 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerMatch: Do Pseudo-labels Benefit All Layers?
Jun 20, 2024



Deep neural networks have achieved remarkable performance across various tasks when supplied with large-scale labeled data. However, the collection of labeled data can be time-consuming and labor-intensive. Semi-supervised learning (SSL), particularly through pseudo-labeling algorithms that iteratively assign pseudo-labels for self-training, offers a promising solution to mitigate the dependency of labeled data. Previous research generally applies a uniform pseudo-labeling strategy across all model layers, assuming that pseudo-labels exert uniform influence throughout. Contrasting this, our theoretical analysis and empirical experiment demonstrate feature extraction layer and linear classification layer have distinct learning behaviors in response to pseudo-labels. Based on these insights, we develop two layer-specific pseudo-label strategies, termed Grad-ReLU and Avg-Clustering. Grad-ReLU mitigates the impact of noisy pseudo-labels by removing the gradient detrimental effects of pseudo-labels in the linear classification layer. Avg-Clustering accelerates the convergence of feature extraction layer towards stable clustering centers by integrating consistent outputs. Our approach, LayerMatch, which integrates these two strategies, can avoid the severe interference of noisy pseudo-labels in the linear classification layer while accelerating the clustering capability of the feature extraction layer. Through extensive experimentation, our approach consistently demonstrates exceptional performance on standard semi-supervised learning benchmarks, achieving a significant improvement of 10.38% over baseline method and a 2.44% increase compared to state-of-the-art methods.
Diffusion Models in Low-Level Vision: A Survey
Jun 17, 2024



Deep generative models have garnered significant attention in low-level vision tasks due to their generative capabilities. Among them, diffusion model-based solutions, characterized by a forward diffusion process and a reverse denoising process, have emerged as widely acclaimed for their ability to produce samples of superior quality and diversity. This ensures the generation of visually compelling results with intricate texture information. Despite their remarkable success, a noticeable gap exists in a comprehensive survey that amalgamates these pioneering diffusion model-based works and organizes the corresponding threads. This paper proposes the comprehensive review of diffusion model-based techniques. We present three generic diffusion modeling frameworks and explore their correlations with other deep generative models, establishing the theoretical foundation. Following this, we introduce a multi-perspective categorization of diffusion models, considering both the underlying framework and the target task. Additionally, we summarize extended diffusion models applied in other tasks, including medical, remote sensing, and video scenarios. Moreover, we provide an overview of commonly used benchmarks and evaluation metrics. We conduct a thorough evaluation, encompassing both performance and efficiency, of diffusion model-based techniques in three prominent tasks. Finally, we elucidate the limitations of current diffusion models and propose seven intriguing directions for future research. This comprehensive examination aims to facilitate a profound understanding of the landscape surrounding denoising diffusion models in the context of low-level vision tasks. A curated list of diffusion model-based techniques in over 20 low-level vision tasks can be found at https://github.com/ChunmingHe/awesome-diffusion-models-in-low-level-vision.
GLAD: Towards Better Reconstruction with Global and Local Adaptive Diffusion Models for Unsupervised Anomaly Detection
Jun 11, 2024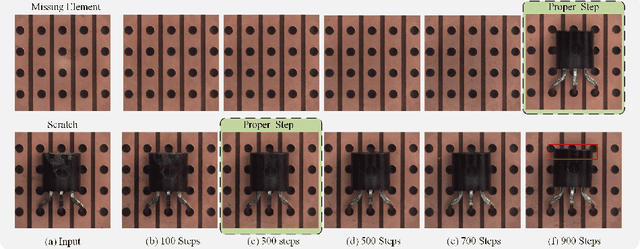
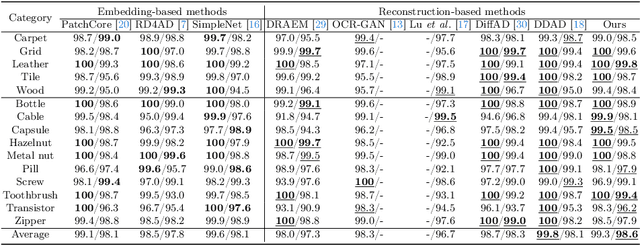

