 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiology Instructions: A Dataset and Benchmark for Multi-Omics Sequence Understanding Capability of Large Language Models
Dec 26, 2024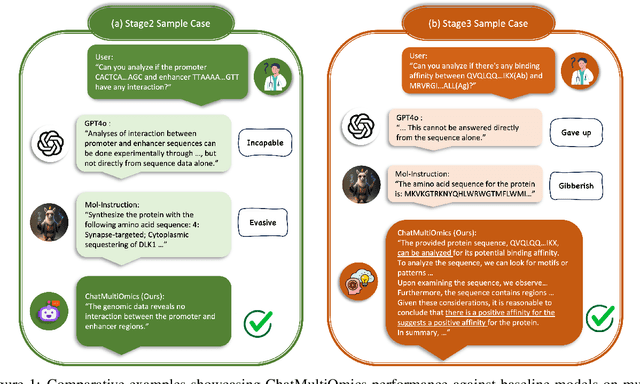
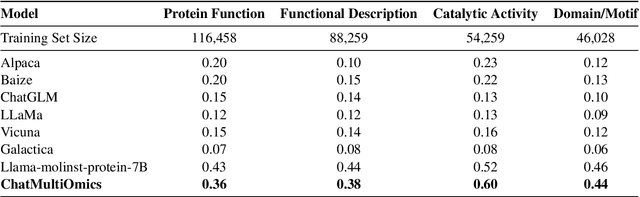
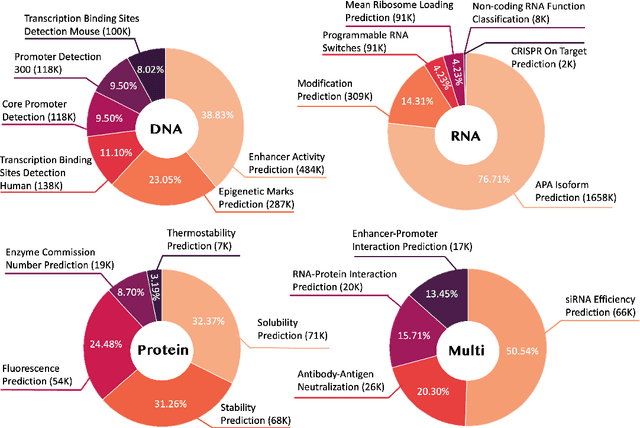
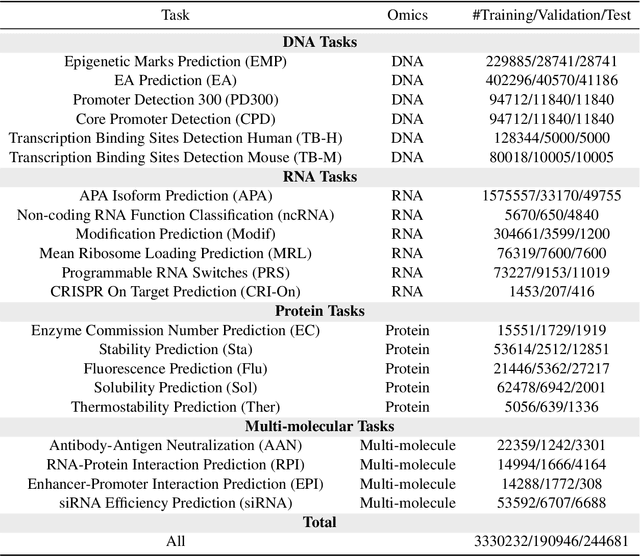
Large language models have already demonstrated their formidable capabilities in general domains, ushering in a revolutionary transformation. However, exploring and exploiting the extensive knowledge of these models to comprehend multi-omics biology remains underexplored. To fill this research gap, we first introduce Biology-Instructions, the first large-scale multi-omics biological sequences-related instruction-tuning dataset including DNA, RNA, proteins, and multi-molecules, designed to bridge the gap between large language models (LLMs) and complex biological sequences-related tasks. This dataset can enhance the versatility of LLMs by integrating diverse biological sequenced-based prediction tasks with advanced reasoning capabilities, while maintaining conversational fluency. Additionally, we reveal significant performance limitations in even state-of-the-art LLMs on biological sequence-related multi-omics tasks without specialized pre-training and instruction-tuning. We further develop a strong baseline called ChatMultiOmics with a novel three-stage training pipeline, demonstrating the powerful ability to understand biology by using Biology-Instructions. Biology-Instructions and ChatMultiOmics are publicly available and crucial resources for enabling more effective integration of LLMs with multi-omics sequence analysis.
TAR3D: Creating High-Quality 3D Assets via Next-Part Prediction
Dec 22, 2024



