 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
Skill Discovery for Software Scripting Automation via Offline Simulations with LLMs
Apr 29, 2025Scripting interfaces enable users to automate tasks and customize software workflows, but creating scripts traditionally requires programming expertise and familiarity with specific APIs, posing barriers for many users. While Large Language Models (LLMs) can generate code from natural language queries, runtime code generation is severely limited due to unverified code, security risks, longer response times, and higher computational costs. To bridge the gap, we propose an offline simulation framework to curate a software-specific skillset, a collection of verified scripts, by exploiting LLMs and publicly available scripting guides. Our framework comprises two components: (1) task creation, using top-down functionality guidance and bottom-up API synergy exploration to generate helpful tasks; and (2) skill generation with trials, refining and validating scripts based on execution feedback. To efficiently navigate the extensive API landscape, we introduce a Graph Neural Network (GNN)-based link prediction model to capture API synergy, enabling the generation of skills involving underutilized APIs and expanding the skillset's diversity. Experiments with Adobe Illustrator demonstrate that our framework significantly improves automation success rates, reduces response time, and saves runtime token costs compared to traditional runtime code generation. This is the first attempt to use software scripting interfaces as a testbed for LLM-based systems, highlighting the advantages of leveraging execution feedback in a controlled environment and offering valuable insights into aligning AI capabilities with user needs in specialized software domains.
CachePrune: Neural-Based Attribution Defense Against Indirect Prompt Injection Attacks
Apr 29, 2025Large Language Models (LLMs) are identified as being susceptible to indirect prompt injection attack, where the model undesirably deviates from user-provided instructions by executing tasks injected in the prompt context. This vulnerability stems from LLMs' inability to distinguish between data and instructions within a prompt. In this paper, we propose CachePrune that defends against this attack by identifying and pruning task-triggering neurons from the KV cache of the input prompt context. By pruning such neurons, we encourage the LLM to treat the text spans of input prompt context as only pure data, instead of any indicator of instruction following. These neurons are identified via feature attribution with a loss function induced from an upperbound of the Direct Preference Optimization (DPO) objective. We show that such a loss function enables effective feature attribution with only a few samples. We further improve on the quality of feature attribution, by exploiting an observed triggering effect in instruction following. Our approach does not impose any formatting on the original prompt or introduce extra test-time LLM calls. Experiments show that CachePrune significantly reduces attack success rates without compromising the response quality. Note: This paper aims to defend against indirect prompt injection attacks, with the goal of developing more secure and robust AI systems.
A Survey of Foundation Model-Powered Recommender Systems: From Feature-Based, Generative to Agentic Paradigms
Apr 23, 2025



Recommender systems (RS) have become essential in filtering information and personalizing content for users. RS techniques have traditionally relied on modeling interactions between users and items as well as the features of content using models specific to each task. The emergence of foundation models (FMs), large scale models trained on vast amounts of data such as GPT, LLaMA and CLIP, is reshaping the recommendation paradigm. This survey provides a comprehensive overview of the Foundation Models for Recommender Systems (FM4RecSys), covering their integration in three paradigms: (1) Feature-Based augmentation of representations, (2) Generative recommendation approaches, and (3) Agentic interactive systems. We first review the data foundations of RS, from traditional explicit or implicit feedback to multimodal content sources. We then introduce FMs and their capabilities for representation learning, natural language understanding, and multi-modal reasoning in RS contexts. The core of the survey discusses how FMs enhance RS under different paradigms. Afterward, we examine FM applications in various recommendation tasks. Through an analysis of recent research, we highlight key opportunities that have been realized as well as challenges encountered. Finally, we outline open research directions and technical challenges for next-generation FM4RecSys. This survey not only reviews the state-of-the-art methods but also provides a critical analysis of the trade-offs among the feature-based, the generative, and the agentic paradigms, outlining key open issues and future research directions.