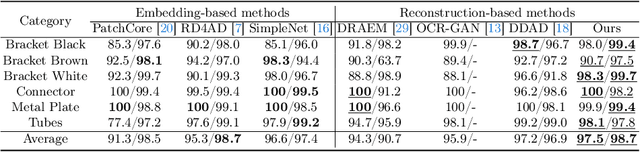
Diffusion models have shown superior performance on unsupervised anomaly detection tasks. Since trained with normal data only, diffusion models tend to reconstruct normal counterparts of test images with certain noises added. However, these methods treat all potential anomalies equally, which may cause two main problems. From the global perspective, the difficulty of reconstructing images with different anomalies is uneven. Therefore, instead of utilizing the same setting for all samples, we propose to predict a particular denoising step for each sample by evaluating the difference between image contents and the priors extracted from diffusion models. From the local perspective, reconstructing abnormal regions differs from normal areas even in the same image. Theoretically, the diffusion model predicts a noise for each step, typically following a standard Gaussian distribution. However, due to the difference between the anomaly and its potential normal counterpart, the predicted noise in abnormal regions will inevitably deviate from the standard Gaussian distribution. To this end, we propose introducing synthetic abnormal samples in training to encourage the diffusion models to break through the limitation of standard Gaussian distribution, and a spatial-adaptive feature fusion scheme is utilized during inference. With the above modifications, we propose a global and local adaptive diffusion model (abbreviated to GLAD) for unsupervised anomaly detection, which introduces appealing flexibility and achieves anomaly-free reconstruction while retaining as much normal information as possible. Extensive experiments are conducted on three commonly used anomaly detection datasets (MVTec-AD, MPDD, and VisA) and a printed circuit board dataset (PCB-Bank) we integrated, showing the effectiveness of the proposed method.
DreamPhysics: Learning Physical Properties of Dynamic 3D Gaussians with Video Diffusion Priors
Jun 03, 2024Dynamic 3D interaction has witnessed great interest in recent works, while creating such 4D content remains challenging. One solution is to animate 3D scenes with physics-based simulation, and the other is to learn the deformation of static 3D objects with the distillation of video generative models. The former one requires assigning precise physical properties to the target object, otherwise the simulated results would become unnatural. The latter tends to formulate the video with minor motions and discontinuous frames, due to the absence of physical constraints in deformation learning. We think that video generative models are trained with real-world captured data, capable of judging physical phenomenon in simulation environments. To this end, we propose DreamPhysics in this work, which estimates physical properties of 3D Gaussian Splatting with video diffusion priors. DreamPhysics supports both image- and text-conditioned guidance, optimizing physical parameters via score distillation sampling with frame interpolation and log gradient. Based on a material point method simulator with proper physical parameters, our method can generate 4D content with realistic motions. Experimental results demonstrate that, by distilling the prior knowledge of video diffusion models, inaccurate physical properties can be gradually refined for high-quality simulation. Codes are released at: https://github.com/tyhuang0428/DreamPhysics.
Two Optimizers Are Better Than One: LLM Catalyst for Enhancing Gradient-Based Optimization
May 31, 2024



Learning a skill generally relies on both practical experience by doer and insightful high-level guidance by instructor. Will this strategy also work well for solving complex non-convex optimization problems? Here, a common gradient-based optimizer acts like a disciplined doer, making locally optimal update at each step. Recent methods utilize large language models (LLMs) to optimize solutions for concrete problems by inferring from natural language instructions, akin to a high-level instructor. In this paper, we show that these two optimizers are complementary to each other, suggesting a collaborative optimization approach. The gradient-based optimizer and LLM-based optimizer are combined in an interleaved manner. We instruct LLMs using task descriptions and timely optimization trajectories recorded during gradient-based optimization. Inferred results from LLMs are used as restarting points for the next stage of gradient optimization. By leveraging both the locally rigorous gradient-based optimizer and the high-level deductive LLM-based optimizer, our combined optimization method consistently yields improvements over competitive baseline prompt tuning methods. Our results demonstrate the synergistic effect of conventional gradient-based optimization and the inference ability of LLMs. The code is released at https://github.com/guozix/LLM-catalyst.
Improved Generation of Adversarial Examples Against Safety-aligned LLMs
May 28, 2024