We present TAR3D, a novel framework that consists of a 3D-aware Vector Quantized-Variational AutoEncoder (VQ-VAE) and a Generative Pre-trained Transformer (GPT) to generate high-quality 3D assets. The core insight of this work is to migrate the multimodal unification and promising learning capabilities of the next-token prediction paradigm to conditional 3D object generation. To achieve this, the 3D VQ-VAE first encodes a wide range of 3D shapes into a compact triplane latent space and utilizes a set of discrete representations from a trainable codebook to reconstruct fine-grained geometries under the supervision of query point occupancy. Then, the 3D GPT, equipped with a custom triplane position embedding called TriPE, predicts the codebook index sequence with prefilling prompt tokens in an autoregressive manner so that the composition of 3D geometries can be modeled part by part. Extensive experiments on ShapeNet and Objaverse demonstrate that TAR3D can achieve superior generation quality over existing methods in text-to-3D and image-to-3D tasks
Model Decides How to Tokenize: Adaptive DNA Sequence Tokenization with MxDNA
Dec 18, 2024Foundation models have made significant strides in understanding the genomic language of DNA sequences. However, previous models typically adopt the tokenization methods designed for natural language, which are unsuitable for DNA sequences due to their unique characteristics. In addition, the optimal approach to tokenize DNA remains largely under-explored, and may not be intuitively understood by humans even if discovered. To address these challenges, we introduce MxDNA, a novel framework where the model autonomously learns an effective DNA tokenization strategy through gradient decent. MxDNA employs a sparse Mixture of Convolution Experts coupled with a deformable convolution to model the tokenization process, with the discontinuous, overlapping, and ambiguous nature of meaningful genomic segments explicitly considered. On Nucleotide Transformer Benchmarks and Genomic Benchmarks, MxDNA demonstrates superior performance to existing methods with less pretraining data and time, highlighting its effectiveness. Finally, we show that MxDNA learns unique tokenization strategy distinct to those of previous methods and captures genomic functionalities at a token level during self-supervised pretraining. Our MxDNA aims to provide a new perspective on DNA tokenization, potentially offering broad applications in various domains and yielding profound insights.
COMET: Benchmark for Comprehensive Biological Multi-omics Evaluation Tasks and Language Models
Dec 13, 2024



As key elements within the central dogma, DNA, RNA, and proteins play crucial roles in maintaining life by guaranteeing accurate genetic expression and implementation. Although research on these molecules has profoundly impacted fields like medicine, agriculture, and industry, the diversity of machine learning approaches-from traditional statistical methods to deep learning models and large language models-poses challenges for researchers in choosing the most suitable models for specific tasks, especially for cross-omics and multi-omics tasks due to the lack of comprehensive benchmarks. To address this, we introduce the first comprehensive multi-omics benchmark COMET (Benchmark for Biological COmprehensive Multi-omics Evaluation Tasks and Language Models), designed to evaluate models across single-omics, cross-omics, and multi-omics tasks. First, we curate and develop a diverse collection of downstream tasks and datasets covering key structural and functional aspects in DNA, RNA, and proteins, including tasks that span multiple omics levels. Then, we evaluate existing foundational language models for DNA, RNA, and proteins, as well as the newly proposed multi-omics method, offering valuable insights into their performance in integrating and analyzing data from different biological modalities. This benchmark aims to define critical issues in multi-omics research and guide future directions, ultimately promoting advancements in understanding biological processes through integrated and different omics data analysis.
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning
Dec 02, 2024



Vision-language models (VLMs) have shown remarkable advancements in multimodal reasoning tasks. However, they still often generate inaccurate or irrelevant responses due to issues like hallucinated image understandings or unrefined reasoning paths. To address these challenges, we introduce Critic-V, a novel framework inspired by the Actor-Critic paradigm to boost the reasoning capability of VLMs. This framework decouples the reasoning process and critic process by integrating two independent components: the Reasoner, which generates reasoning paths based on visual and textual inputs, and the Critic, which provides constructive critique to refine these paths. In this approach, the Reasoner generates reasoning responses according to text prompts, which can evolve iteratively as a policy based on feedback from the Critic. This interaction process was theoretically driven by a reinforcement learning framework where the Critic offers natural language critiques instead of scalar rewards, enabling more nuanced feedback to boost the Reasoner's capability on complex reasoning tasks. The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked by Rule-based Reward~(RBR) to enhance its critic capabilities. Evaluation results show that the Critic-V framework significantly outperforms existing methods, including GPT-4V, on 5 out of 8 benchmarks, especially regarding reasoning accuracy and efficiency. Combining a dynamic text-based policy for the Reasoner and constructive feedback from the preference-optimized Critic enables a more reliable and context-sensitive multimodal reasoning process. Our approach provides a promising solution to enhance the reliability of VLMs, improving their performance in real-world reasoning-heavy multimodal applications such as autonomous driving and embodied intelligence.
OASIS: Open Agent Social Interaction Simulations with One Million Agents
Nov 26, 2024



