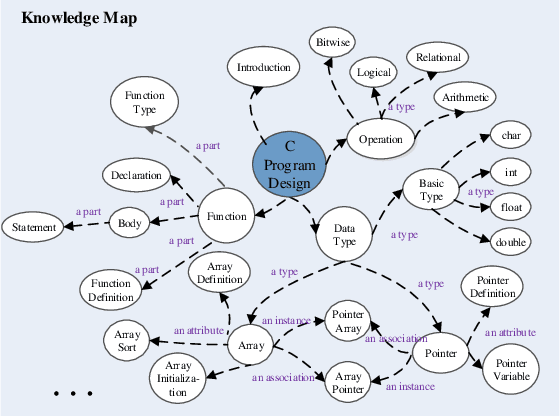
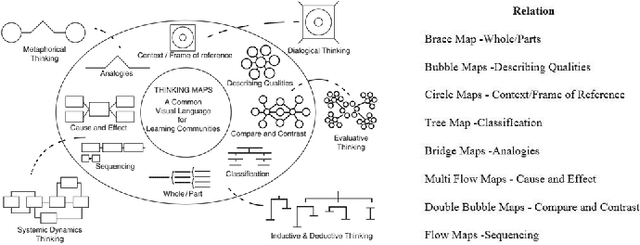
Cognitive and metacognitive strategy had demonstrated a significant role in self-regulated learning (SRL), and an appropriate use of strategies is beneficial to effective learning or question-solving tasks during a human-computer interaction process. This paper proposes a novel method combining Knowledge Map (KM) based data mining technique with Thinking Map (TM) to detect learner's cognitive and metacognitive strategy in the question-solving scenario. In particular, a graph-based mining algorithm is designed to facilitate our proposed method, which can automatically map cognitive strategy to metacognitive strategy with raising abstraction level, and make the cognitive and metacognitive process viewable, which acts like a reverse engineering engine to explain how a learner thinks when solving a question. Additionally, we develop an online learning environment system for participants to learn and record their behaviors. To corroborate the effectiveness of our approach and algorithm, we conduct experiments recruiting 173 postgraduate and undergraduate students, and they were asked to complete a question-solving task, such as "What are similarities and differences between array and pointer?" from "The C Programming Language" course and "What are similarities and differences between packet switching and circuit switching?" from "Computer Network Principle" course. The mined strategies patterns results are encouraging and supported well our proposed method.