Despite numerous efforts to ensure large language models (LLMs) adhere to safety standards and produce harmless content, some successes have been achieved in bypassing these restrictions, known as jailbreak attacks against LLMs. Adversarial prompts generated using gradient-based methods exhibit outstanding performance in performing jailbreak attacks automatically. Nevertheless, due to the discrete nature of texts, the input gradient of LLMs struggles to precisely reflect the magnitude of loss change that results from token replacements in the prompt, leading to limited attack success rates against safety-aligned LLMs, even in the white-box setting. In this paper, we explore a new perspective on this problem, suggesting that it can be alleviated by leveraging innovations inspired in transfer-based attacks that were originally proposed for attacking black-box image classification models. For the first time, we appropriate the ideologies of effective methods among these transfer-based attacks, i.e., Skip Gradient Method and Intermediate Level Attack, for improving the effectiveness of automatically generated adversarial examples against white-box LLMs. With appropriate adaptations, we inject these ideologies into gradient-based adversarial prompt generation processes and achieve significant performance gains without introducing obvious computational cost. Meanwhile, by discussing mechanisms behind the gains, new insights are drawn, and proper combinations of these methods are also developed. Our empirical results show that the developed combination achieves >30% absolute increase in attack success rates compared with GCG for attacking the Llama-2-7B-Chat model on AdvBench.
Variable Substitution and Bilinear Programming for Aligning Partially Overlapping Point Sets
May 14, 2024In many applications, the demand arises for algorithms capable of aligning partially overlapping point sets while remaining invariant to the corresponding transformations. This research presents a method designed to meet such requirements through minimization of the objective function of the robust point matching (RPM) algorithm. First, we show that the RPM objective is a cubic polynomial. Then, through variable substitution, we transform the RPM objective to a quadratic function. Leveraging the convex envelope of bilinear monomials, we proceed to relax the resulting objective function, thus obtaining a lower bound problem that can be conveniently decomposed into distinct linear assignment and low-dimensional convex quadratic program components, both amenable to efficient optimization. Furthermore, a branch-and-bound (BnB) algorithm is devised, which solely branches over the transformation parameters, thereby boosting convergence rate. Empirical evaluations demonstrate better robustness of the proposed methodology against non-rigid deformation, positional noise, and outliers, particularly in scenarios where outliers remain distinct from inliers, when compared with prevailing state-of-the-art approaches.
MasterWeaver: Taming Editability and Identity for Personalized Text-to-Image Generation
May 10, 2024Text-to-image (T2I) diffusion models have shown significant success in personalized text-to-image generation, which aims to generate novel images with human identities indicated by the reference images. Despite promising identity fidelity has been achieved by several tuning-free methods, they usually suffer from overfitting issues. The learned identity tends to entangle with irrelevant information, resulting in unsatisfied text controllability, especially on faces. In this work, we present MasterWeaver, a test-time tuning-free method designed to generate personalized images with both faithful identity fidelity and flexible editability. Specifically, MasterWeaver adopts an encoder to extract identity features and steers the image generation through additional introduced cross attention. To improve editability while maintaining identity fidelity, we propose an editing direction loss for training, which aligns the editing directions of our MasterWeaver with those of the original T2I model. Additionally, a face-augmented dataset is constructed to facilitate disentangled identity learning, and further improve the editability. Extensive experiments demonstrate that our MasterWeaver can not only generate personalized images with faithful identity, but also exhibit superiority in text controllability. Our code will be publicly available at https://github.com/csyxwei/MasterWeaver.
MV-VTON: Multi-View Virtual Try-On with Diffusion Models
Apr 29, 2024The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, most existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results of a person from multiple views using the given clothes. On the one hand, given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. On the other hand, the diffusion models that have demonstrated superior abilities are adopted to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest a joint attention block to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset, i.e., Multi-View Garment (MVG), in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets will be publicly released at https://github.com/hywang2002/MV-VTON .
IMWA: Iterative Model Weight Averaging Benefits Class-Imbalanced Learning Tasks
Apr 25, 2024



Model Weight Averaging (MWA) is a technique that seeks to enhance model's performance by averaging the weights of multiple trained models. This paper first empirically finds that 1) the vanilla MWA can benefit the class-imbalanced learning, and 2) performing model averaging in the early epochs of training yields a greater performance improvement than doing that in later epochs. Inspired by these two observations, in this paper we propose a novel MWA technique for class-imbalanced learning tasks named Iterative Model Weight Averaging (IMWA). Specifically, IMWA divides the entire training stage into multiple episodes. Within each episode, multiple models are concurrently trained from the same initialized model weight, and subsequently averaged into a singular model. Then, the weight of this average model serves as a fresh initialization for the ensuing episode, thus establishing an iterative learning paradigm. Compared to vanilla MWA, IMWA achieves higher performance improvements with the same computational cost. Moreover, IMWA can further enhance the performance of those methods employing EMA strategy, demonstrating that IMWA and EMA can complement each other. Extensive experiments on various class-imbalanced learning tasks, i.e., class-imbalanced image classification, semi-supervised class-imbalanced image classification and semi-supervised object detection tasks showcase the effectiveness of our IMWA.