 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAR: Text Semantic Assisted Cross-modal Image Registration Framework for Optical and SAR Images
May 12, 2026Existing deep learning-based methods can capture shared features from optical and synthetic aperture radar (SAR) images for spatial alignment. However, optical-SAR registration remains challenging under large geometric deformations, because the model needs to simultaneously handle cross-modal appearance discrepancies and complex spatial transformations. To address this issue, this paper proposes a text semantic-assisted cross-modal image registration framework, named TAR, for optical and SAR images. TAR exploits text semantic priors from remote sensing scenes and land-cover categories to alleviate the modality gap and enhance cross-modal feature learning. TAR consists of three components: a multi-scale visual feature learning (MSFL) module, a text-assisted feature enhancement (TAFE) module, and a coarse-to-fine dense matching (CFDM) module. MSFL extracts multi-scale visual features from optical and SAR images. TAFE constructs text descriptors related to remote sensing scenes and land-cover objects, and uses a frozen RemoteCLIP text encoder to extract text features. These text features are introduced through visual-text interaction to enhance high-level visual features for more reliable coarse matching. CFDM then establishes coarse correspondences based on the enhanced high-level features and refines the matched locations using low-level features. Experimental results on cross-modal remote sensing images demonstrate the effectiveness of TAR, which achieves stronger matching performance than several state-of-the-art methods and yields significant gains under large geometric deformations.
BGG: Bridging the Geometric Gap between Cross-View images by Vision Foundation Model Adaptation for Geo-Localization
May 11, 2026Geometric differences between cross-view images, such as drone and satellite views, significantly increase the challenge of Cross-View Geo-Localization (CVGL), which aims to acquire the geolocation of images by image retrieval. To further enhance the CVGL performance, this paper proposes a parameter-efficient adaptation framework for bridging the geometric gap across images based on the vision foundation model (VFM) (e.g., DINOv3), termed BGG. BGG not only effectively leverages the general visual representations of VFM and captures the robust and consistent features from cross-view images, but also utilizes the generalization capabilities of the VFM, significantly improving the CVGL performance. It mainly contains a Multi-granularity Feature Enhancement Adapter (MFEA) and a Frequency-Aware Structural Aggregation (FASA) module. Specifically, MFEA enhances the scale adaptability and viewpoint robustness of features by multi-level dilated convolutions, effectively bridging the cross-view geometric gap with small training costs. Additionally, considering the [CLS] token lacks spatial details for precise image retrieval and localization, the FASA module modulates patch tokens in the frequency domain and performs adaptive aggregation for local structural feature enhancement. Finally, BGG fuses the enhanced local features with the [CLS] token for more accurate CVGL. Extensive experiments on University-1652 and SUES-200 datasets demonstrate that BGG has significant advantages over other methods and achieves state-of-the-art localization performance with low training costs.
Generalizable Knowledge Distillation from Vision Foundation Models for Semantic Segmentation
Mar 03, 2026Knowledge distillation (KD) has been widely applied in semantic segmentation to compress large models, but conventional approaches primarily preserve in-domain accuracy while neglecting out-of-domain generalization, which is essential under distribution shifts. This limitation becomes more severe with the emergence of vision foundation models (VFMs): although VFMs exhibit strong robustness on unseen data, distilling them with conventional KD often compromises this ability. We propose Generalizable Knowledge Distillation (GKD), a multi-stage framework that explicitly enhances generalization. GKD decouples representation learning from task learning. In the first stage, the student acquires domain-agnostic representations through selective feature distillation, and in the second stage, these representations are frozen for task adaptation, thereby mitigating overfitting to visible domains. To further support transfer, we introduce a query-based soft distillation mechanism, where student features act as queries to teacher representations to selectively retrieve transferable spatial knowledge from VFMs. Extensive experiments on five domain generalization benchmarks demonstrate that GKD consistently outperforms existing KD methods, achieving average gains of +1.9% in foundation-to-foundation (F2F) and +10.6% in foundation-to-local (F2L) distillation. The code will be available at https://github.com/Younger-hua/GKD.
CLNet: Cross-View Correspondence Makes a Stronger Geo-Localizationer
Dec 16, 2025Image retrieval-based cross-view geo-localization (IRCVGL) aims to match images captured from significantly different viewpoints, such as satellite and street-level images. Existing methods predominantly rely on learning robust global representations or implicit feature alignment, which often fail to model explicit spatial correspondences crucial for accurate localization. In this work, we propose a novel correspondence-aware feature refinement framework, termed CLNet, that explicitly bridges the semantic and geometric gaps between different views. CLNet decomposes the view alignment process into three learnable and complementary modules: a Neural Correspondence Map (NCM) that spatially aligns cross-view features via latent correspondence fields; a Nonlinear Embedding Converter (NEC) that remaps features across perspectives using an MLP-based transformation; and a Global Feature Recalibration (GFR) module that reweights informative feature channels guided by learned spatial cues. The proposed CLNet can jointly capture both high-level semantics and fine-grained alignments. Extensive experiments on four public benchmarks, CVUSA, CVACT, VIGOR, and University-1652, demonstrate that our proposed CLNet achieves state-of-the-art performance while offering better interpretability and generalizability.
