 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Grounded Video Reasoning: Understanding and Perceiving Motion at Pixel Level
Nov 15, 2024



In this paper, we introduce Motion-Grounded Video Reasoning, a new motion understanding task that requires generating visual answers (video segmentation masks) according to the input question, and hence needs implicit spatiotemporal reasoning and grounding. This task extends existing spatiotemporal grounding work focusing on explicit action/motion grounding, to a more general format by enabling implicit reasoning via questions. To facilitate the development of the new task, we collect a large-scale dataset called GROUNDMORE, which comprises 1,715 video clips, 249K object masks that are deliberately designed with 4 question types (Causal, Sequential, Counterfactual, and Descriptive) for benchmarking deep and comprehensive motion reasoning abilities. GROUNDMORE uniquely requires models to generate visual answers, providing a more concrete and visually interpretable response than plain texts. It evaluates models on both spatiotemporal grounding and reasoning, fostering to address complex challenges in motion-related video reasoning, temporal perception, and pixel-level understanding. Furthermore, we introduce a novel baseline model named Motion-Grounded Video Reasoning Assistant (MORA). MORA incorporates the multimodal reasoning ability from the Multimodal LLM, the pixel-level perception capability from the grounding model (SAM), and the temporal perception ability from a lightweight localization head. MORA achieves respectable performance on GROUNDMORE outperforming the best existing visual grounding baseline model by an average of 21.5% relatively. We hope this novel and challenging task will pave the way for future advancements in robust and general motion understanding via video reasoning segmentation
Dense Connector for MLLMs
May 22, 2024



Do we fully leverage the potential of visual encoder in Multimodal Large Language Models (MLLMs)? The recent outstanding performance of MLLMs in multimodal understanding has garnered broad attention from both academia and industry. In the current MLLM rat race, the focus seems to be predominantly on the linguistic side. We witness the rise of larger and higher-quality instruction datasets, as well as the involvement of larger-sized LLMs. Yet, scant attention has been directed towards the visual signals utilized by MLLMs, often assumed to be the final high-level features extracted by a frozen visual encoder. In this paper, we introduce the Dense Connector - a simple, effective, and plug-and-play vision-language connector that significantly enhances existing MLLMs by leveraging multi-layer visual features, with minimal additional computational overhead. Furthermore, our model, trained solely on images, showcases remarkable zero-shot capabilities in video understanding as well. Experimental results across various vision encoders, image resolutions, training dataset scales, varying sizes of LLMs (2.7B->70B), and diverse architectures of MLLMs (e.g., LLaVA and Mini-Gemini) validate the versatility and scalability of our approach, achieving state-of-the-art performance on across 19 image and video benchmarks. We hope that this work will provide valuable experience and serve as a basic module for future MLLM development.
AutoGluon-Multimodal (AutoMM): Supercharging Multimodal AutoML with Foundation Models
Apr 30, 2024



AutoGluon-Multimodal (AutoMM) is introduced as an open-source AutoML library designed specifically for multimodal learning. Distinguished by its exceptional ease of use, AutoMM enables fine-tuning of foundation models with just three lines of code. Supporting various modalities including image, text, and tabular data, both independently and in combination, the library offers a comprehensive suite of functionalities spanning classification, regression, object detection, semantic matching, and image segmentation. Experiments across diverse datasets and tasks showcases AutoMM's superior performance in basic classification and regression tasks compared to existing AutoML tools, while also demonstrating competitive results in advanced tasks, aligning with specialized toolboxes designed for such purposes.
ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
Apr 11, 2024



To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time and memory costs. To address this, we introduce an efficient reward strategy that deliberately disturbs the input images by adding noise, and then uses the single-step denoised images for reward fine-tuning. This avoids the extensive costs associated with image sampling, allowing for more efficient reward fine-tuning. Extensive experiments show that ControlNet++ significantly improves controllability under various conditional controls. For example, it achieves improvements over ControlNet by 7.9% mIoU, 13.4% SSIM, and 7.6% RMSE, respectively, for segmentation mask, line-art edge, and depth conditions.
A Large-scale Study of Spatiotemporal Representation Learning with a New Benchmark on Action Recognition
Mar 23, 2023



