 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hierarchical Implicit Flow Q-learning for Offline Goal-conditioned Reinforcement Learning
Apr 10, 2026Offline goal-conditioned reinforcement learning (GCRL) is a practical reinforcement learning paradigm that aims to learn goal-conditioned policies from reward-free offline data. Despite recent advances in hierarchical architectures such as HIQL, long-horizon control in offline GCRL remains challenging due to the limited expressiveness of Gaussian policies and the inability of high-level policies to generate effective subgoals. To address these limitations, we propose the goal-conditioned mean flow policy, which introduces an average velocity field into hierarchical policy modeling for offline GCRL. Specifically, the mean flow policy captures complex target distributions for both high-level and low-level policies through a learned average velocity field, enabling efficient action generation via one-step sampling. Furthermore, considering the insufficiency of goal representation, we introduce a LeJEPA loss that repels goal representation embeddings during training, thereby encouraging more discriminative representations and improving generalization. Experimental results show that our method achieves strong performance across both state-based and pixel-based tasks in the OGBench benchmark.
Value-Guidance MeanFlow for Offline Multi-Agent Reinforcement Learning
Apr 09, 2026Offline multi-agent reinforcement learning (MARL) aims to learn the optimal joint policy from pre-collected datasets, requiring a trade-off between maximizing global returns and mitigating distribution shift from offline data. Recent studies use diffusion or flow generative models to capture complex joint policy behaviors among agents; however, they typically rely on multi-step iterative sampling, thereby reducing training and inference efficiency. Although further research improves sampling efficiency through methods like distillation, it remains sensitive to the behavior regularization coefficient. To address the above-mentioned issues, we propose Value Guidance Multi-agent MeanFlow Policy (VGM$^2$P), a simple yet effective flow-based policy learning framework that enables efficient action generation with coefficient-insensitive conditional behavior cloning. Specifically, VGM$^2$P uses global advantage values to guide agent collaboration, treating optimal policy learning as conditional behavior cloning. Additionally, to improve policy expressiveness and inference efficiency in multi-agent scenarios, it leverages classifier-free guidance MeanFlow for both policy training and execution. Experiments on tasks with both discrete and continuous action spaces demonstrate that, even when trained solely via conditional behavior cloning, VGM$^2$P efficiently achieves performance comparable to state-of-the-art methods.
Equivariant Efficient Joint Discrete and Continuous MeanFlow for Molecular Graph Generation
Apr 09, 2026Graph-structured data jointly contain discrete topology and continuous geometry, which poses fundamental challenges for generative modeling due to heterogeneous distributions, incompatible noise dynamics, and the need for equivariant inductive biases. Existing flow-matching approaches for graph generation typically decouple structure from geometry, lack synchronized cross-domain dynamics, and rely on iterative sampling, often resulting in physically inconsistent molecular conformations and slow sampling. To address these limitations, we propose Equivariant MeanFlow (EQUIMF), a unified SE(3)-equivariant generative framework that jointly models discrete and continuous components through synchronized MeanFlow dynamics. EQUIMF introduces a unified time bridge and average-velocity updates with mutual conditioning between structure and geometry, enabling efficient few-step generation while preserving physical consistency. Moreover, we develop a novel discrete MeanFlow formulation with a simple yet effective parameterization to support efficient generation over discrete graph structures. Extensive experiments demonstrate that EQUIMF consistently outperforms prior diffusion and flow-matching methods in generation quality, physical validity, and sampling efficiency.
NIR-Assisted Image Denoising: A Selective Fusion Approach and A Real-World Benchmark Datase
Apr 12, 2024Despite the significant progress in image denoising, it is still challenging to restore fine-scale details while removing noise, especially in extremely low-light environments. Leveraging near-infrared (NIR) images to assist visible RGB image denoising shows the potential to address this issue, becoming a promising technology. Nonetheless, existing works still struggle with taking advantage of NIR information effectively for real-world image denoising, due to the content inconsistency between NIR-RGB images and the scarcity of real-world paired datasets. To alleviate the problem, we propose an efficient Selective Fusion Module (SFM), which can be plug-and-played into the advanced denoising networks to merge the deep NIR-RGB features. Specifically, we sequentially perform the global and local modulation for NIR and RGB features, and then integrate the two modulated features. Furthermore, we present a Real-world NIR-Assisted Image Denoising (Real-NAID) dataset, which covers diverse scenarios as well as various noise levels. Extensive experiments on both synthetic and our real-world datasets demonstrate that the proposed method achieves better results than state-of-the-art ones. The dataset, codes, and pre-trained models will be publicly available at https://github.com/ronjonxu/NAID.
Self-Supervised Image Restoration with Blurry and Noisy Pairs
Nov 14, 2022



When taking photos under an environment with insufficient light, the exposure time and the sensor gain usually require to be carefully chosen to obtain images with satisfying visual quality. For example, the images with high ISO usually have inescapable noise, while the long-exposure ones may be blurry due to camera shake or object motion. Existing solutions generally suggest to seek a balance between noise and blur, and learn denoising or deblurring models under either full- or self-supervision. However, the real-world training pairs are difficult to collect, and the self-supervised methods merely rely on blurry or noisy images are limited in performance. In this work, we tackle this problem by jointly leveraging the short-exposure noisy image and the long-exposure blurry image for better image restoration. Such setting is practically feasible due to that short-exposure and long-exposure images can be either acquired by two individual cameras or synthesized by a long burst of images. Moreover, the short-exposure images are hardly blurry, and the long-exposure ones have negligible noise. Their complementarity makes it feasible to learn restoration model in a self-supervised manner. Specifically, the noisy images can be used as the supervision information for deblurring, while the sharp areas in the blurry images can be utilized as the auxiliary supervision information for self-supervised denoising. By learning in a collaborative manner, the deblurring and denoising tasks in our method can benefit each other. Experiments on synthetic and real-world images show the effectiveness and practicality of the proposed method. Codes are available at https://github.com/cszhilu1998/SelfIR.
ISIC 2018-A Method for Lesion Segmentation
Jul 21, 2018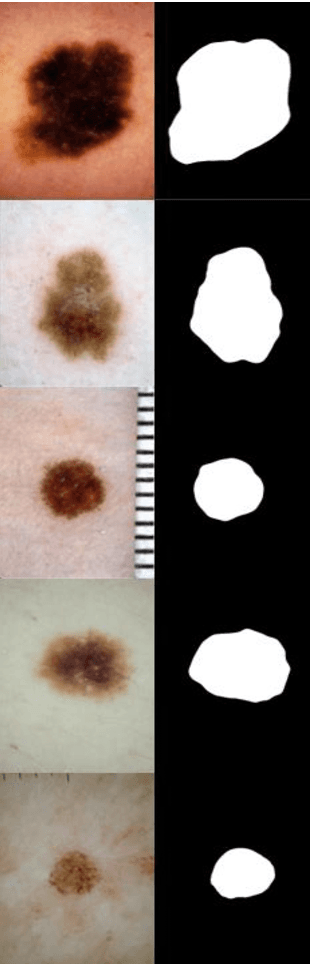

Our team participate in the challenge of Task 1: Lesion Boundary Segmentation , and use a combined network, one of which is designed by ourselves named updcnn net and another is an improved VGG 16-layer net. Updcnn net uses reduced size images for training, and VGG 16-layer net utilizes large size images. Image enhancement is used to get a richer data set. We use boxes in the VGG 16-layer net network for local attention regularization to fine-tune the loss function, which can increase the number of training data, and also make the model more robust. In the test, the model is used for joint testing and achieves good results.