In-context Ranking Preference Optimization
Apr 21, 2025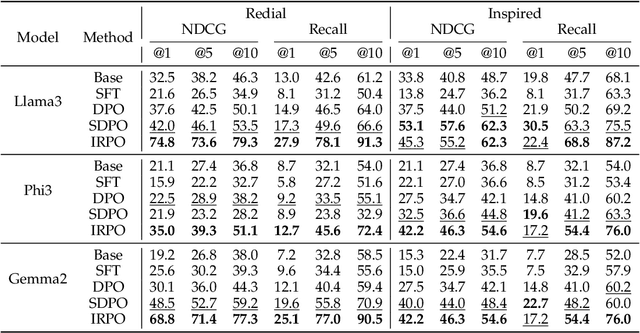
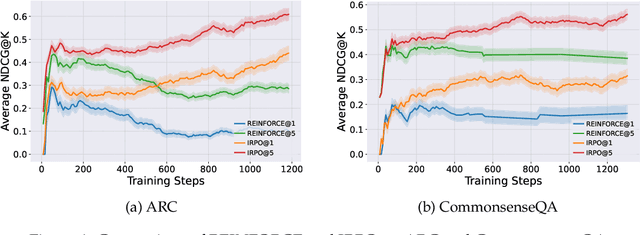
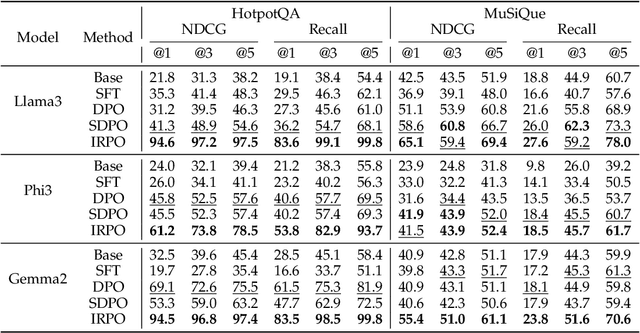
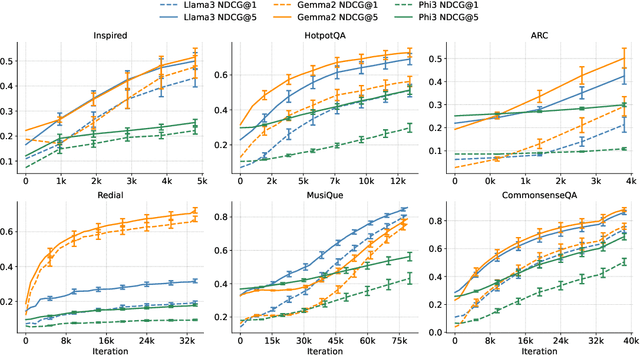
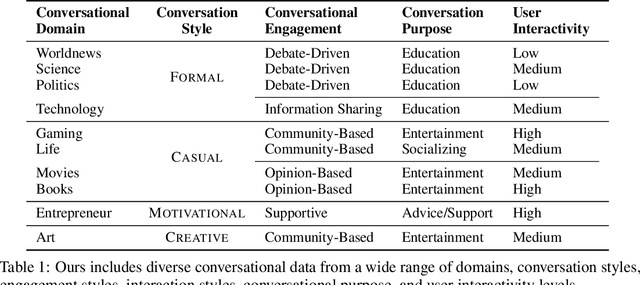
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.
WaterFlow: Learning Fast & Robust Watermarks using Stable Diffusion
Apr 18, 2025The ability to embed watermarks in images is a fundamental problem of interest for computer vision, and is exacerbated by the rapid rise of generated imagery in recent times. Current state-of-the-art techniques suffer from computational and statistical challenges such as the slow execution speed for practical deployments. In addition, other works trade off fast watermarking speeds but suffer greatly in their robustness or perceptual quality. In this work, we propose WaterFlow (WF), a fast and extremely robust approach for high fidelity visual watermarking based on a learned latent-dependent watermark. Our approach utilizes a pretrained latent diffusion model to encode an arbitrary image into a latent space and produces a learned watermark that is then planted into the Fourier Domain of the latent. The transformation is specified via invertible flow layers that enhance the expressivity of the latent space of the pre-trained model to better preserve image quality while permitting robust and tractable detection. Most notably, WaterFlow demonstrates state-of-the-art performance on general robustness and is the first method capable of effectively defending against difficult combination attacks. We validate our findings on three widely used real and generated datasets: MS-COCO, DiffusionDB, and WikiArt.