There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
Neuro-3D: Towards 3D Visual Decoding from EEG Signals
Nov 21, 2024Human's perception of the visual world is shaped by the stereo processing of 3D information. Understanding how the brain perceives and processes 3D visual stimuli in the real world has been a longstanding endeavor in neuroscience. Towards this goal, we introduce a new neuroscience task: decoding 3D visual perception from EEG signals, a neuroimaging technique that enables real-time monitoring of neural dynamics enriched with complex visual cues. To provide the essential benchmark, we first present EEG-3D, a pioneering dataset featuring multimodal analysis data and extensive EEG recordings from 12 subjects viewing 72 categories of 3D objects rendered in both videos and images. Furthermore, we propose Neuro-3D, a 3D visual decoding framework based on EEG signals. This framework adaptively integrates EEG features derived from static and dynamic stimuli to learn complementary and robust neural representations, which are subsequently utilized to recover both the shape and color of 3D objects through the proposed diffusion-based colored point cloud decoder. To the best of our knowledge, we are the first to explore EEG-based 3D visual decoding. Experiments indicate that Neuro-3D not only reconstructs colored 3D objects with high fidelity, but also learns effective neural representations that enable insightful brain region analysis. The dataset and associated code will be made publicly available.
OASIS: Open Agents Social Interaction Simulations on One Million Agents
Nov 21, 2024There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
DATAP-SfM: Dynamic-Aware Tracking Any Point for Robust Structure from Motion in the Wild
Nov 20, 2024



This paper proposes a concise, elegant, and robust pipeline to estimate smooth camera trajectories and obtain dense point clouds for casual videos in the wild. Traditional frameworks, such as ParticleSfM~\cite{zhao2022particlesfm}, address this problem by sequentially computing the optical flow between adjacent frames to obtain point trajectories. They then remove dynamic trajectories through motion segmentation and perform global bundle adjustment. However, the process of estimating optical flow between two adjacent frames and chaining the matches can introduce cumulative errors. Additionally, motion segmentation combined with single-view depth estimation often faces challenges related to scale ambiguity. To tackle these challenges, we propose a dynamic-aware tracking any point (DATAP) method that leverages consistent video depth and point tracking. Specifically, our DATAP addresses these issues by estimating dense point tracking across the video sequence and predicting the visibility and dynamics of each point. By incorporating the consistent video depth prior, the performance of motion segmentation is enhanced. With the integration of DATAP, it becomes possible to estimate and optimize all camera poses simultaneously by performing global bundle adjustments for point tracking classified as static and visible, rather than relying on incremental camera registration. Extensive experiments on dynamic sequences, e.g., Sintel and TUM RGBD dynamic sequences, and on the wild video, e.g., DAVIS, demonstrate that the proposed method achieves state-of-the-art performance in terms of camera pose estimation even in complex dynamic challenge scenes.
FengWu-W2S: A deep learning model for seamless weather-to-subseasonal forecast of global atmosphere
Nov 15, 2024Seamless forecasting that produces warning information at continuum timescales based on only one system is a long-standing pursuit for weather-climate service. While the rapid advancement of deep learning has induced revolutionary changes in classical forecasting field, current efforts are still focused on building separate AI models for weather and climate forecasts. To explore the seamless forecasting ability based on one AI model, we propose FengWu-Weather to Subseasonal (FengWu-W2S), which builds on the FengWu global weather forecast model and incorporates an ocean-atmosphere-land coupling structure along with a diverse perturbation strategy. FengWu-W2S can generate 6-hourly atmosphere forecasts extending up to 42 days through an autoregressive and seamless manner. Our hindcast results demonstrate that FengWu-W2S reliably predicts atmospheric conditions out to 3-6 weeks ahead, enhancing predictive capabilities for global surface air temperature, precipitation, geopotential height and intraseasonal signals such as the Madden-Julian Oscillation (MJO) and North Atlantic Oscillation (NAO). Moreover, our ablation experiments on forecast error growth from daily to seasonal timescales reveal potential pathways for developing AI-based integrated system for seamless weather-climate forecasting in the future.