 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan Then Retrieve: Reinforcement Learning-Guided Complex Reasoning over Knowledge Graphs
Oct 23, 2025



Knowledge Graph Question Answering aims to answer natural language questions by reasoning over structured knowledge graphs. While large language models have advanced KGQA through their strong reasoning capabilities, existing methods continue to struggle to fully exploit both the rich knowledge encoded in KGs and the reasoning capabilities of LLMs, particularly in complex scenarios. They often assume complete KG coverage and lack mechanisms to judge when external information is needed, and their reasoning remains locally myopic, failing to maintain coherent multi-step planning, leading to reasoning failures even when relevant knowledge exists. We propose Graph-RFT, a novel two-stage reinforcement fine-tuning KGQA framework with a 'plan-KGsearch-and-Websearch-during-think' paradigm, that enables LLMs to perform autonomous planning and adaptive retrieval scheduling across KG and web sources under incomplete knowledge conditions. Graph-RFT introduces a chain-of-thought fine-tuning method with a customized plan-retrieval dataset activates structured reasoning and resolves the GRPO cold-start problem. It then introduces a novel plan-retrieval guided reinforcement learning process integrates explicit planning and retrieval actions with a multi-reward design, enabling coverage-aware retrieval scheduling. It employs a Cartesian-inspired planning module to decompose complex questions into ordered subquestions, and logical expression to guide tool invocation for globally consistent multi-step reasoning. This reasoning retrieval process is optimized with a multi-reward combining outcome and retrieval specific signals, enabling the model to learn when and how to combine KG and web retrieval effectively.
Multi-level Matching Network for Multimodal Entity Linking
Dec 11, 2024Multimodal entity linking (MEL) aims to link ambiguous mentions within multimodal contexts to corresponding entities in a multimodal knowledge base. Most existing approaches to MEL are based on representation learning or vision-and-language pre-training mechanisms for exploring the complementary effect among multiple modalities. However, these methods suffer from two limitations. On the one hand, they overlook the possibility of considering negative samples from the same modality. On the other hand, they lack mechanisms to capture bidirectional cross-modal interaction. To address these issues, we propose a Multi-level Matching network for Multimodal Entity Linking (M3EL). Specifically, M3EL is composed of three different modules: (i) a Multimodal Feature Extraction module, which extracts modality-specific representations with a multimodal encoder and introduces an intra-modal contrastive learning sub-module to obtain better discriminative embeddings based on uni-modal differences; (ii) an Intra-modal Matching Network module, which contains two levels of matching granularity: Coarse-grained Global-to-Global and Fine-grained Global-to-Local, to achieve local and global level intra-modal interaction; (iii) a Cross-modal Matching Network module, which applies bidirectional strategies, Textual-to-Visual and Visual-to-Textual matching, to implement bidirectional cross-modal interaction. Extensive experiments conducted on WikiMEL, RichpediaMEL, and WikiDiverse datasets demonstrate the outstanding performance of M3EL when compared to the state-of-the-art baselines.
COTET: Cross-view Optimal Transport for Knowledge Graph Entity Typing
May 22, 2024Knowledge graph entity typing (KGET) aims to infer missing entity type instances in knowledge graphs. Previous research has predominantly centered around leveraging contextual information associated with entities, which provides valuable clues for inference. However, they have long ignored the dual nature of information inherent in entities, encompassing both high-level coarse-grained cluster knowledge and fine-grained type knowledge. This paper introduces Cross-view Optimal Transport for knowledge graph Entity Typing (COTET), a method that effectively incorporates the information on how types are clustered into the representation of entities and types. COTET comprises three modules: i) Multi-view Generation and Encoder, which captures structured knowledge at different levels of granularity through entity-type, entity-cluster, and type-cluster-type perspectives; ii) Cross-view Optimal Transport, transporting view-specific embeddings to a unified space by minimizing the Wasserstein distance from a distributional alignment perspective; iii) Pooling-based Entity Typing Prediction, employing a mixture pooling mechanism to aggregate prediction scores from diverse neighbors of an entity. Additionally, we introduce a distribution-based loss function to mitigate the occurrence of false negatives during training. Extensive experiments demonstrate the effectiveness of COTET when compared to existing baselines.
Leveraging Intra-modal and Inter-modal Interaction for Multi-Modal Entity Alignment
Apr 19, 2024



Multi-modal entity alignment (MMEA) aims to identify equivalent entity pairs across different multi-modal knowledge graphs (MMKGs). Existing approaches focus on how to better encode and aggregate information from different modalities. However, it is not trivial to leverage multi-modal knowledge in entity alignment due to the modal heterogeneity. In this paper, we propose a Multi-Grained Interaction framework for Multi-Modal Entity Alignment (MIMEA), which effectively realizes multi-granular interaction within the same modality or between different modalities. MIMEA is composed of four modules: i) a Multi-modal Knowledge Embedding module, which extracts modality-specific representations with multiple individual encoders; ii) a Probability-guided Modal Fusion module, which employs a probability guided approach to integrate uni-modal representations into joint-modal embeddings, while considering the interaction between uni-modal representations; iii) an Optimal Transport Modal Alignment module, which introduces an optimal transport mechanism to encourage the interaction between uni-modal and joint-modal embeddings; iv) a Modal-adaptive Contrastive Learning module, which distinguishes the embeddings of equivalent entities from those of non-equivalent ones, for each modality. Extensive experiments conducted on two real-world datasets demonstrate the strong performance of MIMEA compared to the SoTA. Datasets and code have been submitted as supplementary materials.
HyperMono: A Monotonicity-aware Approach to Hyper-Relational Knowledge Representation
Apr 15, 2024