Get the Agents Drunk: Memory Perturbations in Autonomous Agent-based Recommender Systems
Mar 31, 2025Large language model-based agents are increasingly used in recommender systems (Agent4RSs) to achieve personalized behavior modeling. Specifically, Agent4RSs introduces memory mechanisms that enable the agents to autonomously learn and self-evolve from real-world interactions. However, to the best of our knowledge, how robust Agent4RSs are remains unexplored. As such, in this paper, we propose the first work to attack Agent4RSs by perturbing agents' memories, not only to uncover their limitations but also to enhance their security and robustness, ensuring the development of safer and more reliable AI agents. Given the security and privacy concerns, it is more practical to launch attacks under a black-box setting, where the accurate knowledge of the victim models cannot be easily obtained. Moreover, the practical attacks are often stealthy to maximize the impact. To this end, we propose a novel practical attack framework named DrunkAgent. DrunkAgent consists of a generation module, a strategy module, and a surrogate module. The generation module aims to produce effective and coherent adversarial textual triggers, which can be used to achieve attack objectives such as promoting the target items. The strategy module is designed to `get the target agents drunk' so that their memories cannot be effectively updated during the interaction process. As such, the triggers can play the best role. Both of the modules are optimized on the surrogate module to improve the transferability and imperceptibility of the attacks. By identifying and analyzing the vulnerabilities, our work provides critical insights that pave the way for building safer and more resilient Agent4RSs. Extensive experiments across various real-world datasets demonstrate the effectiveness of DrunkAgent.
Towards Agentic Recommender Systems in the Era of Multimodal Large Language Models
Mar 20, 2025Recent breakthroughs in Large Language Models (LLMs) have led to the emergence of agentic AI systems that extend beyond the capabilities of standalone models. By empowering LLMs to perceive external environments, integrate multimodal information, and interact with various tools, these agentic systems exhibit greater autonomy and adaptability across complex tasks. This evolution brings new opportunities to recommender systems (RS): LLM-based Agentic RS (LLM-ARS) can offer more interactive, context-aware, and proactive recommendations, potentially reshaping the user experience and broadening the application scope of RS. Despite promising early results, fundamental challenges remain, including how to effectively incorporate external knowledge, balance autonomy with controllability, and evaluate performance in dynamic, multimodal settings. In this perspective paper, we first present a systematic analysis of LLM-ARS: (1) clarifying core concepts and architectures; (2) highlighting how agentic capabilities -- such as planning, memory, and multimodal reasoning -- can enhance recommendation quality; and (3) outlining key research questions in areas such as safety, efficiency, and lifelong personalization. We also discuss open problems and future directions, arguing that LLM-ARS will drive the next wave of RS innovation. Ultimately, we foresee a paradigm shift toward intelligent, autonomous, and collaborative recommendation experiences that more closely align with users' evolving needs and complex decision-making processes.
Benchmarking Reasoning Robustness in Large Language Models
Mar 06, 2025Despite the recent success of large language models (LLMs) in reasoning such as DeepSeek, we for the first time identify a key dilemma in reasoning robustness and generalization: significant performance degradation on novel or incomplete data, suggesting a reliance on memorized patterns rather than systematic reasoning. Our closer examination reveals four key unique limitations underlying this issue:(1) Positional bias--models favor earlier queries in multi-query inputs but answering the wrong one in the latter (e.g., GPT-4o's accuracy drops from 75.8 percent to 72.8 percent); (2) Instruction sensitivity--performance declines by 5.0 to 7.5 percent in the Qwen2.5 Series and by 5.0 percent in DeepSeek-V3 with auxiliary guidance; (3) Numerical fragility--value substitution sharply reduces accuracy (e.g., GPT-4o drops from 97.5 percent to 82.5 percent, GPT-o1-mini drops from 97.5 percent to 92.5 percent); and (4) Memory dependence--models resort to guesswork when missing critical data. These findings further highlight the reliance on heuristic recall over rigorous logical inference, demonstrating challenges in reasoning robustness. To comprehensively investigate these robustness challenges, this paper introduces a novel benchmark, termed as Math-RoB, that exploits hallucinations triggered by missing information to expose reasoning gaps. This is achieved by an instruction-based approach to generate diverse datasets that closely resemble training distributions, facilitating a holistic robustness assessment and advancing the development of more robust reasoning frameworks. Bad character(s) in field Abstract.
Active Learning for Direct Preference Optimization
Mar 03, 2025Direct preference optimization (DPO) is a form of reinforcement learning from human feedback (RLHF) where the policy is learned directly from preferential feedback. Although many models of human preferences exist, the critical task of selecting the most informative feedback for training them is under-explored. We propose an active learning framework for DPO, which can be applied to collect human feedback online or to choose the most informative subset of already collected feedback offline. We propose efficient algorithms for both settings. The key idea is to linearize the DPO objective at the last layer of the neural network representation of the optimized policy and then compute the D-optimal design to collect preferential feedback. We prove that the errors in our DPO logit estimates diminish with more feedback. We show the effectiveness of our algorithms empirically in the setting that matches our theory and also on large language models.