The goal of building a benchmark (suite of datasets) is to provide a unified protocol for fair evaluation and thus facilitate the evolution of a specific area. Nonetheless, we point out that existing protocols of action recognition could yield partial evaluations due to several limitations. To comprehensively probe the effectiveness of spatiotemporal representation learning, we introduce BEAR, a new BEnchmark on video Action Recognition. BEAR is a collection of 18 video datasets grouped into 5 categories (anomaly, gesture, daily, sports, and instructional), which covers a diverse set of real-world applications. With BEAR, we thoroughly evaluate 6 common spatiotemporal models pre-trained by both supervised and self-supervised learning. We also report transfer performance via standard finetuning, few-shot finetuning, and unsupervised domain adaptation. Our observation suggests that current state-of-the-art cannot solidly guarantee high performance on datasets close to real-world applications, and we hope BEAR can serve as a fair and challenging evaluation benchmark to gain insights on building next-generation spatiotemporal learners. Our dataset, code, and models are released at: https://github.com/AndongDeng/BEAR
AIM: Adapting Image Models for Efficient Video Action Recognition
Feb 06, 2023



Recent vision transformer based video models mostly follow the ``image pre-training then finetuning" paradigm and have achieved great success on multiple video benchmarks. However, full finetuning such a video model could be computationally expensive and unnecessary, given the pre-trained image transformer models have demonstrated exceptional transferability. In this work, we propose a novel method to Adapt pre-trained Image Models (AIM) for efficient video understanding. By freezing the pre-trained image model and adding a few lightweight Adapters, we introduce spatial adaptation, temporal adaptation and joint adaptation to gradually equip an image model with spatiotemporal reasoning capability. We show that our proposed AIM can achieve competitive or even better performance than prior arts with substantially fewer tunable parameters on four video action recognition benchmarks. Thanks to its simplicity, our method is also generally applicable to different image pre-trained models, which has the potential to leverage more powerful image foundation models in the future. The project webpage is \url{https://adapt-image-models.github.io/}.
Problem Behaviors Recognition in Videos using Language-Assisted Deep Learning Model for Children with Autism
Nov 17, 2022