In a hyper-relational knowledge graph (HKG), each fact is composed of a main triple associated with attribute-value qualifiers, which express additional factual knowledge. The hyper-relational knowledge graph completion (HKGC) task aims at inferring plausible missing links in a HKG. Most existing approaches to HKGC focus on enhancing the communication between qualifier pairs and main triples, while overlooking two important properties that emerge from the monotonicity of the hyper-relational graphs representation regime. Stage Reasoning allows for a two-step reasoning process, facilitating the integration of coarse-grained inference results derived solely from main triples and fine-grained inference results obtained from hyper-relational facts with qualifiers. In the initial stage, coarse-grained results provide an upper bound for correct predictions, which are subsequently refined in the fine-grained step. More generally, Qualifier Monotonicity implies that by attaching more qualifier pairs to a main triple, we may only narrow down the answer set, but never enlarge it. This paper proposes the HyperMono model for hyper-relational knowledge graph completion, which realizes stage reasoning and qualifier monotonicity. To implement qualifier monotonicity HyperMono resorts to cone embeddings. Experiments on three real-world datasets with three different scenario conditions demonstrate the strong performance of HyperMono when compared to the SoTA.
Multi-view Contrastive Learning for Entity Typing over Knowledge Graphs
Oct 18, 2023Knowledge graph entity typing (KGET) aims at inferring plausible types of entities in knowledge graphs. Existing approaches to KGET focus on how to better encode the knowledge provided by the neighbors and types of an entity into its representation. However, they ignore the semantic knowledge provided by the way in which types can be clustered together. In this paper, we propose a novel method called Multi-view Contrastive Learning for knowledge graph Entity Typing (MCLET), which effectively encodes the coarse-grained knowledge provided by clusters into entity and type embeddings. MCLET is composed of three modules: i) Multi-view Generation and Encoder module, which encodes structured information from entity-type, entity-cluster and cluster-type views; ii) Cross-view Contrastive Learning module, which encourages different views to collaboratively improve view-specific representations of entities and types; iii) Entity Typing Prediction module, which integrates multi-head attention and a Mixture-of-Experts strategy to infer missing entity types. Extensive experiments show the strong performance of MCLET compared to the state-of-the-art
MLPST: MLP is All You Need for Spatio-Temporal Prediction
Sep 23, 2023



