 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Image Harmonization
Dec 18, 2024



When embedding objects (foreground) into images (background), considering the influence of photography conditions like illumination, it is usually necessary to perform image harmonization to make the foreground object coordinate with the background image in terms of brightness, color, and etc. Although existing image harmonization methods have made continuous efforts toward visually pleasing results, they are still plagued by two main issues. Firstly, the image harmonization becomes highly ill-posed when there are no contents similar to the foreground object in the background, making the harmonization results unreliable. Secondly, even when similar contents are available, the harmonization process is often interfered with by irrelevant areas, mainly attributed to an insufficient understanding of image contents and inaccurate attention. As a remedy, we present a retrieval-augmented image harmonization (Raiha) framework, which seeks proper reference images to reduce the ill-posedness and restricts the attention to better utilize the useful information. Specifically, an efficient retrieval method is designed to find reference images that contain similar objects as the foreground while the illumination is consistent with the background. For training the Raiha framework to effectively utilize the reference information, a data augmentation strategy is delicately designed by leveraging existing non-reference image harmonization datasets. Besides, the image content priors are introduced to ensure reasonable attention. With the presented Raiha framework, the image harmonization performance is greatly boosted under both non-reference and retrieval-augmented settings. The source code and pre-trained models will be publicly available.
Learning Spatially Decoupled Color Representations for Facial Image Colorization
Dec 10, 2024Image colorization methods have shown prominent performance on natural images. However, since humans are more sensitive to faces, existing methods are insufficient to meet the demands when applied to facial images, typically showing unnatural and uneven colorization results. In this paper, we investigate the facial image colorization task and find that the problems with facial images can be attributed to an insufficient understanding of facial components. As a remedy, by introducing facial component priors, we present a novel facial image colorization framework dubbed FCNet. Specifically, we learn a decoupled color representation for each face component (e.g., lips, skin, eyes, and hair) under the guidance of face parsing maps. A chromatic and spatial augmentation strategy is presented to facilitate the learning procedure, which requires only grayscale and color facial image pairs. After training, the presented FCNet can be naturally applied to facial image colorization with single or multiple reference images. To expand the application paradigms to scenarios with no reference images, we further train two alternative modules, which predict the color representations from the grayscale input or a random seed, respectively. Extensive experiments show that our method can perform favorably against existing methods in various application scenarios (i.e., no-, single-, and multi-reference facial image colorization). The source code and pre-trained models will be publicly available.
Deblur4DGS: 4D Gaussian Splatting from Blurry Monocular Video
Dec 09, 2024



Recent 4D reconstruction methods have yielded impressive results but rely on sharp videos as supervision. However, motion blur often occurs in videos due to camera shake and object movement, while existing methods render blurry results when using such videos for reconstructing 4D models. Although a few NeRF-based approaches attempted to address the problem, they struggled to produce high-quality results, due to the inaccuracy in estimating continuous dynamic representations within the exposure time. Encouraged by recent works in 3D motion trajectory modeling using 3D Gaussian Splatting (3DGS), we suggest taking 3DGS as the scene representation manner, and propose the first 4D Gaussian Splatting framework to reconstruct a high-quality 4D model from blurry monocular video, named Deblur4DGS. Specifically, we transform continuous dynamic representations estimation within an exposure time into the exposure time estimation. Moreover, we introduce exposure regularization to avoid trivial solutions, as well as multi-frame and multi-resolution consistency ones to alleviate artifacts. Furthermore, to better represent objects with large motion, we suggest blur-aware variable canonical Gaussians. Beyond novel-view synthesis, Deblur4DGS can be applied to improve blurry video from multiple perspectives, including deblurring, frame interpolation, and video stabilization. Extensive experiments on the above four tasks show that Deblur4DGS outperforms state-of-the-art 4D reconstruction methods. The codes are available at https://github.com/ZcsrenlongZ/Deblur4DGS.
Combining Generative and Geometry Priors for Wide-Angle Portrait Correction
Oct 13, 2024Wide-angle lens distortion in portrait photography presents a significant challenge for capturing photo-realistic and aesthetically pleasing images. Such distortions are especially noticeable in facial regions. In this work, we propose encapsulating the generative face prior as a guided natural manifold to facilitate the correction of facial regions. Moreover, a notable central symmetry relationship exists in the non-face background, yet it has not been explored in the correction process. This geometry prior motivates us to introduce a novel constraint to explicitly enforce symmetry throughout the correction process, thereby contributing to a more visually appealing and natural correction in the non-face region. Experiments demonstrate that our approach outperforms previous methods by a large margin, excelling not only in quantitative measures such as line straightness and shape consistency metrics but also in terms of perceptual visual quality. All the code and models are available at https://github.com/Dev-Mrha/DualPriorsCorrection.
GLAD: Towards Better Reconstruction with Global and Local Adaptive Diffusion Models for Unsupervised Anomaly Detection
Jun 11, 2024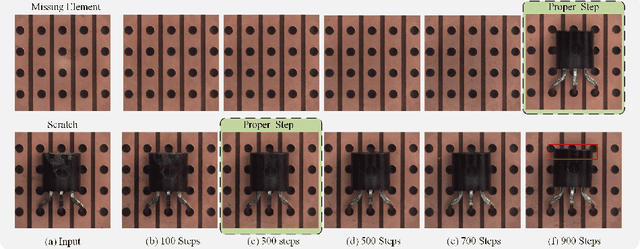
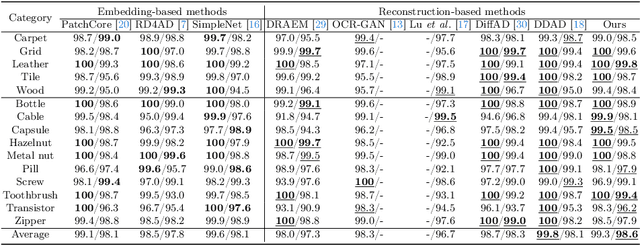