Correctly recognizing the behaviors of children with Autism Spectrum Disorder (ASD) is of vital importance for the diagnosis of Autism and timely early intervention. However, the observation and recording during the treatment from the parents of autistic children may not be accurate and objective. In such cases, automatic recognition systems based on computer vision and machine learning (in particular deep learning) technology can alleviate this issue to a large extent. Existing human action recognition models can now achieve persuasive performance on challenging activity datasets, e.g. daily activity, and sports activity. However, problem behaviors in children with ASD are very different from these general activities, and recognizing these problem behaviors via computer vision is less studied. In this paper, we first evaluate a strong baseline for action recognition, i.e. Video Swin Transformer, on two autism behaviors datasets (SSBD and ESBD) and show that it can achieve high accuracy and outperform the previous methods by a large margin, demonstrating the feasibility of vision-based problem behaviors recognition. Moreover, we propose language-assisted training to further enhance the action recognition performance. Specifically, we develop a two-branch multimodal deep learning framework by incorporating the "freely available" language description for each type of problem behavior. Experimental results demonstrate that incorporating additional language supervision can bring an obvious performance boost for the autism problem behaviors recognition task as compared to using the video information only (i.e. 3.49% improvement on ESBD and 1.46% on SSBD).
Revisiting Training-free NAS Metrics: An Efficient Training-based Method
Nov 16, 2022Recent neural architecture search (NAS) works proposed training-free metrics to rank networks which largely reduced the search cost in NAS. In this paper, we revisit these training-free metrics and find that: (1) the number of parameters (\#Param), which is the most straightforward training-free metric, is overlooked in previous works but is surprisingly effective, (2) recent training-free metrics largely rely on the \#Param information to rank networks. Our experiments show that the performance of recent training-free metrics drops dramatically when the \#Param information is not available. Motivated by these observations, we argue that metrics less correlated with the \#Param are desired to provide additional information for NAS. We propose a light-weight training-based metric which has a weak correlation with the \#Param while achieving better performance than training-free metrics at a lower search cost. Specifically, on DARTS search space, our method completes searching directly on ImageNet in only 2.6 GPU hours and achieves a top-1/top-5 error rate of 24.1\%/7.1\%, which is competitive among state-of-the-art NAS methods. Codes are available at \url{https://github.com/taoyang1122/Revisit_TrainingFree_NAS}
Exploring Parameter-Efficient Fine-tuning for Improving Communication Efficiency in Federated Learning
Oct 04, 2022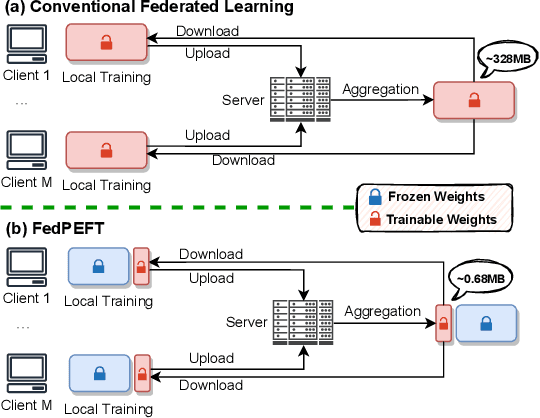
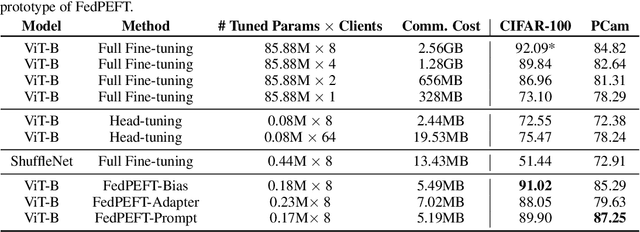
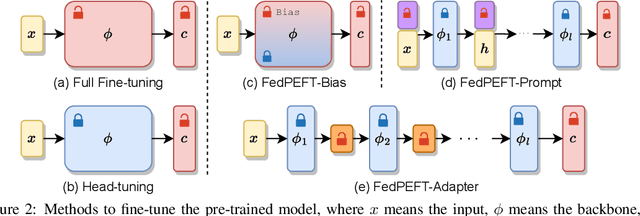