Traffic prediction is a typical spatio-temporal data mining task and has great significance to the public transportation system. Considering the demand for its grand application, we recognize key factors for an ideal spatio-temporal prediction method: efficient, lightweight, and effective. However, the current deep model-based spatio-temporal prediction solutions generally own intricate architectures with cumbersome optimization, which can hardly meet these expectations. To accomplish the above goals, we propose an intuitive and novel framework, MLPST, a pure multi-layer perceptron architecture for traffic prediction. Specifically, we first capture spatial relationships from both local and global receptive fields. Then, temporal dependencies in different intervals are comprehensively considered. Through compact and swift MLP processing, MLPST can well capture the spatial and temporal dependencies while requiring only linear computational complexity, as well as model parameters that are more than an order of magnitude lower than baselines. Extensive experiments validated the superior effectiveness and efficiency of MLPST against advanced baselines, and among models with optimal accuracy, MLPST achieves the best time and space efficiency.
HyperFormer: Enhancing Entity and Relation Interaction for Hyper-Relational Knowledge Graph Completion
Aug 12, 2023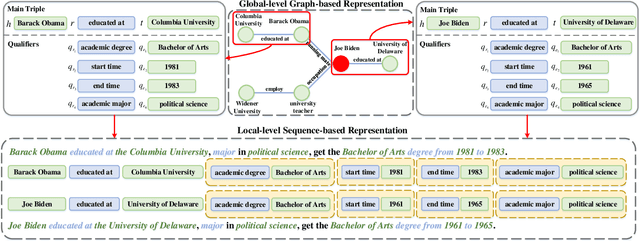
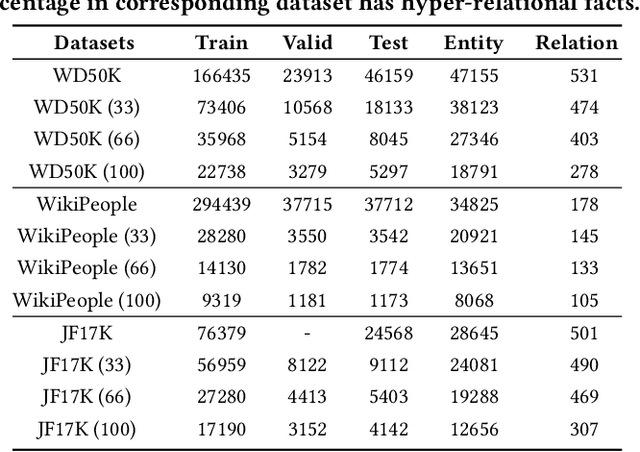
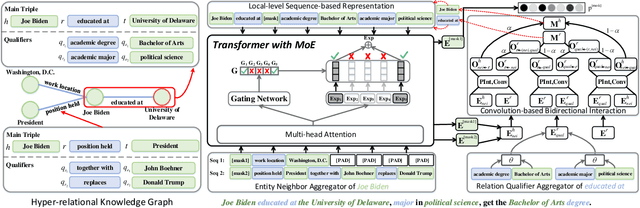
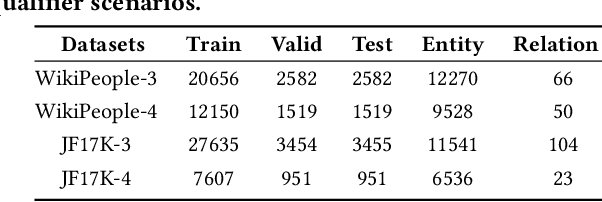
Hyper-relational knowledge graphs (HKGs) extend standard knowledge graphs by associating attribute-value qualifiers to triples, which effectively represent additional fine-grained information about its associated triple. Hyper-relational knowledge graph completion (HKGC) aims at inferring unknown triples while considering its qualifiers. Most existing approaches to HKGC exploit a global-level graph structure to encode hyper-relational knowledge into the graph convolution message passing process. However, the addition of multi-hop information might bring noise into the triple prediction process. To address this problem, we propose HyperFormer, a model that considers local-level sequential information, which encodes the content of the entities, relations and qualifiers of a triple. More precisely, HyperFormer is composed of three different modules: an entity neighbor aggregator module allowing to integrate the information of the neighbors of an entity to capture different perspectives of it; a relation qualifier aggregator module to integrate hyper-relational knowledge into the corresponding relation to refine the representation of relational content; a convolution-based bidirectional interaction module based on a convolutional operation, capturing pairwise bidirectional interactions of entity-relation, entity-qualifier, and relation-qualifier. realize the depth perception of the content related to the current statement. Furthermore, we introduce a Mixture-of-Experts strategy into the feed-forward layers of HyperFormer to strengthen its representation capabilities while reducing the amount of model parameters and computation. Extensive experiments on three well-known datasets with four different conditions demonstrate HyperFormer's effectiveness. Datasets and code are available at https://github.com/zhiweihu1103/HKGC-HyperFormer.
Position-Aware Contrastive Alignment for Referring Image Segmentation
Dec 27, 2022



Referring image segmentation aims to segment the target object described by a given natural language expression. Typically, referring expressions contain complex relationships between the target and its surrounding objects. The main challenge of this task is to understand the visual and linguistic content simultaneously and to find the referred object accurately among all instances in the image. Currently, the most effective way to solve the above problem is to obtain aligned multi-modal features by computing the correlation between visual and linguistic feature modalities under the supervision of the ground-truth mask. However, existing paradigms have difficulty in thoroughly understanding visual and linguistic content due to the inability to perceive information directly about surrounding objects that refer to the target. This prevents them from learning aligned multi-modal features, which leads to inaccurate segmentation. To address this issue, we present a position-aware contrastive alignment network (PCAN) to enhance the alignment of multi-modal features by guiding the interaction between vision and language through prior position information. Our PCAN consists of two modules: 1) Position Aware Module (PAM), which provides position information of all objects related to natural language descriptions, and 2) Contrastive Language Understanding Module (CLUM), which enhances multi-modal alignment by comparing the features of the referred object with those of related objects. Extensive experiments on three benchmarks demonstrate our PCAN performs favorably against the state-of-the-art methods. Our code will be made publicly available.
1st Place Solution for YouTubeVOS Challenge 2022: Referring Video Object Segmentation
Dec 27, 2022


The task of referring video object segmentation aims to segment the object in the frames of a given video to which the referring expressions refer. Previous methods adopt multi-stage approach and design complex pipelines to obtain promising results. Recently, the end-to-end method based on Transformer has proved its superiority. In this work, we draw on the advantages of the above methods to provide a simple and effective pipeline for RVOS. Firstly, We improve the state-of-the-art one-stage method ReferFormer to obtain mask sequences that are strongly correlated with language descriptions. Secondly, based on a reliable and high-quality keyframe, we leverage the superior performance of video object segmentation model to further enhance the quality and temporal consistency of the mask results. Our single model reaches 70.3 J &F on the Referring Youtube-VOS validation set and 63.0 on the test set. After ensemble, we achieve 64.1 on the final leaderboard, ranking 1st place on CVPR2022 Referring Youtube-VOS challenge. Code will be available at https://github.com/Zhiweihhh/cvpr2022-rvos-challenge.git.