Lightweight Adapter Learning for More Generalized Remote Sensing Change Detection
Apr 28, 2025



Deep learning methods have shown promising performances in remote sensing image change detection (CD). However, existing methods usually train a dataset-specific deep network for each dataset. Due to the significant differences in the data distribution and labeling between various datasets, the trained dataset-specific deep network has poor generalization performances on other datasets. To solve this problem, this paper proposes a change adapter network (CANet) for a more universal and generalized CD. CANet contains dataset-shared and dataset-specific learning modules. The former explores the discriminative features of images, and the latter designs a lightweight adapter model, to deal with the characteristics of different datasets in data distribution and labeling. The lightweight adapter can quickly generalize the deep network for new CD tasks with a small computation cost. Specifically, this paper proposes an interesting change region mask (ICM) in the adapter, which can adaptively focus on interested change objects and decrease the influence of labeling differences in various datasets. Moreover, CANet adopts a unique batch normalization layer for each dataset to deal with data distribution differences. Compared with existing deep learning methods, CANet can achieve satisfactory CD performances on various datasets simultaneously. Experimental results on several public datasets have verified the effectiveness and advantages of the proposed CANet on CD. CANet has a stronger generalization ability, smaller training costs (merely updating 4.1%-7.7% parameters), and better performances under limited training datasets than other deep learning methods, which also can be flexibly inserted with existing deep models.
Unsupervised Outlier Detection using Memory and Contrastive Learning
Jul 27, 2021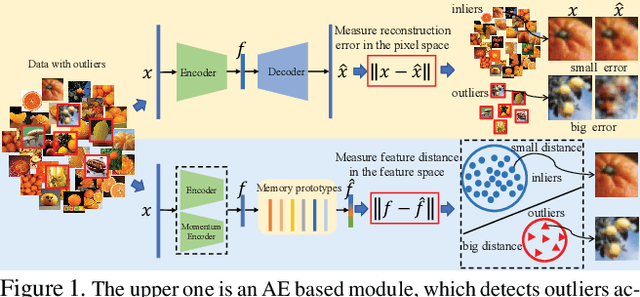
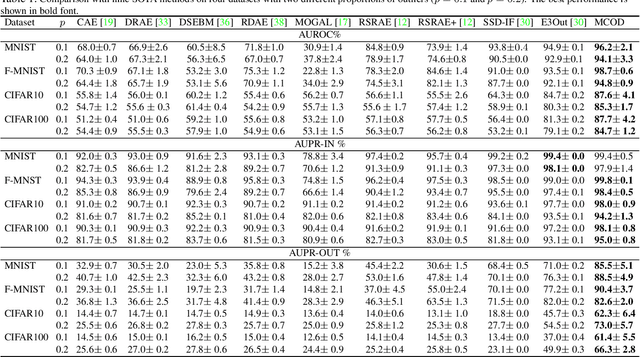
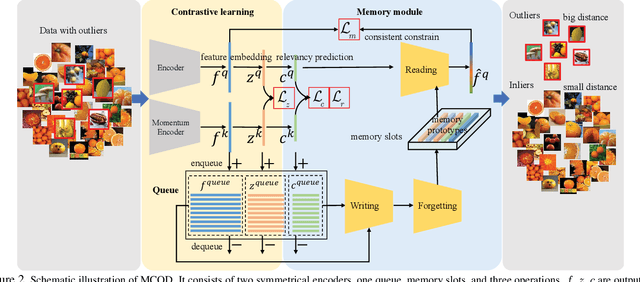
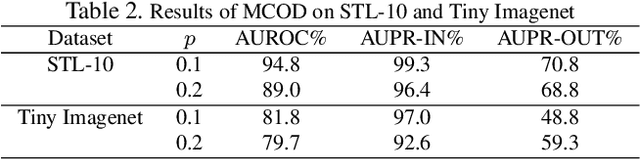
Outlier detection is one of the most important processes taken to create good, reliable data in machine learning. The most methods of outlier detection leverage an auxiliary reconstruction task by assuming that outliers are more difficult to be recovered than normal samples (inliers). However, it is not always true, especially for auto-encoder (AE) based models. They may recover certain outliers even outliers are not in the training data, because they do not constrain the feature learning. Instead, we think outlier detection can be done in the feature space by measuring the feature distance between outliers and inliers. We then propose a framework, MCOD, using a memory module and a contrastive learning module. The memory module constrains the consistency of features, which represent the normal data. The contrastive learning module learns more discriminating features, which boosts the distinction between outliers and inliers. Extensive experiments on four benchmark datasets show that our proposed MCOD achieves a considerable performance and outperforms nine state-of-the-art methods.