Federated learning (FL) has emerged as a promising paradigm for enabling the collaborative training of models without centralized access to the raw data on local devices. In the typical FL paradigm (e.g., FedAvg), model weights are sent to and from the server each round to participating clients. However, this can quickly put a massive communication burden on the system, especially if more capable models beyond very small MLPs are employed. Recently, the use of pre-trained models has been shown effective in federated learning optimization and improving convergence. This opens the door for new research questions. Can we adjust the weight-sharing paradigm in federated learning, leveraging strong and readily-available pre-trained models, to significantly reduce the communication burden while simultaneously achieving excellent performance? To this end, we investigate the use of parameter-efficient fine-tuning in federated learning. Specifically, we systemically evaluate the performance of several parameter-efficient fine-tuning methods across a variety of client stability, data distribution, and differential privacy settings. By only locally tuning and globally sharing a small portion of the model weights, significant reductions in the total communication overhead can be achieved while maintaining competitive performance in a wide range of federated learning scenarios, providing insight into a new paradigm for practical and effective federated systems.
HeatER: An Efficient and Unified Network for Human Reconstruction via Heatmap-based TransformER
May 30, 2022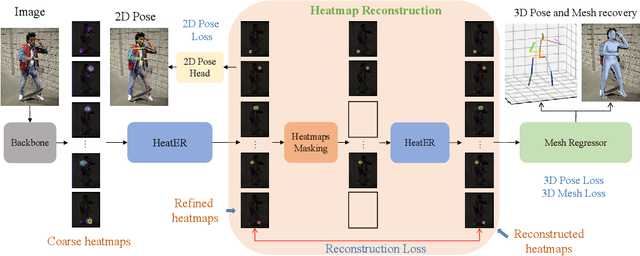
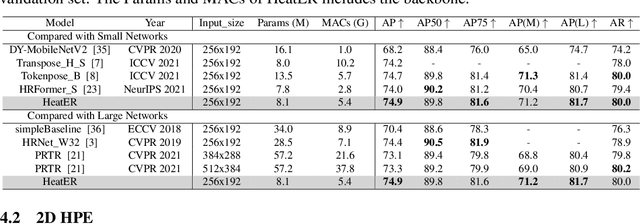
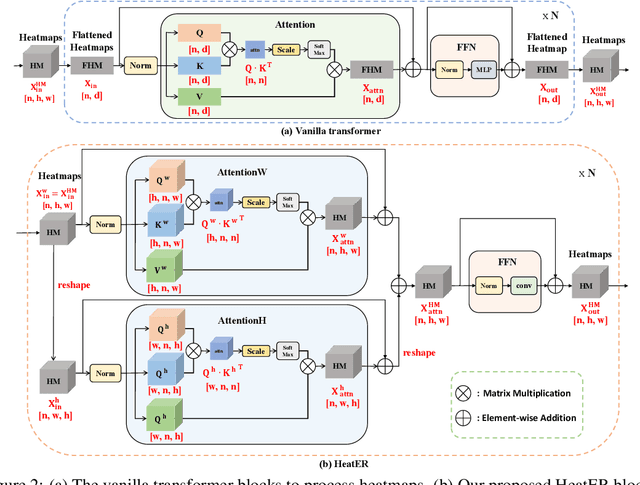
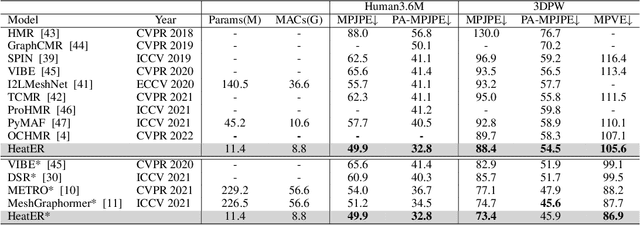
Recently, vision transformers have shown great success in 2D human pose estimation (2D HPE), 3D human pose estimation (3D HPE), and human mesh reconstruction (HMR) tasks. In these tasks, heatmap representations of the human structural information are often extracted first from the image by a CNN, and then further processed with a transformer architecture to provide the final HPE or HMR estimation. However, existing transformer architectures are not able to process these heatmap inputs directly, forcing an unnatural flattening of the features prior to input. Furthermore, much of the performance benefit in recent HPE and HMR methods has come at the cost of ever-increasing computation and memory needs. Therefore, to simultaneously address these problems, we propose HeatER, a novel transformer design which preserves the inherent structure of heatmap representations when modeling attention while reducing the memory and computational costs. Taking advantage of HeatER, we build a unified and efficient network for 2D HPE, 3D HPE, and HMR tasks. A heatmap reconstruction module is applied to improve the robustness of the estimated human pose and mesh. Extensive experiments demonstrate the effectiveness of HeatER on various human pose and mesh datasets. For instance, HeatER outperforms the SOTA method MeshGraphormer by requiring 5% of Params and 16% of MACs on Human3.6M and 3DPW datasets. Code will be publicly available.