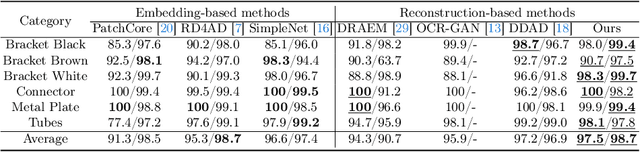
Diffusion models have shown superior performance on unsupervised anomaly detection tasks. Since trained with normal data only, diffusion models tend to reconstruct normal counterparts of test images with certain noises added. However, these methods treat all potential anomalies equally, which may cause two main problems. From the global perspective, the difficulty of reconstructing images with different anomalies is uneven. Therefore, instead of utilizing the same setting for all samples, we propose to predict a particular denoising step for each sample by evaluating the difference between image contents and the priors extracted from diffusion models. From the local perspective, reconstructing abnormal regions differs from normal areas even in the same image. Theoretically, the diffusion model predicts a noise for each step, typically following a standard Gaussian distribution. However, due to the difference between the anomaly and its potential normal counterpart, the predicted noise in abnormal regions will inevitably deviate from the standard Gaussian distribution. To this end, we propose introducing synthetic abnormal samples in training to encourage the diffusion models to break through the limitation of standard Gaussian distribution, and a spatial-adaptive feature fusion scheme is utilized during inference. With the above modifications, we propose a global and local adaptive diffusion model (abbreviated to GLAD) for unsupervised anomaly detection, which introduces appealing flexibility and achieves anomaly-free reconstruction while retaining as much normal information as possible. Extensive experiments are conducted on three commonly used anomaly detection datasets (MVTec-AD, MPDD, and VisA) and a printed circuit board dataset (PCB-Bank) we integrated, showing the effectiveness of the proposed method.
Bracketing is All You Need: Unifying Image Restoration and Enhancement Tasks with Multi-Exposure Images
Jan 01, 2024



It is challenging but highly desired to acquire high-quality photos with clear content in low-light environments. Although multi-image processing methods (using burst, dual-exposure, or multi-exposure images) have made significant progress in addressing this issue, they typically focus exclusively on specific restoration or enhancement tasks, being insufficient in exploiting multi-image. Motivated by that multi-exposure images are complementary in denoising, deblurring, high dynamic range imaging, and super-resolution, we propose to utilize bracketing photography to unify restoration and enhancement tasks in this work. Due to the difficulty in collecting real-world pairs, we suggest a solution that first pre-trains the model with synthetic paired data and then adapts it to real-world unlabeled images. In particular, a temporally modulated recurrent network (TMRNet) and self-supervised adaptation method are proposed. Moreover, we construct a data simulation pipeline to synthesize pairs and collect real-world images from 200 nighttime scenarios. Experiments on both datasets show that our method performs favorably against the state-of-the-art multi-image processing ones. The dataset, code, and pre-trained models are available at https://github.com/cszhilu1998/BracketIRE.
Self-Supervised Image Restoration with Blurry and Noisy Pairs
Nov 14, 2022



When taking photos under an environment with insufficient light, the exposure time and the sensor gain usually require to be carefully chosen to obtain images with satisfying visual quality. For example, the images with high ISO usually have inescapable noise, while the long-exposure ones may be blurry due to camera shake or object motion. Existing solutions generally suggest to seek a balance between noise and blur, and learn denoising or deblurring models under either full- or self-supervision. However, the real-world training pairs are difficult to collect, and the self-supervised methods merely rely on blurry or noisy images are limited in performance. In this work, we tackle this problem by jointly leveraging the short-exposure noisy image and the long-exposure blurry image for better image restoration. Such setting is practically feasible due to that short-exposure and long-exposure images can be either acquired by two individual cameras or synthesized by a long burst of images. Moreover, the short-exposure images are hardly blurry, and the long-exposure ones have negligible noise. Their complementarity makes it feasible to learn restoration model in a self-supervised manner. Specifically, the noisy images can be used as the supervision information for deblurring, while the sharp areas in the blurry images can be utilized as the auxiliary supervision information for self-supervised denoising. By learning in a collaborative manner, the deblurring and denoising tasks in our method can benefit each other. Experiments on synthetic and real-world images show the effectiveness and practicality of the proposed method. Codes are available at https://github.com/cszhilu1998/SelfIR.
Incorporating Semi-Supervised and Positive-Unlabeled Learning for Boosting Full Reference Image Quality Assessment
Apr 19, 2022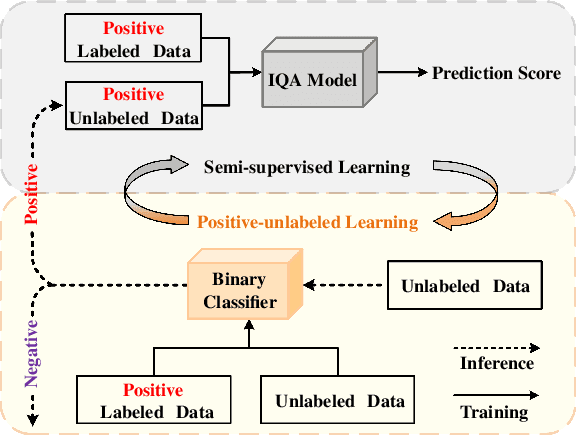
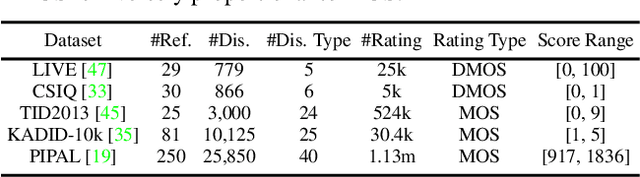
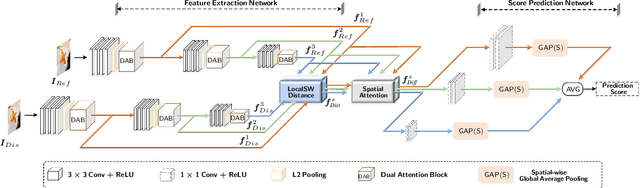
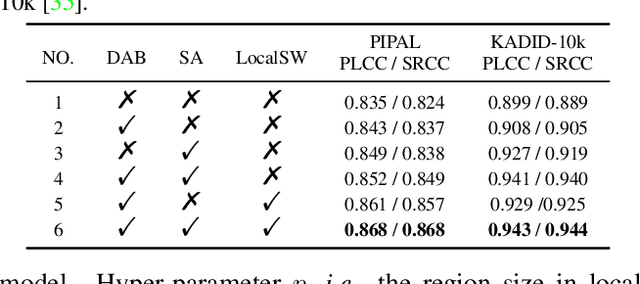
Full-reference (FR) image quality assessment (IQA) evaluates the visual quality of a distorted image by measuring its perceptual difference with pristine-quality reference, and has been widely used in low-level vision tasks. Pairwise labeled data with mean opinion score (MOS) are required in training FR-IQA model, but is time-consuming and cumbersome to collect. In contrast, unlabeled data can be easily collected from an image degradation or restoration process, making it encouraging to exploit unlabeled training data to boost FR-IQA performance. Moreover, due to the distribution inconsistency between labeled and unlabeled data, outliers may occur in unlabeled data, further increasing the training difficulty. In this paper, we suggest to incorporate semi-supervised and positive-unlabeled (PU) learning for exploiting unlabeled data while mitigating the adverse effect of outliers. Particularly, by treating all labeled data as positive samples, PU learning is leveraged to identify negative samples (i.e., outliers) from unlabeled data. Semi-supervised learning (SSL) is further deployed to exploit positive unlabeled data by dynamically generating pseudo-MOS. We adopt a dual-branch network including reference and distortion branches. Furthermore, spatial attention is introduced in the reference branch to concentrate more on the informative regions, and sliced Wasserstein distance is used for robust difference map computation to address the misalignment issues caused by images recovered by GAN models. Extensive experiments show that our method performs favorably against state-of-the-arts on the benchmark datasets PIPAL, KADID-10k, TID2013, LIVE and CSIQ.
Adaptive Network Combination for Single-Image Reflection Removal: A Domain Generalization Perspective
Apr 04, 2022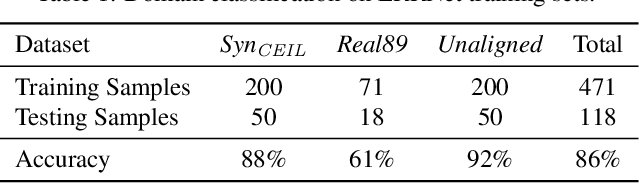
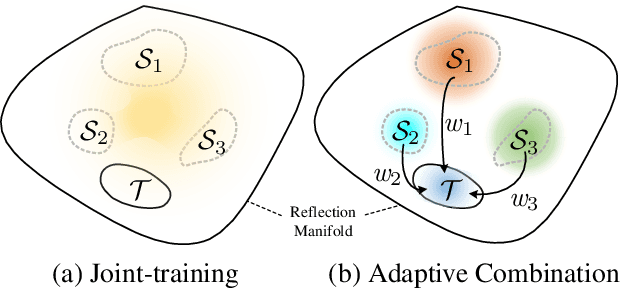
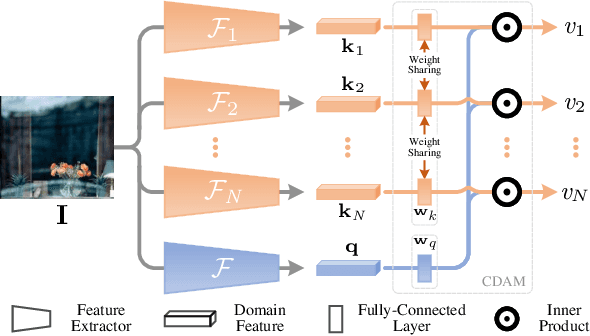

Recently, multiple synthetic and real-world datasets have been built to facilitate the training of deep single image reflection removal (SIRR) models. Meanwhile, diverse testing sets are also provided with different types of reflection and scenes. However, the non-negligible domain gaps between training and testing sets make it difficult to learn deep models generalizing well to testing images. The diversity of reflections and scenes further makes it a mission impossible to learn a single model being effective to all testing sets and real-world reflections. In this paper, we tackle these issues by learning SIRR models from a domain generalization perspective. Particularly, for each source set, a specific SIRR model is trained to serve as a domain expert of relevant reflection types. For a given reflection-contaminated image, we present a reflection type-aware weighting (RTAW) module to predict expert-wise weights. RTAW can then be incorporated with adaptive network combination (AdaNEC) for handling different reflection types and scenes, i.e., generalizing to unknown domains. Two representative AdaNEC methods, i.e., output fusion (OF) and network interpolation (NI), are provided by considering both adaptation levels and efficiency. For images from one source set, we train RTAW to only predict expert-wise weights of other domain experts for improving generalization ability, while the weights of all experts are predicted and employed during testing. An in-domain expert (IDE) loss is presented for training RTAW. Extensive experiments show the appealing performance gain of our AdaNEC on different state-of-the-art SIRR networks. Source code and pre-trained models will available at https://github.com/csmliu/AdaNEC.
Flexible Image Denoising with Multi-layer Conditional Feature Modulation
Jun 24, 2020
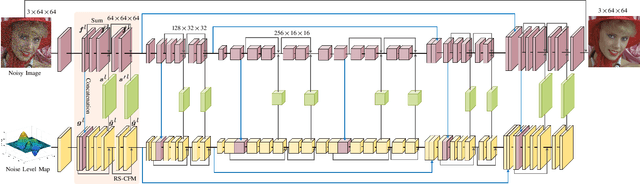


For flexible non-blind image denoising, existing deep networks usually take both noisy image and noise level map as the input to handle various noise levels with a single model. However, in this kind of solution, the noise variance (i.e., noise level) is only deployed to modulate the first layer of convolution feature with channel-wise shifting, which is limited in balancing noise removal and detail preservation. In this paper, we present a novel flexible image enoising network (CFMNet) by equipping an U-Net backbone with multi-layer conditional feature modulation (CFM) modules. In comparison to channel-wise shifting only in the first layer, CFMNet can make better use of noise level information by deploying multiple layers of CFM. Moreover, each CFM module takes onvolutional features from both noisy image and noise level map as input for better trade-off between noise removal and detail preservation. Experimental results show that our CFMNet is effective in exploiting noise level information for flexible non-blind denoising, and performs favorably against the existing deep image denoising methods in terms of both quantitative metrics and visual quality.